자연어 처리(NLP) 분야는 날이 갈수록 변화하고 있으며, 대규모 언어 모델(LLM)의 급속한 발전은 우리에게 전례 없는 기회와 도전을 가져왔습니다. 그중에서도 사람이 주석을 추가한 데이터에 대한 모델 평가의 의존성은 병목 현상이 발생합니다. 높은 비용과 시간이 소요되는 데이터 수집 작업으로 인해 모델의 효과적인 평가와 지속적인 개선이 제한됩니다. Downcodes의 편집자는 이 문제를 해결하기 위한 새로운 아이디어를 제공하는 Meta FAIR 연구진이 제안한 새로운 솔루션인 "Self-learning Evaluator"를 소개합니다.
오늘날 자연어 처리(NLP) 분야는 빠르게 발전하고 있으며, 대규모 언어 모델(LLM)은 복잡한 언어 관련 작업을 높은 정확도로 수행할 수 있어 인간과 컴퓨터의 상호 작용에 더 많은 가능성을 제공합니다. 그러나 NLP의 중요한 문제는 모델 평가를 위해 사람의 주석에 의존한다는 것입니다.
인간이 생성한 데이터는 모델 교육 및 검증에 매우 중요하지만 이 데이터를 수집하는 데는 비용과 시간이 많이 소요됩니다. 또한, 모델이 지속적으로 개선됨에 따라 이전에 수집된 주석을 업데이트해야 하므로 새 모델을 평가하는 데 유용성이 떨어지며 이로 인해 새로운 데이터를 지속적으로 획득해야 하므로 효과적인 모델 평가의 규모와 지속 가능성이 어려워집니다.
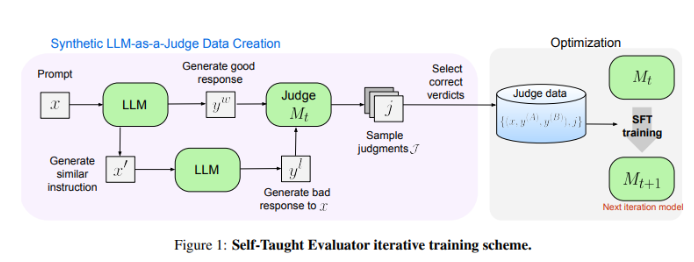
Meta FAIR의 연구원들은 "Self-Taught Evaluator"라는 새로운 솔루션을 내놓았습니다. 이 접근 방식은 사람의 주석이 필요하지 않으며 합성으로 생성된 데이터에 대해 교육됩니다. 먼저, 시드 모델은 대조되는 합성 선호 쌍을 생성한 다음, 모델이 이러한 쌍을 평가하고 자체 판단을 사용하여 후속 반복에서 성능을 개선함으로써 인간이 생성한 주석에 대한 의존도를 크게 줄이는 방식으로 이를 반복적으로 개선합니다.
연구원들은 Llama-3-70B-Instruct 모델을 사용하여 "자가 학습 평가기"의 성능을 테스트했습니다. 이 방법은 RewardBench 벤치마크에서 모델의 정확도를 75.4에서 88.7로 향상시켜 인간 주석으로 훈련된 모델의 성능과 일치하거나 심지어 초과합니다. 여러 번의 반복 끝에 최종 모델은 단일 추론에서 88.3, 다수 투표에서 88.7의 정확도를 달성하여 강력한 안정성과 신뢰성을 입증했습니다.
"Self-Learning Evaluator"는 NLP 모델 평가를 위한 확장 가능하고 효율적인 솔루션을 제공하여 합성 데이터와 반복적인 자기 개선을 활용하고 인간 주석에 의존하는 문제를 해결하고 언어 모델 개발을 발전시킵니다.
논문 주소: https://arxiv.org/abs/2408.02666
Meta FAIR의 "자가 학습 평가기"는 NLP 모델 평가에 혁신적인 변화를 가져왔으며, 그 효율적이고 확장 가능한 기능은 미래 언어 모델의 지속적인 발전을 효과적으로 촉진할 것입니다. 이 연구 결과는 사람이 주석을 추가한 데이터에 대한 의존도를 줄일 뿐만 아니라 더 중요하게는 더욱 강력하고 신뢰할 수 있는 NLP 모델을 구축할 수 있는 길을 열어줍니다. 앞으로도 더욱 유사한 혁신을 기대합니다!