인공지능의 급속한 발전으로 가볍고 효율적인 사용자 인터페이스 이해 기술은 AI 애플리케이션의 핵심이 되었습니다. 최근 발표된 연구 논문에서 Apple은 경량 기기에서 효율적인 UI 이해 문제를 해결하는 것을 목표로 하는 UI-JEPA라는 새로운 아키텍처를 도입했습니다. 이 기술은 고성능을 유지할 뿐만 아니라 컴퓨팅 요구 사항을 크게 줄여 리소스가 제한된 장치에서 AI 애플리케이션을 실행할 수 있는 새로운 가능성을 제공합니다. UI-JEPA의 등장으로 더욱 편리하고 프라이빗한 AI 애플리케이션의 대중화가 촉진될 것으로 예상됩니다.
인공지능 기술이 계속 발전함에 따라 직관적이고 유용한 AI 애플리케이션을 만드는 데 있어서 사용자 인터페이스(UI)에 대한 이해가 핵심 과제가 되었습니다. 최근 Apple 연구원들은 높은 성능을 유지할 뿐만 아니라 UI 계산 요구 사항을 크게 줄이는 경량 장치 측 UI 이해를 달성하도록 설계된 아키텍처인 UI-JEPA를 새로운 논문에서 소개했습니다.
UI 이해의 과제는 UI 시퀀스의 시간적 관계를 포착하기 위해 이미지와 자연어를 포함한 교차 모달 기능을 처리해야 한다는 것입니다. Anthropic Claude3.5Sonnet 및 OpenAI GPT-4Turbo와 같은 다중 모드 대형 언어 모델(MLLM)이 개인화된 계획에서 진전을 이루었지만 이러한 모델은 광범위한 컴퓨팅 리소스, 거대한 모델 크기 및 높은 대기 시간을 도입해야 하며, 낮은 대기 시간을 요구하는 경량 장치 솔루션에는 적합하지 않습니다. 대기 시간 및 향상된 개인 정보 보호.
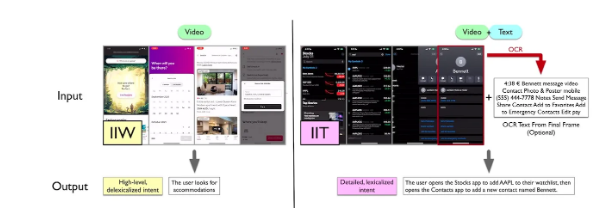
UI-JEPA의 IIT 및 IIW 데이터 세트 예시 이미지 출처: arXiv
UI 이해에 대한 연구를 더욱 발전시키기 위해 연구원들은 두 가지 새로운 다중 모드 데이터 세트와 벤치마크인 "Intentions in the Wild"(IIW)와 "Intentions in the Tame"(IIT)을 도입했습니다. IIW는 모호한 사용자 의도로 개방형 UI 동작 시퀀스를 캡처하는 반면, IIT는 보다 명확한 의도를 가진 일반적인 작업에 중점을 둡니다.
새로운 벤치마크에서 UI-JEPA의 성능을 평가한 결과, Few-Shot 설정에서 다른 비디오 인코더 모델보다 성능이 뛰어나고 더 큰 폐쇄형 모델과 비슷한 성능을 달성하는 것으로 나타났습니다. 연구원들은 광학 문자 인식(OCR)을 사용하여 UI에서 추출된 텍스트를 병합하면 UI-JEPA의 성능이 더욱 향상된다는 것을 발견했습니다.
UI-JEPA 모델의 잠재적인 용도로는 AI 에이전트를 위한 자동화된 피드백 루프 생성, 사람의 개입 없이 상호 작용을 통해 지속적으로 학습할 수 있도록 지원, 기관 프레임워크의 다양한 애플리케이션 및 모드에서 사용자 의도를 추적하도록 설계된 애플리케이션에 UI-JEPA 통합 등이 있습니다. .
Apple의 UI-JEPA 모델은 Apple 장치를 더욱 스마트하고 효율적으로 만들기 위해 설계된 경량 생성 AI 도구 모음인 Apple Intelligence에 적합한 것으로 보입니다. Apple이 개인 정보 보호에 중점을 두고 있다는 점을 감안할 때 UI-JEPA 모델의 저렴한 비용과 추가 효율성은 AI 도우미가 클라우드 모델을 사용하는 다른 도우미보다 우위에 있을 수 있습니다.
UI-JEPA의 출현은 경량 장치 측 AI 애플리케이션에 새로운 가능성을 가져왔습니다. 개인 정보 보호 및 효율적인 컴퓨팅의 이점은 향후 AI 개발에서 광범위한 애플리케이션 전망을 제공하며 지속적인 관심을 받을 가치가 있습니다.