Apple은 다중 모드 인공 지능 모델 MM1~MM1.5의 주요 업그레이드를 출시했습니다. 이번 업그레이드는 단순한 버전 반복이 아니라 모델 기능을 전반적으로 개선하여 이미지 이해, 텍스트 인식 및 시각적 명령 실행 성능을 크게 향상시켰습니다. Downcodes의 편집자는 MM1.5의 개선 사항과 다중 모드 인공 지능 분야에서의 중요성을 자세히 설명합니다.
Apple은 최근 다중 모드 인공 지능 모델 MM1에 대한 주요 업데이트를 출시하여 버전 MM1.5로 업그레이드했습니다. 이번 업그레이드는 단순한 버전 번호 변경이 아닌, 종합적인 성능 향상으로 모델이 다양한 분야에서 더욱 강력한 성능을 발휘할 수 있도록 해준다.
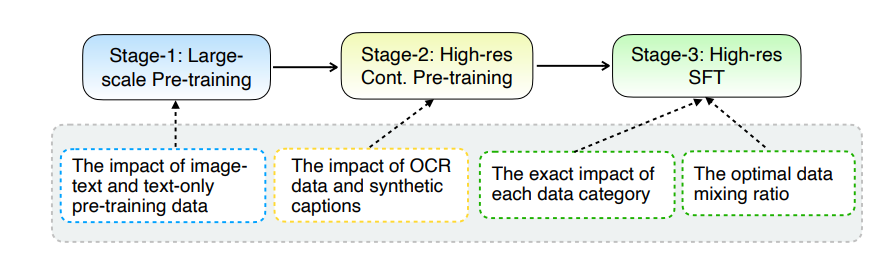
MM1.5의 핵심 업그레이드는 혁신적인 데이터 처리 방법에 있습니다. 모델은 데이터 중심 교육 접근 방식을 채택하고 교육 데이터 세트는 신중하게 선별되고 최적화됩니다. 특히 MM1.5는 고화질 OCR 데이터와 합성 이미지 설명은 물론 최적화된 시각적 지침을 사용하여 데이터 혼합을 미세 조정합니다. 이러한 데이터의 도입으로 텍스트 인식, 이미지 이해 및 시각적 지침 실행 분야에서 모델의 성능이 크게 향상되었습니다.

모델 크기 측면에서 MM1.5는 집중형 및 전문가 혼합(MoE) 변형을 포함하여 10억 ~ 300억 개의 매개변수 범위에 이르는 다양한 버전을 포괄합니다. 심지어 더 작은 규모의 10억 및 30억 매개변수 모델도 신중하게 설계된 데이터 및 훈련 전략을 통해 인상적인 성능 수준을 달성할 수 있다는 점은 주목할 가치가 있습니다.
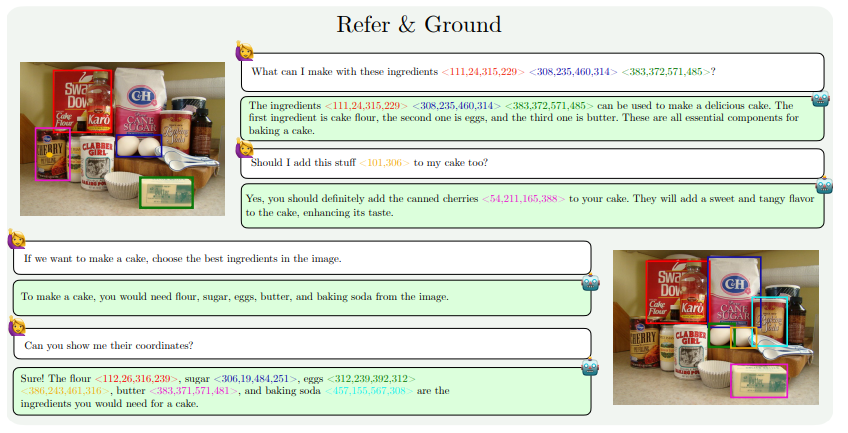
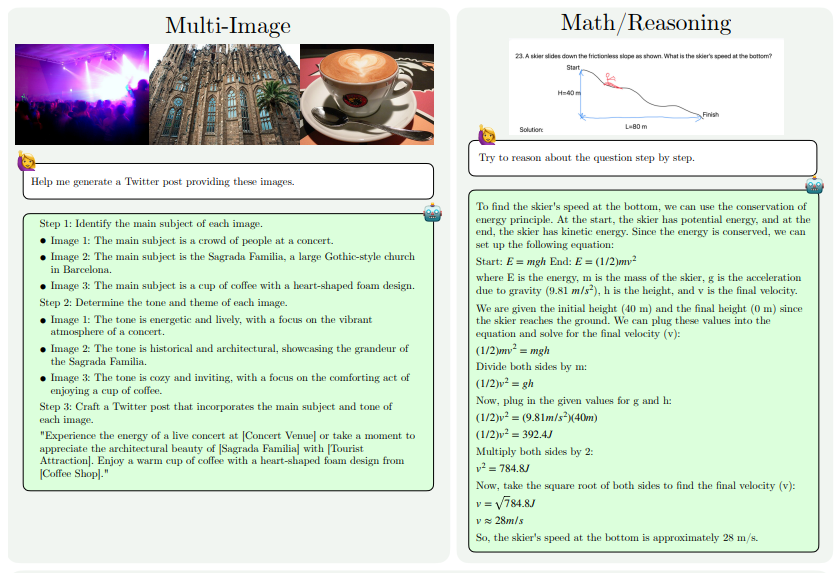
MM1.5의 기능 향상은 주로 텍스트 중심 이미지 이해, 시각적 참조 및 위치 지정, 다중 이미지 추론, 비디오 이해 및 모바일 UI 이해 측면에 반영됩니다. 이러한 기능을 통해 MM1.5는 콘서트 사진에서 연주자와 악기를 식별하고, 차트 데이터를 이해하고 관련 질문에 답하고, 복잡한 장면에서 특정 개체를 찾는 등 광범위한 시나리오에 적용할 수 있습니다.
연구진은 MM1.5의 성능을 평가하기 위해 이를 다른 고급 다중 모드 모델과 비교했습니다. 결과는 MM1.5-1B가 10억 개의 매개변수 규모를 가진 모델에서 우수한 성능을 발휘한다는 것을 보여 주며, 이는 동일한 수준의 다른 모델보다 훨씬 뛰어납니다. MM1.5-3B는 MiniCPM-V2.0보다 성능이 뛰어나며 InternVL2 및 Phi-3-Vision과 동등합니다. 또한, 연구에서는 밀집 모델이든 MoE 모델이든 규모가 커질수록 성능이 크게 향상된다는 사실도 발견했습니다.
MM1.5의 성공은 인공 지능 분야에서 Apple의 연구 개발 역량을 반영할 뿐만 아니라 다중 모드 모델의 향후 개발 방향을 제시합니다. 데이터 처리 방법과 모델 아키텍처를 최적화함으로써 소규모 모델이라도 강력한 성능을 달성할 수 있으며, 이는 리소스가 제한된 장치에 고성능 AI 모델을 배포하는 데 매우 중요합니다.
논문 주소: https://arxiv.org/pdf/2409.20566
전체적으로 MM1.5의 출시는 다중 모드 인공 지능 기술의 중요한 발전을 의미합니다. 데이터 처리 및 모델 아키텍처의 혁신은 미래 AI 모델 개발을 위한 새로운 아이디어와 방향을 제공합니다. 우리는 Apple이 인공 지능 분야에서 더욱 획기적인 결과를 계속해서 가져오기를 기대합니다.