최근 몇 년 동안 인공지능이 이미지 인식 분야에서 상당한 발전을 이루었지만, 비디오를 이해하는 것은 여전히 큰 과제로 남아 있습니다. 비디오 데이터의 역동성과 복잡성은 AI에 전례 없는 어려움을 가져옵니다. 하지만 구글 연구팀이 개발한 VideoPrism 영상인코더가 이런 상황을 바꿀 것으로 예상된다. Downcodes의 편집자는 VideoPrism의 강력한 기능, 교육 방법 및 AI 비디오 이해의 미래 분야에 대한 심오한 영향에 대한 심층적인 이해를 제공할 것입니다.
AI의 세계에서는 기계가 그림을 이해하는 것보다 영상을 이해하는 것이 훨씬 더 어렵습니다. 영상은 소리, 움직임, 복잡한 장면들로 가득 차 있어 역동적입니다. 예전에는 AI가 있어서 영상을 보는 것이 마치 천국에서 책을 읽는 것 같아서 혼란스러울 때가 많았습니다.
하지만 VideoPrism의 등장으로 모든 것이 바뀔 수도 있습니다. Google 연구팀이 개발한 비디오 인코더로 다양한 영상 이해 작업에 대해 단일 모델로 최고 수준에 도달할 수 있습니다. 비디오 분류, 위치 지정, 자막 생성, 심지어 비디오에 대한 질문에 대한 답변까지 VideoPrism은 쉽게 처리할 수 있습니다.

VideoPrism을 훈련하는 방법은 무엇입니까?
VideoPrism을 훈련하는 과정은 아이에게 세상을 관찰하는 방법을 가르치는 것과 같습니다. 첫째, 일상생활부터 과학적 관찰까지 다양한 영상을 보여줘야 합니다. 그런 다음 "고품질" 비디오-자막 쌍과 일부 시끄러운 병렬 텍스트(예: 자동 음성 인식 텍스트)를 사용하여 훈련합니다.
사전 훈련 방법
데이터: VideoPrism은 3,600만 개의 고품질 비디오-자막 쌍과 시끄러운 병렬 텍스트가 포함된 5,820만 개의 비디오 클립을 사용합니다.
모델 아키텍처: 표준 시각적 변환기(ViT)를 기반으로 공간과 시간에서 인수분해 설계를 사용합니다.
훈련 알고리즘: 비디오-텍스트 비교 훈련과 마스크된 비디오 모델링의 두 단계를 포함합니다.
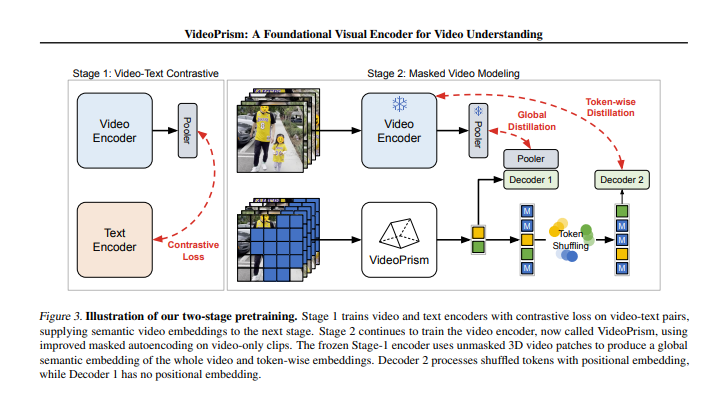
훈련 과정에서 VideoPrism은 두 단계를 거칩니다. 첫 번째 단계에서는 대조 학습과 글로벌-로컬 증류를 통해 비디오와 텍스트의 연결을 학습합니다. 두 번째 단계에서는 마스킹된 비디오 모델링을 통해 비디오 콘텐츠에 대한 이해도를 더욱 향상시킵니다.
연구원들은 여러 비디오 이해 작업에서 VideoPrism을 테스트했으며 그 결과는 인상적이었습니다. VideoPrism은 33개 벤치마크 중 30개에서 최첨단 성능을 달성했습니다. 온라인 비디오 질문에 대한 답변이든 과학 분야의 컴퓨터 비전 작업이든 VideoPrism은 강력한 기능을 보여주었습니다.
VideoPrism의 탄생은 AI 영상 이해 분야에 새로운 가능성을 가져왔습니다. AI가 비디오 콘텐츠를 더 잘 이해하는 데 도움이 될 수 있을 뿐만 아니라 교육, 엔터테인먼트, 보안 및 기타 분야에서도 중요한 역할을 할 수 있습니다.
그러나 VideoPrism은 긴 비디오를 처리하는 방법, 훈련 과정에서 편견을 피하는 방법과 같은 몇 가지 과제에 직면해 있습니다. 이는 향후 연구에서 해결해야 할 문제이다.
논문 주소: https://arxiv.org/pdf/2402.13217
전체적으로 VideoPrism의 출현은 AI 비디오 이해 분야에서 큰 진전을 이루었습니다. 그 강력한 성능과 폭넓은 적용 가능성은 흥미롭습니다. 앞으로도 지속적인 기술 발전으로 VideoPrism은 더 많은 분야에서 그 가치를 발휘하고 사람들의 삶에 더 많은 편리함을 가져다 줄 것이라고 믿습니다.