Carnegie Mellon University의 연구팀은 최근 단안 비디오에서 인체의 시간 일관성 있고 상세한 3D 모델을 재구성할 수 있는 획기적인 기술인 DressRecon을 출시했습니다. DressRecon은 꽉 끼는 옷을 입거나 멀티뷰 데이터가 필요한 기존 인체 재구성 방법과 달리 헐렁한 옷을 입고 있거나 물건을 들고 있는 장면까지 처리할 수 있어 응용 범위가 크게 확대되고 가상 이미지 생성, 애니메이션 제작 등 분야에 혁신을 가져올 수 있습니다. Downcodes의 편집자는 이 인상적인 기술에 대한 심층적인 이해를 제공할 것입니다.
최근 카네기 멜론 대학교 연구팀은 단안 영상에서 시간 일관성이 있는 인간 모델을 재구성하는 것을 목표로 하는 "DressRecon"이라는 새로운 기술을 출시했습니다. DressRecon의 가장 큰 장점은 3D 모델을 구축하기 위해 비디오를 입력할 수 있을 뿐만 아니라 복잡한 의류 및 휴대용 품목과 같은 미세한 디테일도 복원할 수 있다는 것입니다.
이 기술은 헐렁한 옷을 입거나 손에 들고 있는 물체와 상호 작용하는 시나리오에 특히 적합하여 이전 기술의 한계를 뛰어 넘었습니다. 과거에는 인체를 재구성하려면 몸에 꼭 맞는 옷을 입거나 데이터를 캡처하기 위해 다중 뷰 보정이 필요하거나 심지어 개인화된 스캐닝이 필요했기 때문에 대규모 수집이 어려웠습니다.
'DressRecon'의 혁신은 인체 형태에 대한 일반적인 사전 지식과 영상별 신체 변형을 결합하여 영상 내에서 최적화할 수 있다는 점입니다.
이 기술의 핵심은 신체와 의복의 변형을 별도로 처리할 수 있는 신경 암시적 모델을 학습하고 모션 모델 레이어를 별도로 구축하는 것입니다.
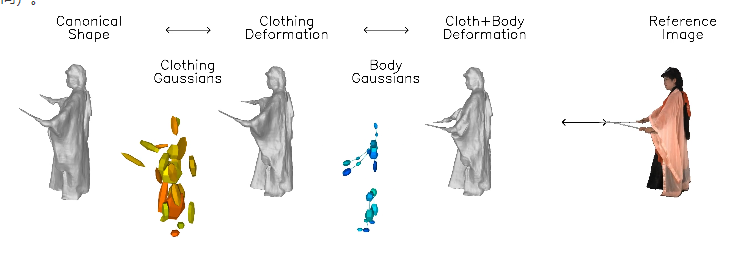
연구팀은 의복의 미묘한 기하학적 특징을 포착하기 위해 인간의 자세, 표면 법선, 광학 흐름 등 이미지 기반의 사전 지식을 활용했습니다. 이 정보는 최적화 프로세스 중에 추가 지원을 제공하여 재구성 효과를 더욱 현실적으로 만듭니다.

DressRecon은 단일 비디오 입력에서 충실도가 높은 3D 모델을 추출할 수 있으며 명시적 3D 가우시안으로 더욱 최적화하여 렌더링 품질을 향상하고 대화형 시각화를 지원할 수도 있습니다.
연구원들은 DressRecon이 일부 까다로운 의류 변형 및 개체 상호 작용 데이터 세트에서 달성할 수 있는 충실도 높은 3D 재구성 효과를 시연했습니다.
또한 재구성된 가상 인간 이미지는 어떤 각도에서도 렌더링될 수 있어 시각적으로 매우 효과적인 효과를 보여줍니다. 또한 팀은 형상 재구성에서 DressRecon의 성능을 여러 기본 기술과 비교한 결과 DressRecon이 복잡한 변형 구조를 처리할 때 더 높은 충실도를 보인 것으로 나타났습니다.
프로젝트 입구: https://jefftan969.github.io/dressrecon/
가장 밝은 부분:
? 연구팀은 단안 비디오를 통해 고품질 인체 재구성을 달성하기 위해 DressRecon 기술을 출시했습니다. 특히 헐렁한 옷과 손에 들고 있는 물체가 있는 장면에 적합합니다.
? 신경 암시적 모델을 활용하는 이 기술은 신체와 의복 변형을 별도로 처리하고 이미지 기반에 대한 사전 지식의 도움을 받아 미묘한 기하학적 특징을 포착합니다.
? 재구성 결과는 충실도가 높은 3차원 모델을 생성할 수 있을 뿐만 아니라 모든 각도에서 렌더링을 지원하여 시각화 경험을 향상시킵니다.
DressRecon 기술의 출현은 의심할 여지 없이 3D 인체 모델링 기술의 발전을 큰 진전으로 촉진할 것입니다. 효율적이고 편리한 기능과 복잡한 장면에 대한 탁월한 처리 능력은 가상 현실, 애니메이션 제작, 게임 개발 및 기타 분야의 미래에 무한한 가능성을 제공합니다. 우리는 이 기술이 더 많은 응용 시나리오에서 큰 잠재력을 실현할 수 있기를 기대합니다!