Apple은 University of Washington 및 기타 기관과 함께 DCLM이라는 강력한 언어 모델을 오픈 소스로 출시했으며, 매개변수 크기는 7억 개, 데이터 토큰은 2조 5천억 개에 달하는 엄청난 양의 훈련 데이터를 제공합니다. DCLM은 효율적인 언어 모델일 뿐만 아니라 더 중요한 것은 언어 모델의 데이터 세트를 최적화하기 위한 "데이터 세트 경쟁"(DataComp)이라는 도구를 제공한다는 것입니다. 이러한 혁신은 모델 성능을 향상시킬 뿐만 아니라 주목할 만한 언어 모델 연구를 위한 새로운 방법과 표준을 제공합니다.
최근 애플의 인공지능팀은 워싱턴대학교 등 여러 기관과 협력해 DCLM이라는 오픈소스 언어 모델을 출시했다. 이 모델에는 7억 개의 매개변수가 있으며 학습 중에 최대 2조 5천억 개의 데이터 토큰을 사용하여 언어를 더 잘 이해하고 생성하는 데 도움을 줍니다.
그렇다면 언어모델이란 간단히 말해서 언어를 분석하고 생성할 수 있는 프로그램으로, 번역, 텍스트 생성, 감성 분석 등 다양한 작업을 완료할 수 있도록 도와주는 프로그램입니다. 이러한 모델이 더 나은 성능을 발휘하려면 고품질 데이터 세트가 필요합니다. 그러나 관련성이 없거나 유해한 콘텐츠를 필터링하고 중복된 정보를 제거해야 하기 때문에 이러한 데이터를 얻고 구성하는 것은 쉬운 작업이 아닙니다.
이러한 문제를 해결하기 위해 Apple 연구팀은 언어 모델용 데이터 세트 최적화 도구인 DCLM(DataComp for Language Models)을 출시했습니다. 그들은 최근 Hugging Face 플랫폼에 DCIM 모델과 데이터 세트를 오픈 소스로 공개했습니다. 오픈 소스 버전에는 DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 및 dclm-baseline-1.0-parquet이 포함됩니다. 연구원은 이 플랫폼을 통해 많은 수의 실험을 수행할 수 있습니다. 효과적인 데이터 랭글링 전략을 찾으세요.
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
DCLM의 핵심 강점은 구조화된 워크플로입니다. 연구자는 필요에 따라 4억 1,200만 개에서 7억 개에 이르는 매개변수 범위에서 다양한 크기의 모델을 선택할 수 있으며, 중복 제거, 필터링 등 다양한 데이터 큐레이션 방법을 실험할 수도 있습니다. 이러한 체계적인 실험을 통해 연구자들은 다양한 데이터 세트의 품질을 명확하게 평가할 수 있습니다. 이는 향후 연구의 기반을 마련할 뿐만 아니라 데이터 세트를 개선하여 모델 성능을 향상시키는 방법을 이해하는 데에도 도움이 됩니다.
예를 들어, 연구팀은 DCLM이 구축한 벤치마크 데이터 세트를 사용해 7억 개의 매개변수로 언어 모델을 훈련했고, MMLU 벤치마크 테스트에서 5샷 정확도 64%를 달성했습니다. 이는 이전보다 6.6 향상된 수치입니다! 최고 수준이며 컴퓨팅 리소스를 40% 적게 사용합니다. DCLM 기본 모델의 성능은 훨씬 더 많은 컴퓨팅 리소스가 필요한 Mistral-7B-v0.3 및 Llama38B와도 비슷합니다.
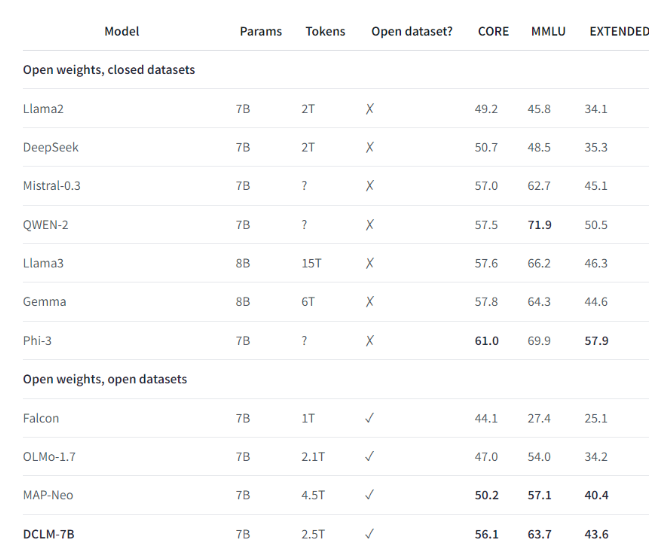
DCLM의 출시는 언어 모델 연구에 대한 새로운 벤치마크를 제공하여 과학자들이 필요한 컴퓨팅 리소스를 줄이면서 모델 성능을 체계적으로 향상시킬 수 있도록 지원합니다.
하이라이트:
1️⃣ Apple AI는 여러 기관과 협력하여 DCLM을 출시하여 강력한 오픈 소스 언어 모델을 만들었습니다.
2️⃣ DCLM은 연구자들이 효과적인 실험을 수행할 수 있도록 표준화된 데이터 세트 최적화 도구를 제공합니다.
3️⃣ 새로운 모델은 계산 리소스 요구 사항을 줄이면서 중요한 테스트에서 상당한 진전을 이루었습니다.
전체적으로 DCLM의 오픈소스는 언어 모델 연구 분야에 새로운 활력을 불어넣었으며, DCLM의 효율적인 모델 및 데이터 세트 최적화 도구는 해당 분야의 보다 빠른 개발을 촉진하고 더욱 강력하고 효율적인 언어 모델의 탄생을 촉진할 것으로 기대됩니다. 앞으로는 DCLM이 더욱 놀라운 연구 결과를 가져올 것으로 기대합니다.