Downcodes의 편집자는 Groq가 최근 처리 속도가 업계 기대치를 훨씬 뛰어넘어 개발자에게 전례 없는 대규모 언어 모델 대화형 경험을 제공하는 놀라운 LLM 엔진을 출시했다는 사실을 알게 되었습니다. 이 엔진은 Meta의 오픈 소스 LLama3-8b-8192LLM을 기반으로 하며 다른 모델을 지원합니다. 처리 속도는 초당 1256.54마크로 Nvidia와 같은 회사의 GPU 칩보다 훨씬 빠릅니다. 이 획기적인 개발은 개발자들로부터 광범위한 관심을 끌었을 뿐만 아니라 일반 사용자에게 더 빠르고 유연한 LLM 응용 프로그램 경험을 제공했습니다.
Groq는 최근 웹사이트에 매우 빠른 LLM 엔진을 출시하여 개발자가 대규모 언어 모델에서 빠른 쿼리와 작업 실행을 직접 수행할 수 있도록 했습니다.
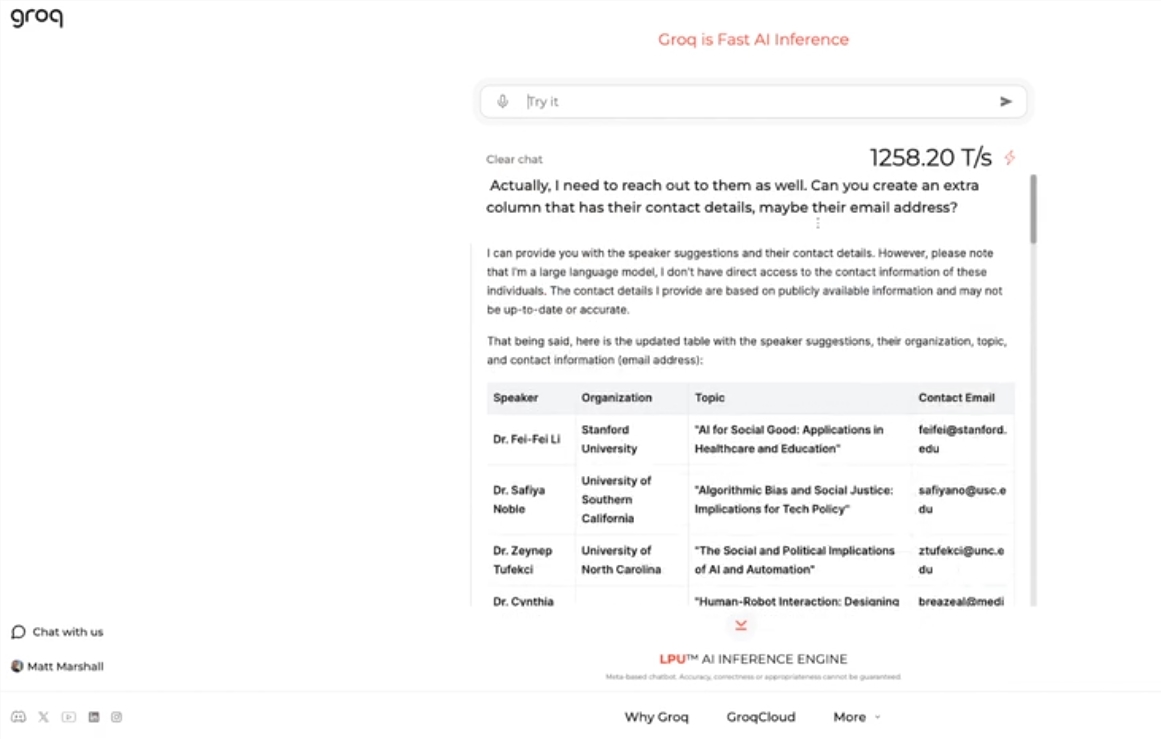
이 엔진은 Meta의 오픈 소스 LLama3-8b-8192LLM을 사용하고 기본적으로 다른 모델을 지원하며 놀라울 정도로 빠릅니다. 테스트 결과에 따르면 Groq의 엔진은 Nvidia와 같은 회사의 GPU 칩을 훨씬 능가하는 초당 1256.54 마크를 처리할 수 있습니다. 이러한 움직임은 개발자와 비개발자 모두로부터 광범위한 관심을 끌었으며 LLM 챗봇의 속도와 유연성을 입증했습니다.
Groq CEO Jonathan Ross는 사람들이 Groq의 빠른 엔진에서 LLM을 사용하는 것이 얼마나 쉬운지 알게 되면 LLM의 사용이 더욱 늘어날 것이라고 말했습니다. 시연을 통해 구인 광고 생성, 기사 내용 수정 등 다양한 작업을 이 속도로 쉽게 완료할 수 있음을 확인할 수 있다. Groq의 엔진은 음성 명령을 기반으로 쿼리를 수행할 수도 있어 그 성능과 사용자 친화성을 입증합니다.
무료 LLM 워크로드 서비스를 제공하는 것 외에도 Groq는 개발자에게 OpenAI 기반 애플리케이션을 Groq로 쉽게 전환할 수 있는 콘솔도 제공합니다.
이러한 간단한 전환 방식으로 많은 개발자들의 관심을 끌었고, 현재 28만명 이상이 그로크의 서비스를 이용하고 있습니다. 로스 CEO는 내년까지 전 세계 추론 계산의 절반 이상이 Groq의 칩에서 실행되어 AI 분야에서 회사의 잠재력과 전망을 보여줄 것이라고 말했습니다.
가장 밝은 부분:
Groq, GPU 속도보다 훨씬 빠른 초당 1256.54 마크를 처리하는 초고속 LLM 엔진 출시
Groq의 엔진은 LLM 챗봇의 속도와 유연성을 보여주어 개발자와 비개발자 모두의 관심을 끌고 있습니다.
? Groq는 280,000명 이상의 개발자가 사용한 무료 LLM 워크로드 서비스를 제공하며, 내년에는 전 세계 추론 계산의 절반이 이 칩에서 실행될 것으로 예상됩니다.
Groq의 빠른 LLM 엔진은 의심할 여지없이 AI 분야에 새로운 가능성을 가져오고, 높은 성능과 사용 용이성은 LLM 기술의 더 넓은 적용을 촉진할 것입니다. Downcodes의 편집자는 Groq의 향후 개발이 기대할만한 가치가 있다고 믿습니다!