최근 오픈소스 AI 모델인 Reflection70B가 성능 논란으로 업계에서 큰 주목을 받고 있다. 이 모델은 HyperWrite에서 출시한 것으로, 당초 세계에서 가장 강력한 오픈소스 모델이라고 주장했으며, 제3자 테스트에서도 뛰어난 성능을 보여 많은 주목을 받았습니다. 그러나 일부 독립 기관과 사용자는 이후 성능에 의문을 제기했으며 테스트 결과는 HyperWrite의 초기 주장과 크게 달랐습니다.
이제 막 데뷔한 오픈소스 AI 모델인 Reflection70B가 최근 업계에서 폭넓은 의문을 제기했습니다.
Meta의 Llama3.1 변종이라고 주장하는 뉴욕 스타트업 HyperWrite가 출시한 이 모델은 제3자 테스트에서 뛰어난 성능을 보여 주목을 받았습니다. 그러나 일부 테스트 결과가 공개되면서 Reflection70B의 명성이 도전받기 시작했습니다.
문제의 원인은 HyperWrite의 공동 창립자이자 CEO인 Matt Shumer가 9월 6일 소셜 미디어 X에서 Reflection70B를 발표하고 이를 "세계에서 가장 강력한 오픈 소스 모델"이라고 자신있게 언급했기 때문입니다.
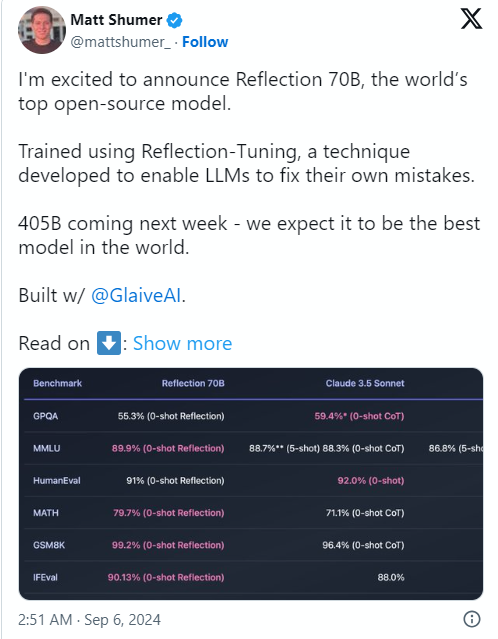
Shumer는 또한 모델의 "반사 튜닝" 기술에 대해 공유하면서 이 방법을 사용하면 모델이 콘텐츠를 생성하기 전에 자체적으로 검토하여 정확성을 높일 수 있다고 주장했습니다.
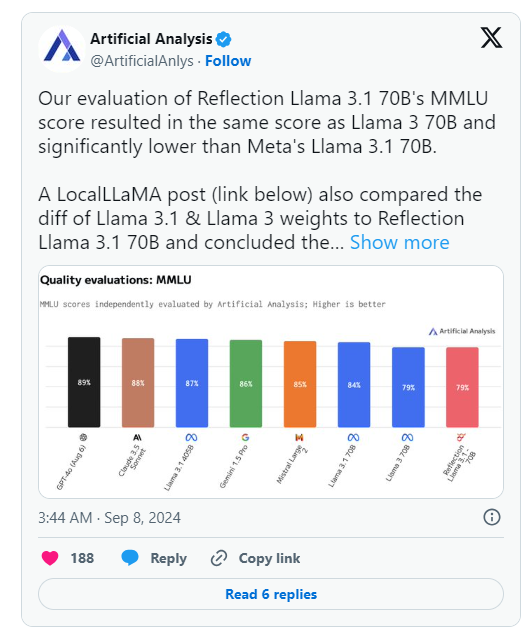
그러나 HyperWrite 발표 다음 날, "AI 모델 및 호스팅 제공업체에 대한 독립적인 분석"을 전문으로 하는 그룹인 Artificial Analysis는 X에 대한 자체 분석을 발표하며 Reflection Llama3.170B의 MMLU(Massive Multitask Language Understanding) 점수를 평가했다고 언급했습니다. Llama370B와 동일하지만 Meta의 Llama3.170B보다 현저히 낮습니다. 이는 HyperWrite/Shumer가 원래 게시한 결과와 상당한 차이가 있습니다.
