Alibaba Tongyi Qianwen 팀은 오픈 소스 모델의 Qwen2 시리즈를 출시했습니다. 이 시리즈에는 5가지 크기의 사전 훈련 및 지침 미세 조정 모델이 포함되어 있으며 이전 세대 Qwen1.5에 비해 매개변수 수와 성능이 크게 향상되었습니다. Qwen2 시리즈는 영어, 중국어 외에 27개 언어를 지원하는 등 다국어 기능에서도 획기적인 발전을 이루었습니다. 자연어 이해, 코딩, 수학적 능력 등의 측면에서 대형 모델(70B+ 매개변수)이 좋은 성능을 발휘하며, 특히 Qwen2-72B 모델은 성능과 매개변수 수에서 이전 세대를 능가합니다. 이번 출시는 인공지능 기술의 새로운 지평을 열며, 글로벌 AI 적용 및 상용화에 대한 더 넓은 가능성을 제공합니다.
오늘 이른 아침, Alibaba Tongyi Qianwen 팀은 Qwen2 시리즈 오픈 소스 모델을 출시했습니다. 이 모델 시리즈에는 Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B 및 Qwen2-72B의 5가지 크기의 사전 훈련 및 명령 미세 조정 모델이 포함됩니다. 주요 정보는 이 모델의 매개변수 수와 성능이 이전 세대 Qwen1.5에 비해 크게 향상되었음을 보여줍니다.
모델의 다국어 기능을 위해 Qwen2 시리즈는 영어와 중국어를 제외한 27개 언어를 포함하여 데이터 세트의 양과 품질을 높이는 데 많은 노력을 기울였습니다. 비교 테스트 결과, 대형 모델(70B + 매개변수)은 자연어 이해, 코딩, 수학 능력 등에서 좋은 성능을 보였습니다. Qwen2-72B 모델은 성능 및 매개변수 수 측면에서 이전 세대를 능가했습니다.
Qwen2 모델은 기본 언어 모델 평가에서 강력한 기능을 보여줄 뿐만 아니라 명령 조정 모델 평가에서도 인상적인 결과를 달성합니다. 다중 언어 기능은 M-MMLU 및 MGSM과 같은 벤치마크 테스트에서 우수한 성능을 발휘하여 Qwen2 명령 튜닝 모델의 강력한 잠재력을 보여줍니다.
이번에 출시된 Qwen2 시리즈 모델은 인공지능 기술의 새로운 차원을 제시하며, 글로벌 AI 적용 및 상용화에 더 폭넓은 가능성을 제공합니다. 앞으로 Qwen2는 모델 규모와 다중 모드 기능을 더욱 확장하여 오픈 소스 AI 분야의 개발을 가속화할 것입니다.
모델 정보Qwen2 시리즈에는 Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B 및 Qwen2-72B를 포함하여 5가지 크기의 기본 및 명령 조정 모델이 포함되어 있습니다. 아래 표에서는 각 모델의 주요 정보를 설명합니다.
모델 Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# 매개변수 049백만 1억 5400만 707B57.41B72.71B# Non-Emb 매개변수 035백만 131B598백만 5632백만 7021B 품질 보증은 정말 정말 진정한 타이 임베디드입니다. 참 참 거짓 거짓 거짓 거짓 컨텍스트 길이 32천 32천 128천 64천 128천구체적으로 Qwen1.5에서는 Qwen1.5-32B와 Qwen1.5-110B만 GQA(Group Query Attention)를 사용했습니다. 이번에는 모델 추론에서 더 빠른 속도와 더 작은 메모리 공간의 이점을 누릴 수 있도록 모든 모델 크기에 GQA를 적용했습니다. 작은 모델의 경우 큰 희소 임베딩이 모델의 전체 매개변수 중 큰 부분을 차지하므로 연결 임베딩을 적용하는 것을 선호합니다.
