대형 모델의 명령어 튜닝은 성능 향상의 핵심입니다. Tencent Youtu Labs는 Shanghai Jiao Tong University와 협력하여 명령 튜닝 데이터 세트의 평가 및 선택에 대한 심층적인 정보를 제공하는 상세한 리뷰를 발표했습니다. 400개 이상의 관련 문서를 기반으로 한 10,000 단어 길이의 이 기사는 데이터 품질, 다양성 및 중요성의 세 가지 차원에서 대규모 모델의 교육 조정에 대한 포괄적인 지침을 제공하고 기존 연구 및 향후 전망 개발의 과제를 지적합니다. 방향. 이 기사에서는 연구자가 최적의 데이터 세트를 선택하고 대규모 모델의 성능과 안정성을 향상시키는 데 도움을 주기 위해 직접 설계한 지표, 모델 기반 지표, GPT 자동 채점, 수동 평가 등 다양한 평가 방법을 다루고 있습니다.
지속적인 반복 업그레이드를 통해 대형 모델이 더욱 스마트해지고 있지만, 모델이 우리의 요구 사항을 진정으로 이해하려면 지침 조정이 핵심입니다. Tencent Youtu Lab과 Shanghai Jiao Tong University의 전문가들은 명령 튜닝 데이터 세트의 평가 및 선택에 대해 심도 있게 논의하는 10,000자 리뷰를 공동으로 발표하여 대형 모델의 성능을 향상시키는 방법에 대한 수수께끼를 밝혔습니다.
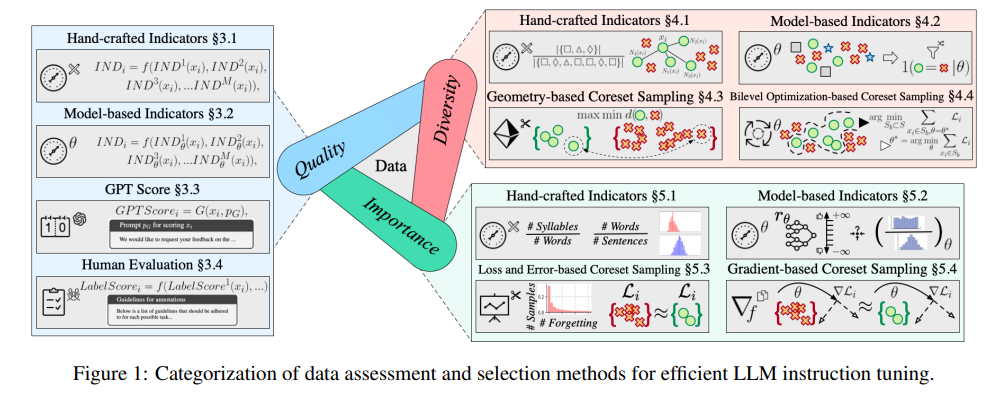
대형 모델의 목표는 자연어 처리의 본질을 익히는 것이며, 명령 조정은 학습 과정에서 중요한 단계입니다. 전문가들은 대규모 모델이 다양한 작업에서 제대로 작동하는지 확인하기 위해 데이터 세트를 평가하고 선택하는 방법에 대한 심층 분석을 제공합니다.
이 검토는 길이가 놀라울 뿐만 아니라 400개 이상의 관련 문서를 다루며 데이터 품질, 다양성 및 중요성의 세 가지 차원에 대한 자세한 지침을 제공합니다.
데이터 품질은 명령어 튜닝의 효율성에 직접적인 영향을 미칩니다. 전문가들은 직접 설계한 지표, 모델 기반 지표, GPT 자동 채점, 필수 수동 평가 등 다양한 평가 방법을 제안해 왔습니다.
다양성 평가는 어휘, 의미, 전반적인 데이터 분포의 다양성을 포함하여 데이터 세트의 풍부함에 중점을 둡니다. 다양한 데이터 세트를 사용하면 모델을 다양한 시나리오에 더 효과적으로 일반화할 수 있습니다.
중요성 평가는 모델 학습에 가장 중요한 샘플을 선택하는 것입니다. 이는 훈련 효율성을 향상시킬 뿐만 아니라 복잡한 작업에 직면할 때 모델의 안정성과 정확성을 보장합니다.
현재 연구가 일정한 결과를 얻었음에도 불구하고 전문가들은 데이터 선택과 모델 성능 사이의 약한 상관관계, 지침의 품질을 평가하기 위한 통일된 표준 부족 등 기존 과제도 지적했습니다.
앞으로 전문가들은 다양한 다운스트림 작업에 적응하기 위해 선택 파이프라인의 해석성을 향상시키면서 명령 튜닝 모델을 평가하기 위한 전문 벤치마크의 확립을 요구합니다.
Tencent Youtu Lab과 Shanghai Jiao Tong University의 이 연구는 우리에게 귀중한 자원을 제공할 뿐만 아니라 대형 모델 개발의 방향을 제시합니다. 기술이 계속 발전함에 따라 대형 모델이 더욱 지능화되고 인간에게 더 나은 서비스를 제공할 것이라고 믿을 만한 이유가 있습니다.
논문 주소: https://arxiv.org/pdf/2408.02085
이 연구는 대형 모델 지침 조정에 대한 귀중한 지침을 제공하고 향후 대형 모델 개발을 위한 견고한 기반을 마련합니다. 앞으로도 유사한 연구 결과가 더 많아져 대형 모형 기술의 지속적인 발전을 촉진하고 인류에게 더 나은 서비스를 제공할 수 있기를 기대합니다.