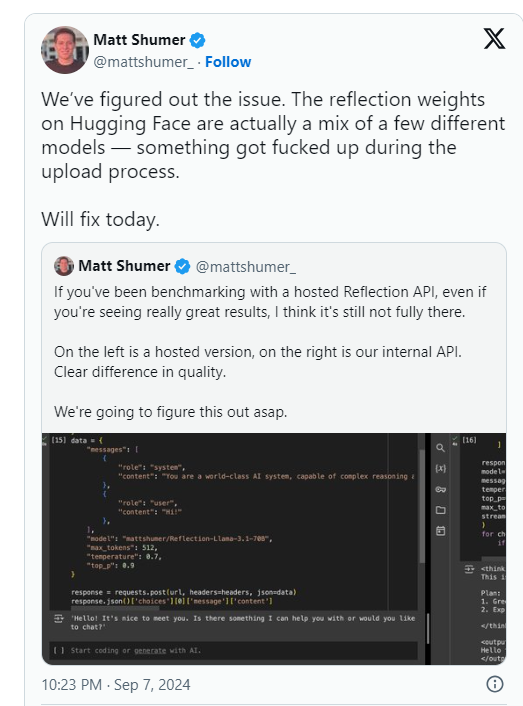
Shumer는 나중에 Hugging Face(타사 AI 코드 호스팅 저장소 및 회사)에 업로드하는 동안 Reflection70B의 가중치(또는 오픈 소스 모델에 대한 설정)에 문제가 있어 HyperWrite의 "내부 API보다 성능이 저하될 수 있다"고 밝혔습니다. " 버전. .
인공 분석은 후속 성명에서 프라이빗 API에 대한 액세스 권한을 얻었고 인상적인 성능을 보았지만 원래 언급된 수준에는 미치지 못했다고 밝혔습니다. 이번 테스트는 프라이빗 API로 진행되었기 때문에 테스트 내용을 독립적으로 검증할 수 없었습니다.
그룹은 HyperWrite와 Shumer의 원래 성능 주장에 심각한 의문을 제기하는 두 가지 주요 문제를 제기했습니다.
한편 Reddit의 여러 기계 학습 및 AI 커뮤니티 사용자들은 Reflection70B의 주장된 성능과 출처에 의문을 제기했습니다. 일부에서는 Github에 제3자가 게시한 모델 비교를 기반으로 Reflection70B가 Llama-3.1이 아닌 Llama3의 변형인 것으로 보인다는 점을 지적하여 Shumer와 HyperWrite의 원래 주장에 대해 더욱 의문을 제기했습니다.
이로 인해 최소 한 명의 X 사용자인 Shin Megami Boson이 9월 8일(ET)에 게시되었습니다.
오후 8시 7분(EDT) 슈머는 AI 연구 커뮤니티에서 슈머를 '사기 행위'로 공개 비난하고 긴 스크린샷과 기타 증거 목록을 공개했다.
다른 사람들은 이 모델이 실제로 독점/비공개 소스 경쟁사인 Anthropic의 Claude3 위에 구축된 "래퍼" 또는 애플리케이션이라고 주장했습니다.
그러나 다른 X 사용자들은 Shumer와 Reflection70B를 옹호했으며, 일부는 모델 종료 시 인상적인 성능을 기록하기도 했습니다.
현재 AI 연구 커뮤니티는 이러한 사기 혐의에 대한 Shumer의 답변과 Hugging Face의 업데이트된 모델 가중치를 기다리고 있습니다.
Reflection70B 모델이 출시된 후 테스트 결과가 초기 주장을 재현하지 못하면서 성능에 의문이 제기되었습니다.
⚙️ HyperWrite의 창립자는 모델 업로드 문제로 인해 성능 저하가 발생한다고 설명하며 업데이트된 버전에 대한 주의를 당부했습니다.
이 모델은 비난과 방어가 뒤섞여 소셜 미디어에서 뜨거운 논쟁을 불러일으켰습니다.
현재 Reflection70B 사건은 여전히 계속해서 발효되고 있으며 최종 결과는 여전히 추가 조사와 대응을 기다려야 합니다. 이번 사건은 또한 우리가 AI 모델의 성능 향상에 신중해야 하며 판단을 내리기 위해 독립적인 검증 결과에 의존해야 함을 상기시켜 줍니다.