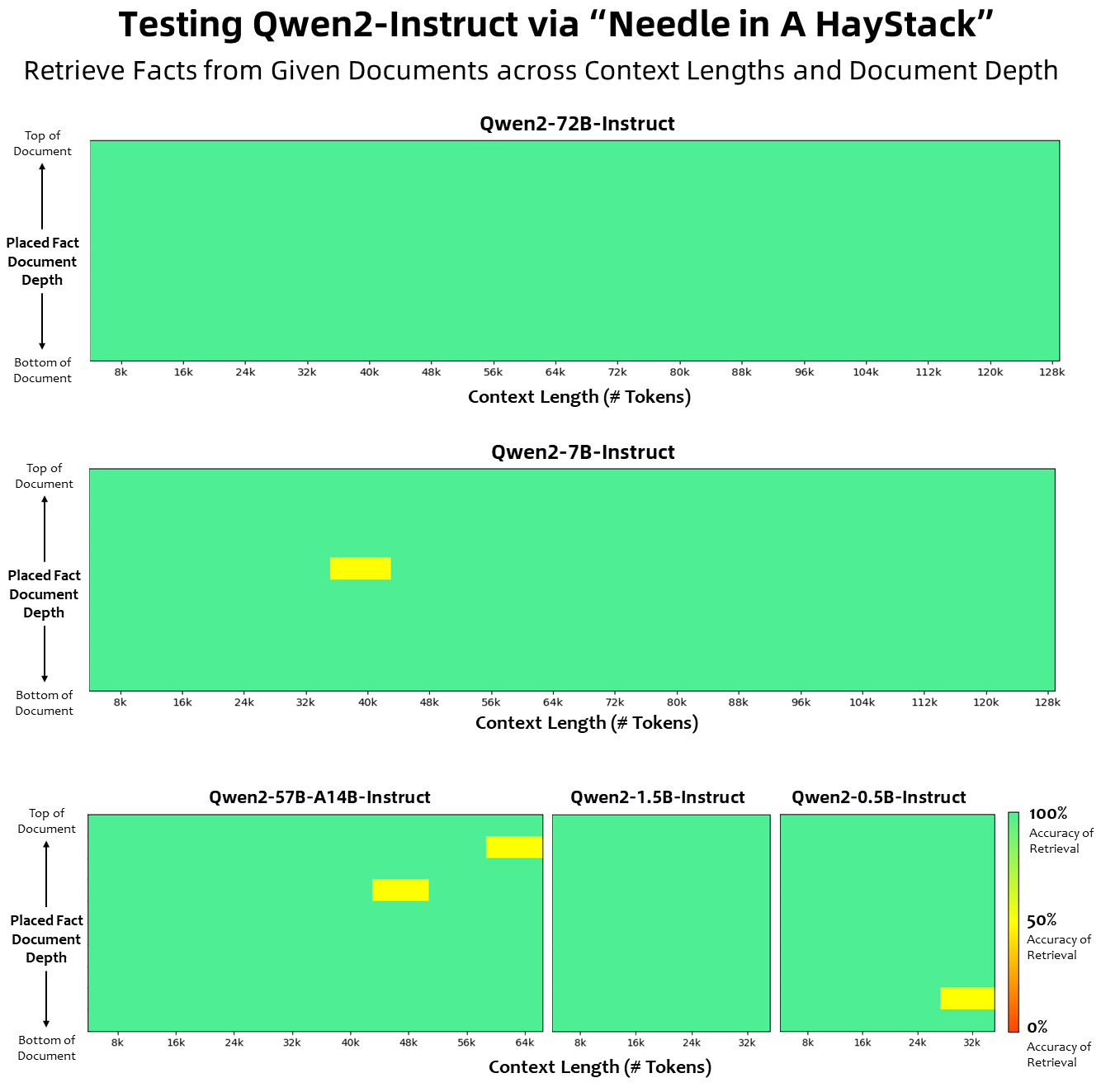
컨텍스트 길이 측면에서 모든 기본 언어 모델은 32K 토큰의 컨텍스트 길이 데이터에 대해 사전 학습되었으며 PPL 평가에서 최대 128K까지 만족스러운 외삽 기능을 관찰했습니다. 그러나 지침 조정 모델의 경우 PPL 평가만으로는 만족하지 않고 긴 컨텍스트를 올바르게 이해하고 작업을 완료할 수 있는 모델이 필요합니다. 표에는 Needlein a Haystack 작업에 대한 평가를 통해 평가된 명령 튜닝 모델의 컨텍스트 길이 기능이 나열되어 있습니다. YARN으로 향상되면 Qwen2-7B-Instruct 및 Qwen2-72B-Instruct 모델 모두 인상적인 기능을 보여주고 최대 128K 토큰의 컨텍스트 길이를 처리할 수 있다는 점은 주목할 가치가 있습니다.
