다운코드 편집자는 OCR 기술 분야의 주요 혁신에 대해 배울 수 있도록 안내합니다! 연구원들은 최근 "OCR2.0"으로 알려진 GOT(일반 OCR 이론)라는 OCR 모델을 개발했습니다. 이는 전통적인 OCR 시스템과 대규모 언어 모델의 장점을 교묘하게 결합하여 텍스트 인식 기능에서 상당한 성과를 거두었습니다. . GOT 모델은 정교한 아키텍처, 강력한 이미지 인코더 및 디코더를 갖추고 있으며 다양한 유형의 시각적 정보를 처리할 수 있습니다.
최근 연구자들은 GOT(General OCR Theory)라는 새로운 범용 광학 문자 인식(OCR) 모델을 개발했습니다. 그들의 논문에서 "OCR2.0"이라는 개념이 처음 제안되었습니다. 이 새로운 모델은 전통적인 OCR 시스템의 장점과 대규모 언어 모델의 성능을 결합하는 것을 목표로 합니다.
GOT의 아키텍처는 약 8천만 개의 매개변수를 가진 이미지 인코더와 500만 개의 매개변수를 가진 디코더를 포함하여 상당히 발전했습니다. 이미지 인코더는 1024x1024 픽셀 이미지를 토큰으로 압축하고, 디코더는 이러한 토큰을 최대 8000자의 텍스트로 변환하는 역할을 합니다. 이러한 방식으로 OCR2.0 모델은 단순한 텍스트 이상의 것을 처리할 수 있습니다.
이 신기술의 장점은 영어와 중국어로 된 장면 텍스트와 문서 텍스트, 수학 및 화학 공식, 음악 기호, 간단한 기하학적 도형, 구성요소가 포함된 다이어그램 등 다양한 유형의 시각적 정보를 인식하고 변환하는 능력 에 있습니다. 이러한 기능은 의심할 여지없이 과학, 음악, 데이터 분석과 같은 분야의 자동화된 처리에 대한 새로운 가능성을 제공합니다.
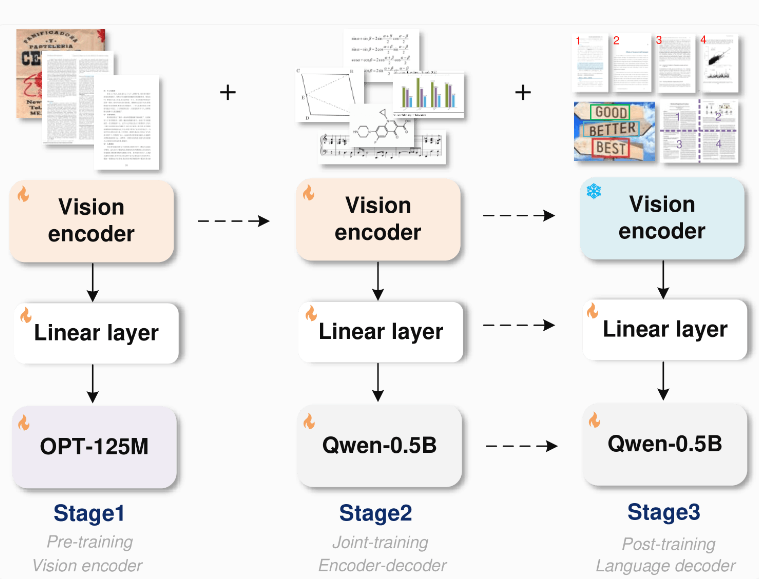
연구팀은 학습 과정을 최적화하기 위해 먼저 텍스트 인식 작업에 대해서만 인코더를 학습시킨 후 디코더로 Alibaba의 Qwen-0.5B를 도입하고 다양한 합성 데이터를 사용하여 모델을 미세 조정했습니다. 그들은 LaTeX, Mathpix-markdown-it, TikZ, Verovio, Matplotlib 및 Pyecharts와 같은 렌더링 도구를 사용하여 수백만 개의 이미지와 텍스트 쌍으로 구성된 교육 데이터를 생성했습니다.

GOT의 모듈식 설계를 통해 향후 전체 모델을 재교육하지 않고도 새로운 기능을 유연하게 확장할 수 있습니다. 이 설계는 시스템의 업데이트 효율성을 크게 향상시킵니다. 또한 연구원들은 GOT가 다양한 OCR 작업, 특히 문서 및 장면 텍스트 인식에서 우수한 성능을 발휘하며 차트 인식에서는 일부 특수 목적 모델 및 대규모 언어 모델을 능가한다고 밝혔습니다.

연구팀이 다른 사람들이 사용하고 추가로 개발할 수 있도록 Hugging Face에 GOT의 무료 데모와 코드를 공개했다는 점은 언급할 가치가 있습니다. 이 새로운 모델은 의심할 여지 없이 OCR 기술의 발전을 촉진하고 더 넓은 응용 가능성을 열어줄 것입니다.
데모 입구: https://huggingface.co/spaces/stepfun-ai/GOT_official_online_demo
가장 밝은 부분:
? GOT(General OCR Theory)는 기존 OCR 시스템과 OCR2.0이라는 대규모 언어 모델을 결합한 새로운 OCR 모델입니다.
? 이 모델은 텍스트, 수식, 음악 기호, 차트 등 다양한 시각적 정보를 인식하고 변환할 수 있으며 광범위한 분야에 적용 가능합니다.
? 모듈식 설계 및 합성 데이터 교육은 GOT에게 다양한 OCR 작업에서 유연한 확장 기능과 뛰어난 성능을 제공합니다.
GOT 모델의 오픈 소스 릴리스는 의심할 여지 없이 OCR 기술의 혁신을 가속화하고 모든 계층에 더욱 스마트하고 효율적인 텍스트 인식 솔루션을 제공할 것입니다. GOT가 향후 애플리케이션에서 더 큰 잠재력을 보여주기를 기대합니다!