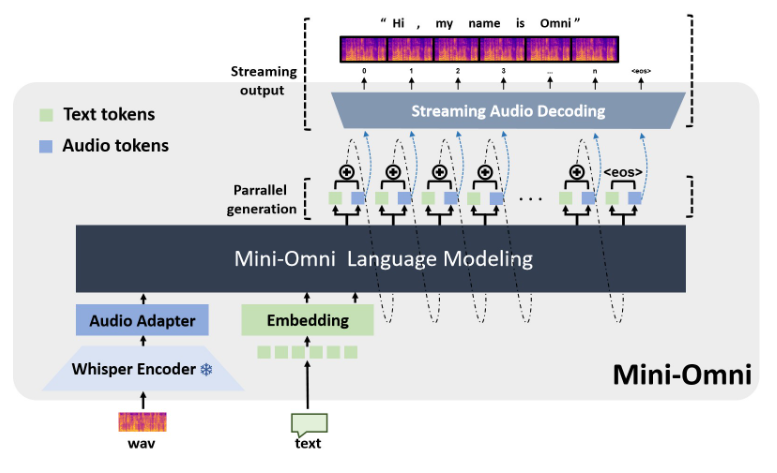
오픈 소스 다중 모드 대규모 언어 모델인 Mini-Omni는 음성 상호 작용 기술에 혁명을 일으키고 있습니다. 실시간 음성 입력 및 출력을 실현하기 위해 고급 기술을 통합하고 동시에 생각하고 말할 수 있는 기능을 갖추고 있어 보다 자연스럽고 원활한 인간-컴퓨터 상호 작용 경험을 제공합니다. Mini-Omni의 핵심 장점은 원활한 대화를 즐기기 위해 ASR 또는 TTS 모델을 추가로 구성할 필요가 없는 엔드투엔드 실시간 음성 처리 기능에 있습니다. 여러 모달 입력을 지원하고 이를 유연하게 변환하여 다양하고 복잡한 시나리오에 적응하고 다양한 요구 사항을 충족합니다.
오늘날 인공 지능의 급속한 발전과 함께 Mini-Omni라는 오픈 소스 다중 모드 대규모 언어 모델이 음성 상호 작용 기술의 혁신을 주도하고 있습니다. 여러 첨단 기술이 통합된 이 AI 시스템은 실시간 음성 입력 및 출력이 가능할 뿐만 아니라 동시에 생각하고 말하는 고유한 능력을 갖추고 있어 사용자에게 전례 없는 자연스러운 상호 작용 경험을 제공합니다.
Mini-Omni의 핵심 장점은 엔드투엔드 실시간 음성 처리 기능에 있습니다. 사용자는 자동 음성 인식(ASR)이나 텍스트 음성 변환(TTS) 모델을 추가로 구성하지 않고도 원활한 음성 대화를 즐길 수 있습니다. 이 매끄러운 디자인은 사용자 경험을 크게 향상시키고 인간과 컴퓨터의 상호 작용을 더욱 자연스럽고 직관적으로 만듭니다.
Mini-Omni는 음성 기능 외에도 텍스트 등 다양한 모드의 입력도 지원하며 다양한 모드 간을 유연하게 전환할 수 있습니다. 이 다중 모드 처리 기능을 통해 모델은 다양하고 복잡한 상호 작용 시나리오에 적응하고 사용자의 다양한 요구를 충족할 수 있습니다.
특히 언급할만한 가치가 있는 것은 Mini-Omni의 Any Model Can Talk 기능입니다. 이러한 혁신을 통해 다른 AI 모델은 Mini-Omni의 실시간 음성 기능을 쉽게 통합할 수 있어 AI 애플리케이션의 가능성이 크게 확장됩니다. 이는 개발자에게 더 많은 선택권을 제공할 뿐만 아니라 AI 기술을 다양한 분야에 적용할 수 있는 길을 열어줍니다.
성능면에서 Mini-Omni는 포괄적인 강점을 보여줍니다. 음성 인식(ASR) 및 음성 생성(TTS)과 같은 전통적인 음성 작업에서 우수한 성능을 발휘할 뿐만 아니라 TextQA 및 SpeechQA와 같은 복잡한 추론 기능이 필요한 다중 모드 작업에서도 강력한 잠재력을 보여줍니다. 이 포괄적인 기능을 통해 Mini-Omni는 간단한 음성 명령부터 심층적인 사고가 필요한 질문 및 답변 작업에 이르기까지 다양하고 복잡한 상호 작용 시나리오를 처리할 수 있습니다.
Mini-Omni의 기술 구현에는 여러 고급 AI 모델과 기술이 통합되어 있습니다. 대규모 언어 모델의 기반으로 Qwen2를 사용하고, 훈련 및 추론에 litGPT를 사용하고, 오디오 인코딩에 속삭임을 사용하고, sac는 오디오 디코딩을 담당합니다. 이 다중 기술 융합 방법은 모델의 전반적인 성능을 향상시킬 뿐만 아니라 다양한 시나리오에서의 적응성을 향상시킵니다.
개발자와 연구자에게 Mini-Omni는 편리한 사용을 제공합니다. 간단한 설치 단계를 통해 사용자는 로컬 환경에서 Mini-Omni를 실행하고 Streamlit 및 Gradio와 같은 도구를 통해 대화형 데모를 수행할 수 있습니다. 이러한 개방적이고 사용하기 쉬운 기능은 AI 기술의 대중화와 혁신적인 적용을 강력하게 지원합니다.
프로젝트 주소: https://github.com/gpt-omni/mini-omni
강력한 기능, 편리한 사용 및 오픈 소스 기능을 갖춘 Mini-Omni는 AI 음성 상호 작용 분야에 새로운 가능성을 제공하며 개발자와 연구원의 관심과 탐구를 받을 가치가 있습니다. 앞으로의 전개도 기대해볼 만하다.