우리는 다국어 기능을 향상시키기 위해 영어와 중국어를 넘어 여러 언어를 포괄하는 사전 훈련 및 교육 조정 데이터 세트의 양과 품질을 높이기 위해 상당한 노력을 기울였습니다. 대규모 언어 모델에는 다른 언어로 일반화할 수 있는 고유한 기능이 있지만 우리는 훈련에 27개의 다른 언어를 포함할 것을 명시적으로 강조합니다.
지역 언어 서유럽 독일어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 네덜란드 동부 및 중앙 유럽 러시아어, 체코어, 폴란드어 중동 아랍어, 페르시아어, 히브리어, 터키어 동아시아 일본어, 한국어 동남아 베트남어, 태국어, 인도네시아어, 말레이어, 라오스어, 버마어, 세부아노어, 크메르어, 타갈로그어 남아시아 힌디어, 벵골어, 우르두어또한 다국어 평가에서 자주 발생하는 트랜스코딩 문제를 해결하기 위해 많은 노력을 기울였습니다. 따라서 이 현상을 처리하는 모델의 능력이 크게 향상되었습니다. 일반적으로 언어 간 코드 전환을 유도하는 단서를 사용한 평가를 통해 관련 문제가 크게 감소한 것으로 확인되었습니다.
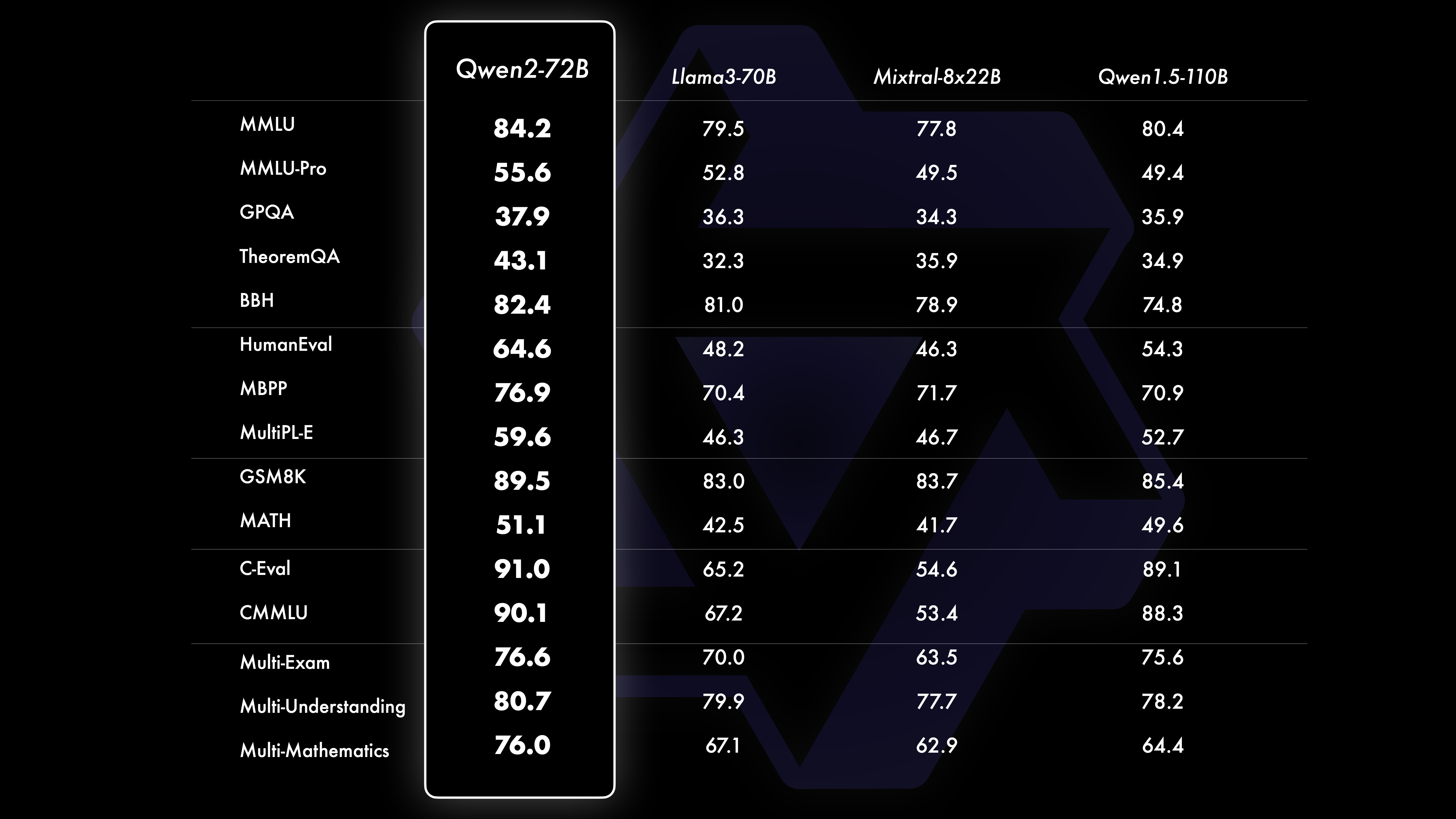
