LLM(대형 언어 모델)은 긴 텍스트를 이해하는 데 어려움을 겪고 있으며 컨텍스트 창 크기가 처리 능력을 제한합니다. 이 문제를 해결하기 위해 연구원들은 LLM의 장기 컨텍스트 이해 능력을 평가하기 위해 LooGLE 벤치마크 테스트를 개발했습니다. LooGLE에는 2022년 이후 출시된 776개의 매우 긴 문서(평균 19.3k 단어)와 6448개의 테스트 인스턴스가 포함되어 있으며, 여러 필드를 포괄하여 긴 텍스트를 이해하고 처리하는 모델의 능력을 보다 포괄적으로 평가하는 것을 목표로 합니다. 이 벤치마크는 기존 LLM의 성능을 평가하고 향후 모델 개발을 위한 귀중한 참고 자료를 제공합니다.
자연어 처리 분야에서 긴 맥락을 이해하는 것은 항상 어려운 과제였습니다. LLM(대형 언어 모델)은 다양한 언어 작업에서 우수한 성능을 발휘하지만 컨텍스트 창 크기를 초과하는 텍스트를 처리할 때 제한되는 경우가 많습니다. 이러한 한계를 극복하기 위해 연구자들은 LLM의 긴 텍스트 이해 능력을 향상시키기 위해 열심히 노력해 왔습니다. 이는 학술 연구뿐만 아니라 도메인별 지식 이해, 긴 텍스트와 같은 실제 응용 시나리오에도 중요합니다. 대화 생성, 긴 스토리 생성 등도 중요합니다.
본 연구에서 저자는 LLM의 긴 상황 이해 능력을 평가하기 위해 특별히 고안된 새로운 벤치마크 테스트인 LooGLE(Long Context Generic Language Evaluation)을 제안합니다. 이 벤치마크에는 2022년 이후 매우 긴 문서 776개가 포함되어 있으며 각 문서에는 평균 19.3k 단어가 포함되어 있으며 학술, 역사, 스포츠, 정치, 예술, 이벤트 및 엔터테인먼트 등 다양한 분야를 포괄하는 6448개의 테스트 인스턴스가 있습니다.
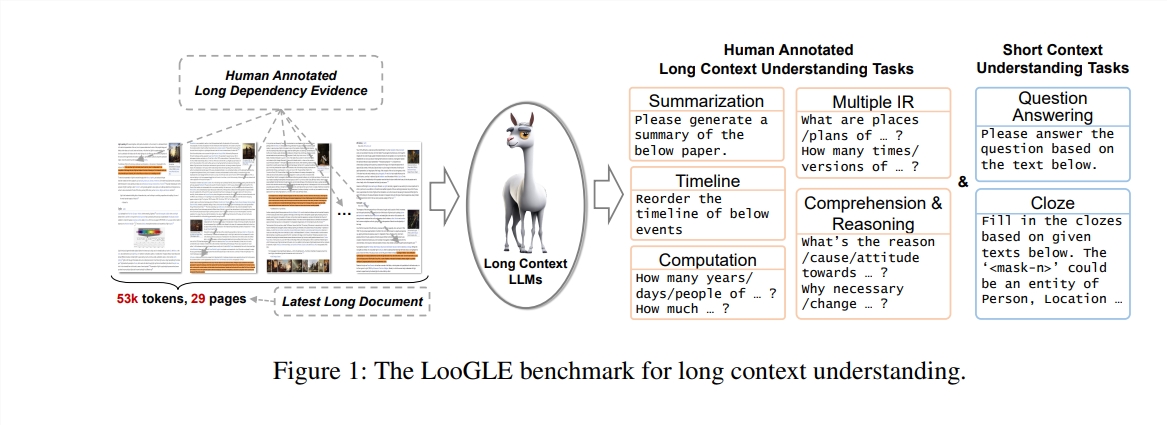
LooGLE의 특징
매우 긴 실제 문서: ooGLE의 문서 길이는 LLM의 컨텍스트 창 크기를 훨씬 초과하므로 모델은 더 긴 텍스트를 기억하고 이해할 수 있어야 합니다.
수동으로 설계된 긴 종속성 작업과 짧은 종속성 작업: 벤치마크 테스트에는 긴 종속성과 긴 종속성 작업을 포함한 7가지 주요 작업이 포함되어 있어 긴 종속성과 짧은 종속성의 내용을 이해하는 LLM의 능력을 평가합니다.
상대적으로 새로운 문서: 모든 문서는 2022년 이후에 출시되었습니다. 이를 통해 대부분의 최신 LLM은 사전 교육 중에 이러한 문서에 노출되지 않았으므로 상황별 학습 기능을 보다 정확하게 평가할 수 있습니다.
도메인 간 공통 데이터: 벤치마크 데이터는 arXiv 논문, Wikipedia 기사, 영화 및 TV 대본 등과 같은 인기 있는 오픈 소스 문서에서 가져옵니다.
연구원들은 8개의 최신 LLM에 대해 종합적인 평가를 실시했으며 그 결과 다음과 같은 주요 결과가 나타났습니다.
상용 모델은 성능 면에서 오픈 소스 모델보다 뛰어납니다.
LLM은 단기 의존성 작업에서는 잘 수행되지만 더 복잡한 장기 의존성 작업에서는 어려움을 겪습니다.
맥락 학습과 사고 사슬을 기반으로 한 방법은 장기적인 맥락 이해에 있어서 제한된 개선만을 제공합니다.
검색 기반 기술은 짧은 질문 응답에서 상당한 이점을 보이는 반면, 최적화된 Transformer 아키텍처 또는 위치 인코딩을 통해 컨텍스트 창 길이를 확장하는 전략은 긴 컨텍스트 이해에 미치는 영향이 제한적입니다.
LooGLE 벤치마크는 장기 컨텍스트 LLM 평가를 위한 체계적이고 포괄적인 평가 체계를 제공할 뿐만 아니라 "진정한 장기 컨텍스트 이해" 기능을 갖춘 모델의 향후 개발을 위한 지침도 제공합니다. 모든 평가 코드는 연구 커뮤니티에서 참조하고 사용할 수 있도록 GitHub에 게시되었습니다.
논문 주소: https://arxiv.org/pdf/2311.04939
코드 주소: https://github.com/bigai-nlco/LooGLE
LooGLE 벤치마크는 LLM의 긴 텍스트 이해 기능을 평가하고 개선하기 위한 중요한 도구를 제공하며, 해당 연구 결과는 자연어 처리 분야의 발전을 촉진하는 데 큰 의미가 있습니다. 연구자들이 제안한 개선 방향은 앞으로 긴 텍스트를 더 잘 처리하기 위해 점점 더 강력한 LLM이 등장할 것이라고 믿습니다.