Tencent Youtu Lab 및 기타 기관은 비디오, 이미지, 텍스트 및 오디오를 동시에 처리하고 원활한 대화형 경험을 제공할 수 있는 최초의 다중 모드 대형 언어 모델 VITA를 오픈 소스화했습니다. VITA의 출현은 중국어 방언 처리에 있어 기존 대규모 언어 모델의 단점을 보완하는 것을 목표로 합니다. Mixtral8×7B 모델을 기반으로 중국어 어휘를 확장하고 이중 언어 지침을 미세 조정하여 영어에 능숙하게 만듭니다. 그리고 중국어도 유창해요. 이는 오픈 소스 커뮤니티의 다중 모드 이해 및 상호 작용에 있어 상당한 진전을 의미합니다.
최근 Tencent Youtu Lab 및 기타 기관의 연구원들은 비디오, 이미지, 텍스트 및 오디오를 동시에 처리할 수 있는 최초의 오픈 소스 다중 모드 대형 언어 모델 VITA를 출시했으며 대화형 경험도 최고 수준입니다.
VITA 모델은 중국어 방언 처리에 있어 대규모 언어 모델의 단점을 보완하기 위해 탄생했습니다. 강력한 Mixtral8×7B 모델, 확장된 중국어 어휘 및 미세 조정된 이중 언어 지침을 기반으로 하여 VITA는 영어에 능숙할 뿐만 아니라 중국어에도 유창하게 만듭니다.
주요 특징:
다중 모드 이해: 비디오, 이미지, 텍스트 및 오디오를 처리하는 VITA의 능력은 오픈 소스 모델 중에서 전례가 없습니다.
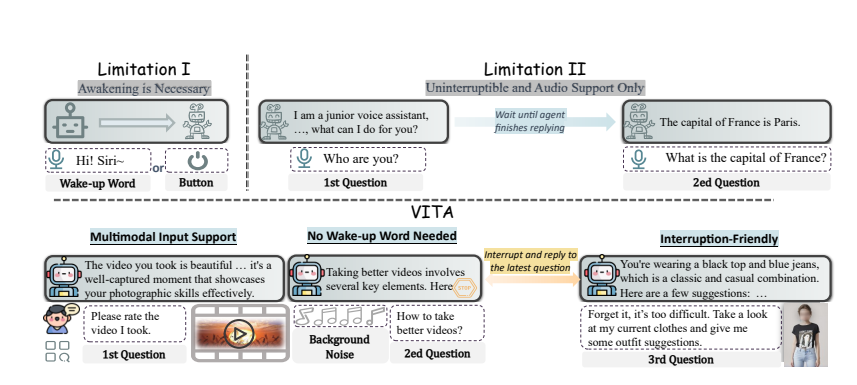
자연스러운 상호작용: 매번 "Hey, VITA"라고 말할 필요가 없으며, 말할 때 언제든지 응답할 수 있으며, 다른 사람과 대화할 때에도 예의바르고 마음대로 방해하지 않을 수 있습니다.
오픈 소스 개척자: VITA는 다중 모드 이해 및 상호 작용에서 오픈 소스 커뮤니티를 위한 중요한 단계이며 후속 연구의 기반을 마련합니다.
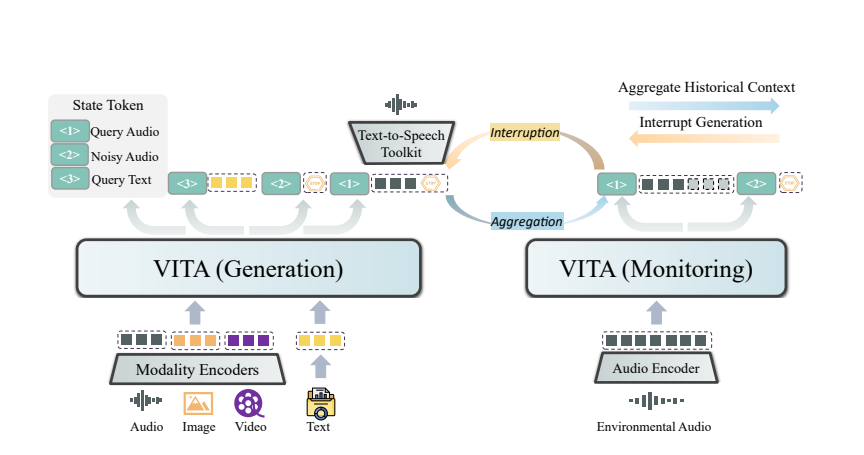
VITA의 마법은 이중 모델 배포에서 비롯됩니다. 한 모델은 사용자 쿼리에 대한 응답을 생성하는 역할을 담당하고, 다른 모델은 환경 입력을 지속적으로 추적하여 모든 상호 작용이 정확하고 시기적절하도록 보장합니다.
VITA는 채팅뿐만 아니라 운동할 때 채팅 파트너 역할을 하고, 여행할 때 조언도 해줄 수 있습니다. 또한, 제공하는 사진이나 영상 콘텐츠를 바탕으로 질문에 답할 수도 있어 강력한 실용성을 보여줍니다.
VITA는 큰 잠재력을 보여주었지만 감성 음성 합성 및 다중 모드 지원 측면에서 여전히 발전하고 있습니다. 연구진은 차세대 VITA를 통해 비디오 및 텍스트 입력에서 고품질 오디오를 생성하고 고품질 오디오 및 비디오를 동시에 생성할 수 있는 가능성도 탐색할 계획입니다.
VITA 모델의 오픈 소스는 기술적인 승리일 뿐만 아니라 지능적인 상호 작용 방식에 있어 심오한 혁신이기도 합니다. 연구가 심화됨에 따라 VITA가 더욱 스마트하고 인간적인 상호 작용 경험을 제공할 것이라고 믿을 만한 이유가 생겼습니다.
논문 주소: https://arxiv.org/pdf/2408.05211
VITA의 오픈 소스는 다중 모드 대형 언어 모델 개발을 위한 새로운 방향을 제시합니다. VITA의 강력한 기능과 편리한 대화형 경험은 인간과 컴퓨터의 상호 작용이 미래에 더욱 지능적이고 인간적이 될 것임을 나타냅니다. 앞으로도 VITA가 더 큰 발전을 이루며 사람들의 삶에 더 많은 편리함을 선사할 수 있기를 기대합니다.