Alibaba는 음성 인식, 번역 및 오디오 분석을 크게 개선한 새로운 오픈 소스 음성 모델 Qwen2-Audio를 출시했습니다. 기능과 성능은 이전 세대 제품인 Qwen-Audio를 능가하고 여러 벤치마크 테스트에서도 이를 능가했습니다. 대형-v3. Qwen2-Audio는 다국어를 지원하며 기본 버전과 안내가 포함된 미세 조정 버전을 제공합니다. 사용자는 음성으로 질문하고 화자의 나이와 감정을 판단하거나 다양한 소리를 분석하는 등 오디오 콘텐츠 인식 및 분석을 수행할 수 있습니다. 오디오의 구성 요소. 이 모델은 사전 훈련을 위해 보다 자연스러운 언어 프롬프트를 사용하여 이해 및 응답 능력을 크게 향상시켰으며, 사용자 상호 작용의 자연스러움을 향상시키기 위해 음성 채팅 및 오디오 분석의 두 가지 모드를 도입했습니다.
최근 Alibaba는 Qwen-Audio를 기반으로 하는 새로운 오픈 소스 음성 모델 Qwen2-Audio를 출시했습니다. 이 모델은 음성 인식, 번역, 오디오 분석에서 뛰어난 성능을 발휘할 뿐만 아니라 기능과 성능도 크게 향상되었습니다. Qwen2-Audio는 기본 버전과 세부 조정 버전의 지침을 제공합니다. 사용자는 음성을 통해 오디오 모델에게 질문하고 내용을 인식하고 분석할 수 있습니다.
예를 들어, 사용자는 여성에게 말을 해달라고 요청할 수 있고, Qwen2-Audio는 여성의 나이를 판단하거나 감정을 분석할 수 있으며, 시끄러운 소리가 입력되면 모델은 다양한 사운드 구성 요소를 분석할 수 있습니다. Qwen2-Audio는 중국어, 광둥어, 프랑스어, 영어, 일본어를 포함한 여러 언어를 지원하므로 감정 분석 및 번역 애플리케이션 개발에 큰 편의성을 제공합니다.
제품 입구: https://top.aibase.com/tool/qwen2-audio
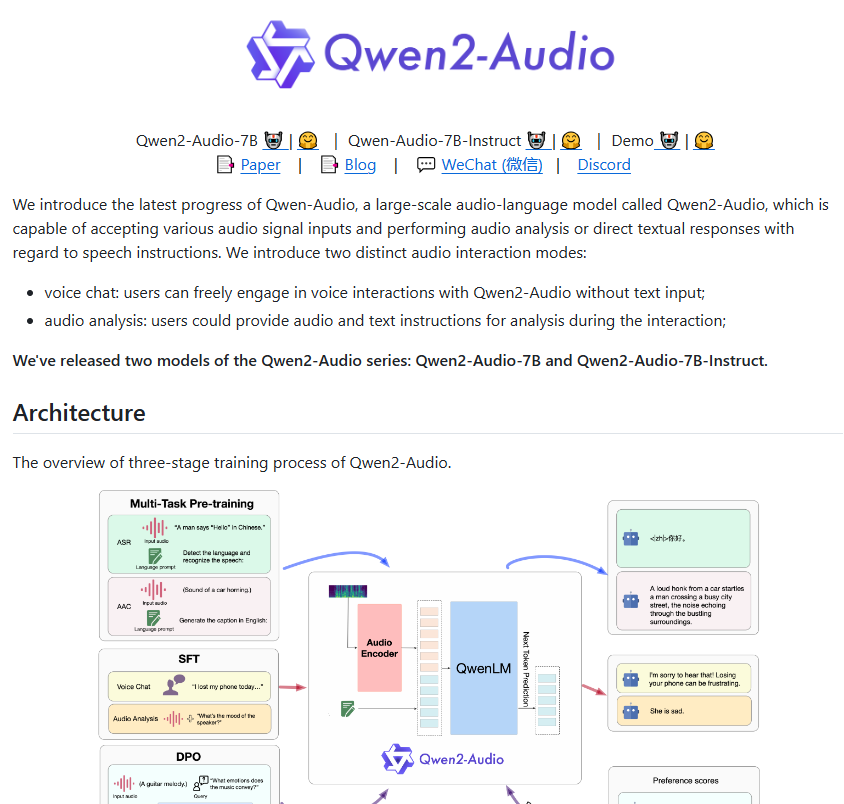
1세대 Qwen-Audio와 비교하여 Qwen2-Audio는 아키텍처와 성능이 완전히 최적화되었습니다. 사전 훈련 단계에서 이 새로운 모델은 이전의 복잡한 계층적 레이블을 대체하기 위해 보다 자연스러운 언어 단서를 사용합니다. 이번 개선을 통해 모델을 보다 쉽게 이해하고 다양한 업무에 대응할 수 있게 되었으며, 일반화 능력도 크게 향상되었습니다.
Qwen2-Audio의 명령 추종 능력도 크게 향상되어 사용자 명령을 보다 정확하게 이해할 수 있습니다. 예를 들어, 사용자가 "이 오디오의 감정적 경향을 분석해 보세요"라는 명령을 내리면 Qwen2-Audio는 오디오에 담긴 감정을 정확하게 판단할 수 있습니다. 또한 이 모델에는 음성 채팅과 오디오 분석이라는 두 가지 모드가 도입되어 사용자의 음성 상호 작용이 더욱 자연스러워집니다. 오디오 분석 모드에서 Qwen2-Audio는 다양한 유형의 오디오를 심층적으로 분석하고 상세하고 정확한 분석 결과를 제공할 수 있습니다.
모델의 출력이 인간의 기대를 충족하도록 보장하기 위해 Qwen2-Audio는 감독된 미세 조정 및 직접 선호도 최적화와 같은 고급 기술도 도입합니다. 모델은 인간과 상호작용할 때 더욱 자연스럽고 정확해 보입니다.
성능 테스트 측면에서 Qwen2-Audio는 여러 주류 벤치마크 테스트, 특히 음성 인식 및 번역의 정확성에서 OpenAI의 Whisper-large-v3를 능가하는 우수한 성능을 보였습니다. 이 새로운 모델의 성능은 업계에서 광범위한 관심을 끌었을 뿐만 아니라 음성 기술의 새로운 미래를 예고했습니다.
가장 밝은 부분:
Qwen2-Audio는 Alibaba의 최신 오픈 소스 음성 모델로, 다국어를 지원하고 강력한 인식 및 분석 기능을 갖추고 있습니다.
이전 세대에 비해 Qwen2-Audio는 성능과 아키텍처가 크게 최적화되어 이해하고 대응하는 능력이 향상되었습니다.
여러 성능 테스트에서 Qwen2-Audio는 OpenAI의 Whisper를 능가하며 강력한 경쟁력을 보여주었습니다.
Qwen2-Audio의 오픈 소스는 음성 기술 분야의 발전을 촉진하고 개발자에게 강력한 도구를 제공하며 보다 혁신적인 애플리케이션의 탄생을 촉진할 것입니다. 다국어 지원 및 성능의 장점은 향후 음성 기술 개발의 중요한 방향이 됩니다. 더 많은 시나리오에서 Qwen2-Audio의 적용을 기대합니다.