상하이 인공 지능 연구소(Shanghai AI Laboratory) 대규모 모델 데이터베이스 OpenDataLab 팀은 2024 WAIC Science Frontier 메인 포럼에서 새로운 지능형 데이터 추출 도구 MinerU를 출시했습니다. 이 오픈소스 도구는 AI 데이터 처리 프로세스를 단순화하고 연구자가 대용량 문서에서 고품질 데이터를 보다 효율적으로 추출할 수 있도록 돕는 것을 목표로 합니다. MinerU는 PDF, 웹페이지, epub, mobi, docx 등 다양한 문서 형식을 지원하고, 분석하기 쉬운 Markdown 형식으로 변환합니다. 핵심 기능 모듈 Magic-PDF 및 Magic-Doc은 각각 PDF 문서 및 웹 페이지/전자책 추출에 중점을 두고 있으며 LayoutLMv3, YOLOv8, UniMERNet 및 PaddleOCR과 같은 모델을 사용하여 고품질 데이터 추출을 달성하여 데이터를 크게 향상시킵니다. 처리 효율성.
2024 WAIC 사이언스 프론티어 메인 포럼에서 상하이 인공 지능 연구소(Shanghai AI Laboratory) 대규모 모델 데이터베이스 OpenDataLab 팀은 MinerU라는 새로운 지능형 데이터 추출 도구를 출시했습니다. 이 도구는 AI 데이터 처리 프로세스를 단순화하고 AI 연구자가 대용량 문서에서 고품질 데이터를 추출할 수 있도록 설계되었습니다.
MinerU는 그림, 표, 수식 등을 포함한 다중 모드 PDF 문서를 명확하고 분석하기 쉬운 마크다운 형식으로 변환할 수 있는 올인원 오픈 소스 문서 및 웹 페이지 데이터 추출 도구입니다. 또한 광고 등 간섭 정보가 포함된 웹페이지에서 형식적인 콘텐츠를 빠르게 구문 분석하고 추출할 수 있으며, epub, mobi, docx 등 다양한 형식을 마크다운으로 일괄 변환하는 기능을 지원합니다.
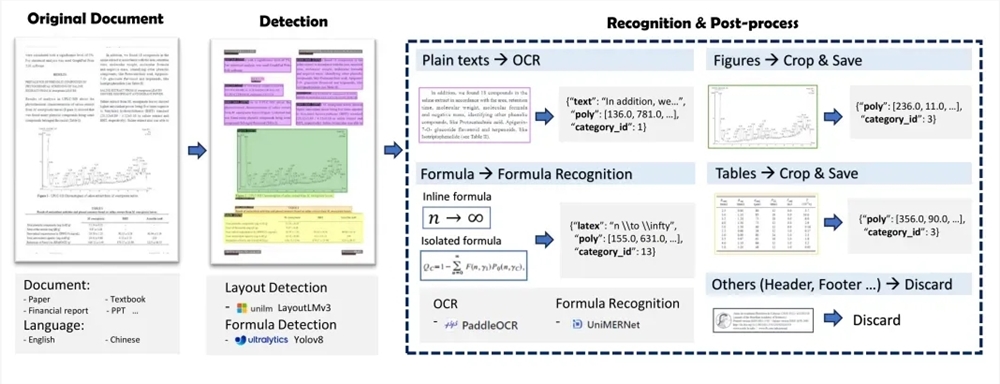
MinerU는 Magic-PDF와 Magic-Doc의 두 가지 주요 부분으로 구성됩니다. Magic-PDF는 PDF 문서 추출에 중점을 두고 PDF를 마크다운 형식으로 변환하며 PDF 레이아웃 요소를 빠르게 식별하고 텍스트가 아닌 콘텐츠를 자동으로 삭제하며 원본 문서의 구조와 형식을 유지할 수 있습니다. Magic-Doc은 웹페이지 및 전자책 추출을 담당하며, 기사, 포럼, 음악, 비디오 등과 같은 일반적인 웹페이지 정보 추출과 전자책 형식 변환을 지원합니다.
기술적 수준에서 MinerU의 PDF 문서 추출 프로세스에는 PDF 문서 분류 전처리, 모델 분석, 파이프라인 처리 및 PDF 추출 결과의 품질 검사가 포함됩니다. LayoutLMv3, YOLOv8, UniMERNet 및 PaddleOCR과 같은 일련의 모델을 활용하여 고품질 문서 데이터 추출을 달성합니다.
MinerU의 출시는 AI 연구자들에게 강력한 데이터 처리 도구를 제공할 뿐만 아니라 대규모 모델 개발 및 적용을 위한 전체 체인 도구 시스템의 업그레이드를 더욱 촉진합니다.
매직 커뮤니티 체험 링크:
https://modelscope.cn/studios/OpenDataLab/MinerU
코드 오픈 소스 링크:
https://github.com/opendatalab/MinerU/
MinerU 오픈 소스 모델(PDF-Extract-Kit):
https://modelscope.cn/models/OpenDataLab/PDF-Extract-Kit
MinerU의 오픈 소스와 사용 편의성은 AI 연구자 및 개발자를 크게 촉진하고 AI 분야의 데이터 처리 효율성을 가속화하며 대형 모델 개발에 대한 강력한 지원을 제공할 것입니다. MinerU를 경험하고 사용하기 위해 링크를 방문하신 것을 환영합니다.