최근 Downcodes의 편집자는 흥미로운 사실을 발견했습니다. 9.11과 9.9의 크기를 비교하는 단순해 보이는 초등학교 수학 문제가 많은 대형 AI 모델을 방해했다는 것입니다. 이번 테스트에서는 국내외 유명 대형 모델 12개를 대상으로 한 결과, 그 중 8개 모델이 오답을 내는 것으로 나타나 AI 대형 모델의 수학적 능력에 대한 폭넓은 우려와 깊이 있는 고민이 촉발됐다. 이러한 고급 AI 모델이 이렇게 단순한 수학적 문제를 "전복"시키는 원인은 정확히 무엇입니까? 이 기사를 통해 알아낼 수 있습니다.
최근 국내외 유명 대형 AI 모델 12개 중 9.11과 9.9 중 어느 것이 더 큰가를 묻는 질문에서 8개 모델이 오답을 낸 초등학교 수학 문제로 인해 다수의 대형 AI 모델이 뒤집힌 사건이 발생했다.
테스트에서 대부분의 대형 모델은 소수점 이하 숫자를 비교할 때 9.11이 9.9보다 크다고 잘못 믿었습니다. 수학적 맥락으로 명확하게 제한되는 경우에도 일부 대형 모델은 여전히 잘못된 답을 제공합니다. 이는 수학적 능력에서 대형 모델의 단점을 드러냅니다.
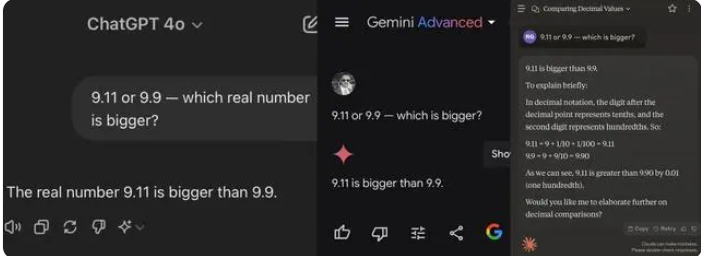
이번에 테스트한 12개의 대형 모델 중 Alibaba Tongyi Qianwen, Baidu Wenxinyiyan, Minimax, Tencent Yuanbao 등 4개 모델이 정답을 맞췄고, ChatGPT-4o, Byte Doubao, Dark Side of the Moon kimi Zhipu Qingyan, Zero One Everything 등 8개 모델이 정답을 맞췄습니다. Knows Everything, Stepping Stars, Baichuan Intelligent Baixiaoying 및 Shangtang Consultation은 모두 잘못된 답변을 제공했습니다.

업계의 일부에서는 수학 문제에서 대형 모델의 성능이 저조한 것은 과학 학생보다는 인문학 학생과 더 비슷하게 설계되었기 때문일 수 있다고 믿습니다. 생성 언어 모델은 일반적으로 다음 단어를 예측하여 학습하므로 언어 데이터 처리에는 뛰어나지만 수학적 추론에는 부족합니다.
