최근 인공지능 기술의 급속한 발전은 대용량 데이터의 훈련에 크게 의존하고 있다. 그러나 Downcodes의 편집자는 MIT 및 기타 기관의 최신 연구에서 데이터 획득의 어려움이 급격히 증가하고 있음을 지적했습니다. 한때 쉽게 사용할 수 있었던 네트워크 데이터는 이제 점점 더 엄격한 제한을 받게 되어 AI 교육 및 개발에 큰 어려움을 초래합니다. 여러 오픈 소스 데이터 세트를 분석한 연구는 이러한 냉혹한 현실을 드러냅니다.
인공지능의 급속한 발전 뒤에는 데이터 수집의 어려움이 커지고 있다는 심각한 문제가 나타나고 있습니다. MIT 및 기타 기관의 최신 연구에 따르면 한때 쉽게 접근할 수 있었던 웹 데이터가 이제는 접근하기가 점점 더 어려워지고 있으며, 이는 AI 교육 및 연구에 큰 어려움을 초래하고 있습니다.
연구원들은 C4, RefineWeb, Dolma 등과 같은 여러 오픈 소스 데이터세트로 크롤링된 웹사이트가 라이센스 계약을 빠르게 강화하고 있음을 발견했습니다. 이는 상용 AI 모델의 훈련에 영향을 미칠 뿐만 아니라 학계와 비영리단체의 연구에도 방해가 된다.

이번 연구는 MIT 미디어랩, 웰슬리 칼리지, AI 스타트업 레이브 등 4명의 팀 리더가 진행했다. 그들은 데이터 제한이 급증하고 있으며 라이센스 비대칭성과 불일치가 점점 더 명백해지고 있다는 점에 주목합니다.
연구팀은 연구 방법으로 로봇 배제 프로토콜(REP)과 웹사이트 서비스 약관(ToS)을 활용했다. 그들은 OpenAI와 같은 대규모 AI 회사의 크롤러조차도 점점 더 엄격한 제한에 직면하고 있음을 발견했습니다.
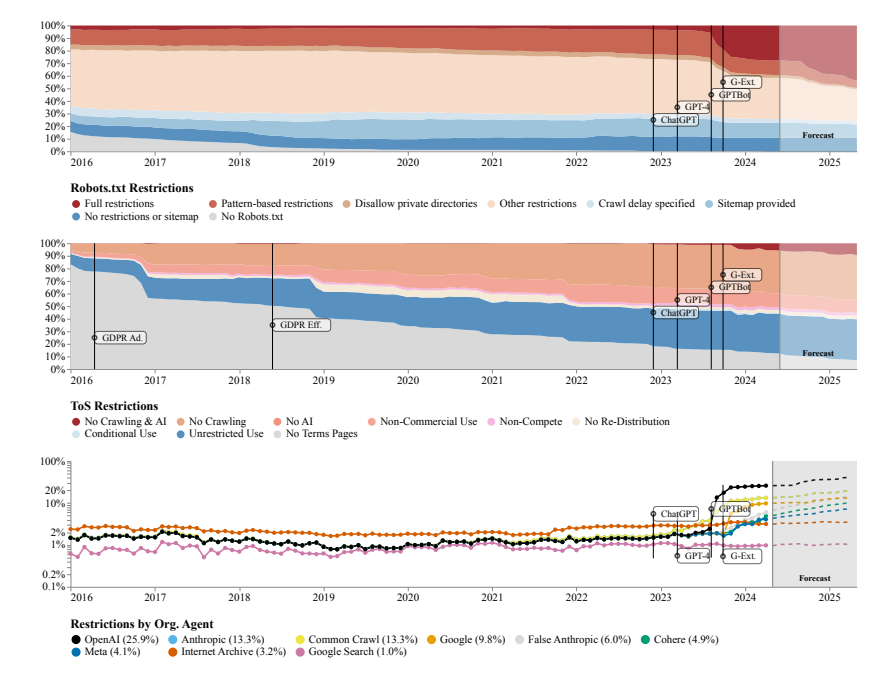
SARIMA 모델은 앞으로 robots.txt를 통해서든 ToS를 통해서든 웹사이트 데이터 제한이 계속 증가할 것이라고 예측합니다. 이는 개방형 네트워크 데이터에 대한 접근이 더욱 어려워질 것임을 시사합니다.
또한 인터넷에서 크롤링된 데이터가 AI 모델의 훈련 목적과 일치하지 않아 모델 정렬, 데이터 수집 관행 및 저작권에 영향을 미칠 수 있다는 사실도 발견했습니다.
연구팀은 웹사이트 소유자의 희망사항을 반영하고, 허용된 사용 사례와 허용되지 않는 사용 사례를 분리하고, 서비스 약관과 동기화하는 보다 유연한 계약의 필요성을 요구합니다. 동시에 그들은 AI 개발자가 교육을 위해 개방형 웹의 데이터를 사용할 수 있기를 원하며 향후 법률이 이를 뒷받침할 수 있기를 바랍니다.
논문 주소: https://www.dataprovenance.org/Consent_in_Crisis.pdf
이 연구는 인공지능 분야의 데이터 수집 문제에 대한 경각심을 일깨웠고, 미래 AI 모델의 훈련과 개발에 대한 새로운 과제를 제기했습니다. 데이터 수집과 웹사이트 소유자의 권익 사이의 균형을 어떻게 맞출 것인가는 인공지능 분야에서 진지하게 고민하고 해결해야 할 핵심 문제가 될 것입니다. Downcodes의 편집자는 자세한 내용을 알아보려면 논문에 주의를 기울일 것을 권장합니다.