Apple과 Meta AI는 긴 텍스트 추론 처리에서 LLM(대형 언어 모델)의 효율성을 크게 향상시키도록 설계된 LazyLLM이라는 새로운 기술을 공동 출시했습니다. 현재 LLM이 긴 프롬프트를 처리하는 경우 어텐션 메커니즘의 계산 복잡성은 토큰 수의 제곱에 따라 증가하여 특히 사전 충전 단계에서 속도가 느려집니다. LazyLLM은 계산을 위해 중요한 토큰을 동적으로 선택하여 계산량을 효과적으로 줄이고, Aux Cache 메커니즘을 도입하여 정리된 토큰을 효율적으로 복원함으로써 정확성을 보장하면서 속도를 크게 높입니다.
최근 Apple 연구팀과 Meta AI 연구진은 긴 텍스트 추론에서 LLM(대형 언어 모델)의 효율성을 향상시키는 LazyLLM이라는 새로운 기술을 공동 출시했습니다.
우리 모두 알고 있듯이 현재 LLM은 긴 프롬프트를 처리할 때, 특히 사전 충전 단계에서 느린 속도 문제에 직면하는 경우가 많습니다. 이는 주의를 계산할 때 현대 변환기 아키텍처의 계산 복잡성이 힌트의 토큰 수에 따라 2차적으로 증가하기 때문입니다. 따라서 Llama2 모델을 사용할 때 첫 번째 토큰의 계산 시간은 후속 디코딩 단계의 계산 시간의 21배가 되어 생성 시간의 23%를 차지하는 경우가 많습니다.
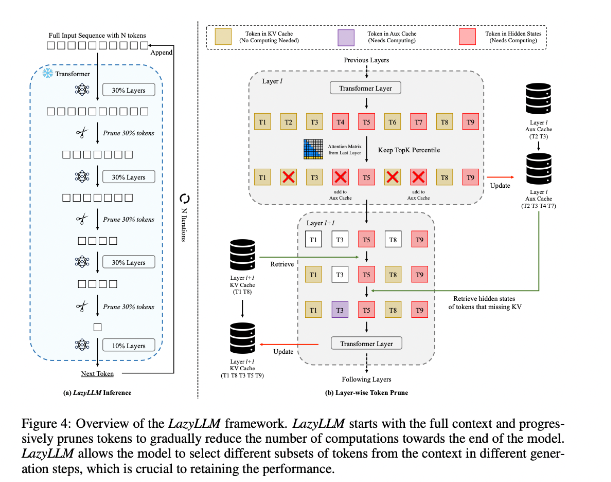
이러한 상황을 개선하기 위해 연구진은 중요한 토큰의 계산 방법을 동적으로 선택하여 LLM 추론을 가속화하는 새로운 방법인 LazyLLM을 제안했습니다. LazyLLM의 핵심은 이전 레이어의 Attention 점수를 기반으로 각 토큰의 중요도를 평가하여 계산량을 점차 줄여나가는 것입니다. 영구 압축과 달리 LazyLLM은 모델 정확성을 보장하기 위해 필요한 경우 정리된 토큰을 복원할 수 있습니다. 또한 LazyLLM은 정리된 토큰의 암시적 상태를 저장하여 이러한 토큰을 효율적으로 복원하고 성능 저하를 방지할 수 있는 Aux 캐시라는 메커니즘을 도입합니다.
LazyLLM은 특히 사전 채우기 및 디코딩 단계에서 추론 속도가 뛰어납니다. 이 기술의 세 가지 주요 장점은 모든 변환기 기반 LLM과 호환되고 구현 중 모델 재교육이 필요하지 않으며 다양한 언어 작업에서 매우 효과적으로 수행된다는 것입니다. LazyLLM의 동적 가지치기 전략을 사용하면 가장 중요한 토큰을 유지하면서 계산량을 크게 줄여 생성 속도를 높일 수 있습니다.
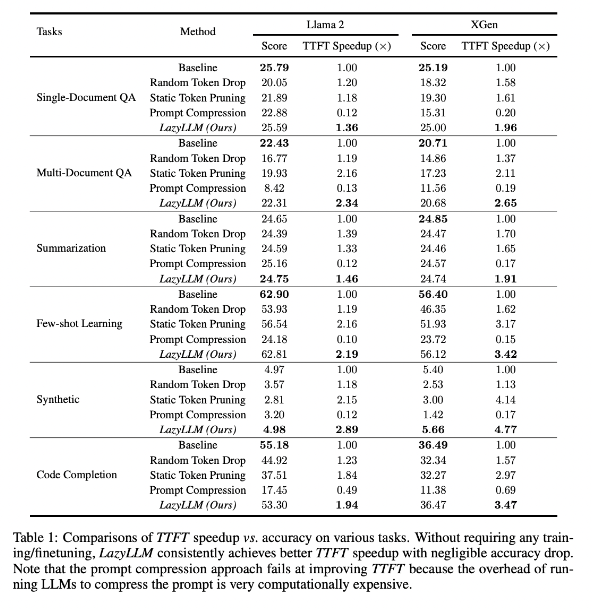
연구 결과에 따르면 LazyLLM은 TTFT 속도가 2.89배(Llama2의 경우) 및 4.77배(XGen의 경우) 증가했으며 정확도는 기준선과 거의 동일하여 여러 언어 작업에서 우수한 성능을 발휘하는 것으로 나타났습니다. 질문 답변, 요약 생성 또는 코드 완성 작업이든 LazyLLM은 더 빠른 생성 속도를 달성하고 성능과 속도 사이의 적절한 균형을 달성할 수 있습니다. 계층별 분석과 결합된 점진적인 가지치기 전략은 LazyLLM 성공의 기반을 마련합니다.
논문 주소: https://arxiv.org/abs/2407.14057
하이라이트:
LazyLLM은 특히 긴 텍스트 시나리오에서 중요한 토큰을 동적으로 선택하여 LLM 추론 프로세스를 가속화합니다.
이 기술은 추론 속도를 획기적으로 향상시킬 수 있으며, 높은 정확도를 유지하면서 TTFT 속도를 최대 4.77배까지 높일 수 있습니다.
LazyLLM은 기존 모델을 수정할 필요가 없고 모든 변환기 기반 LLM과 호환되며 구현이 쉽습니다.
전체적으로 LazyLLM의 출현은 LLM 긴 텍스트 추론 효율성 문제를 해결하기 위한 새로운 아이디어와 효과적인 솔루션을 제공합니다. 속도와 정확성 측면에서 뛰어난 성능은 이것이 미래 대형 모델 애플리케이션에서 중요한 역할을 할 것임을 나타냅니다. 이 기술은 광범위한 응용 전망을 갖고 있으며 향후 개발 및 응용을 기대할 가치가 있습니다.