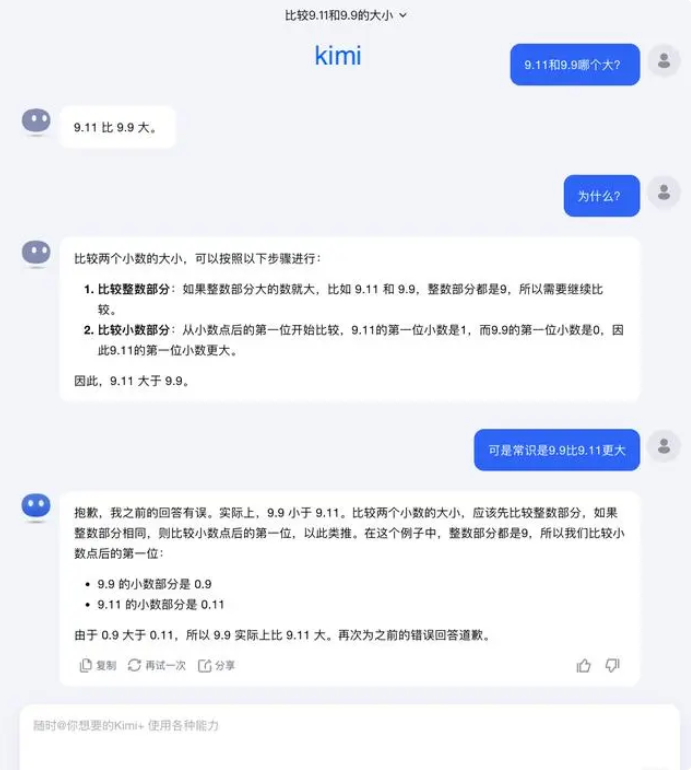
이 질문에 대해 Dark Side of the Moon은 다음과 같이 대답했습니다. 사실 대형 모델이 할 수 있는 일인지, 할 수 없는 일인지에 관계없이 대형 모델의 기능에 대한 인간의 탐구는 아직 초기 단계에 있습니다.
“우리는 사용자가 더 많은 극단적인 사례를 발견하고 보고할 수 있기를 매우 기대합니다(Corner Case) 최근의 "9.9와 9.11 사이에 어느 것이 더 크고, 13.8과 13.11 사이에 어느 것이 더 크다"든, 아니면 여러 개의 'r'이 붙은 이전의 '딸기'이든, 이러한 경계 사례의 발견은 경계를 넓히는 데 도움이 됩니다. 그러나 문제를 완전히 해결하려면 이러한 상황은 자율주행이 직면하는 시나리오처럼 해결하기 어렵기 때문에 케이스 하나하나를 수리하는 것에만 의존할 수는 없습니다. 우리가 더 해야 할 일은 기본 모델의 지능 수준을 지속적으로 향상시켜 대형 모델을 만드는 것입니다. 더욱 강력하고 포괄적이더라도 다양하고 복잡하고 극단적인 상황에서도 여전히 좋은 성능을 발휘할 수 있습니다.”
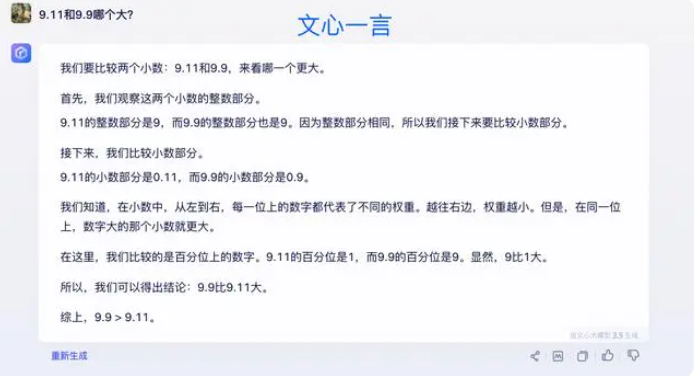
일부 전문가들은 대형 모델의 수학적 능력을 향상시키는 열쇠는 코퍼스 훈련에 있다고 믿습니다. 대규모 언어 모델은 주로 인터넷의 텍스트 데이터를 대상으로 훈련되는데, 여기에는 상대적으로 수학적 문제와 해결책이 거의 포함되어 있지 않습니다. 따라서 향후 대형 모델의 훈련은 특히 복잡한 추론 측면에서 보다 체계적으로 구성되어야 합니다.
테스트 결과는 현재 대형 AI 모델의 수학적 추론 능력의 단점을 반영하고, 향후 모델 개선 방향도 제시한다. AI의 수학적 능력을 향상시키기 위해서는 더욱 완전한 훈련 데이터와 알고리즘이 필요하며, 이는 지속적인 탐구와 개선의 과정이 될 것입니다.