성능비교 테스트 결과, Qwen1.5에 비해 대규모 모델(70B+ 매개변수)의 성능이 크게 향상되었음을 보여줍니다. 이 테스트는 대형 모델 Qwen2-72B를 중심으로 이루어졌습니다. 기본 언어 모델 측면에서 자연어 이해, 지식 습득, 프로그래밍 능력, 수학 능력, 다국어 능력 및 기타 능력 측면에서 Qwen2-72B와 현재 최고의 개방형 모델의 성능을 비교했습니다. 신중하게 선택된 데이터 세트와 최적화된 훈련 방법 덕분에 Qwen2-72B는 Llama-3-70B와 같은 주요 모델보다 성능이 뛰어나며 더 적은 수의 매개변수로 이전 세대 Qwen1.5-보다 성능이 뛰어납니다.
광범위한 대규모 사전 훈련을 거친 후 Qwen의 지능을 더욱 강화하고 인간과 더 가까워지기 위해 사후 훈련을 수행합니다. 이 프로세스는 코딩, 수학, 추론, 지침 따르기 및 다중 언어 이해와 같은 영역에서 모델의 기능을 더욱 향상시킵니다. 또한 모델의 출력을 인간의 가치와 일치시켜 모델이 유용하고 정직하며 무해하다는 것을 보장합니다. 우리의 훈련 후 단계는 확장 가능한 훈련과 최소한의 인간 주석 원칙으로 설계되었습니다. 구체적으로 수학을 위한 거부 샘플링, 코딩 및 지시 따르기를 위한 실행 피드백, 창의적 글쓰기를 위한 역번역 등 다양한 자동 정렬 전략을 통해 고품질의 신뢰할 수 있고 다양하며 창의적인 프레젠테이션 데이터 및 선호도 데이터를 얻는 방법을 연구합니다. , 확장 가능한 롤플레잉 감독 등. 교육의 경우 감독된 미세 조정, 보상 모델 교육 및 온라인 DPO 교육을 조합하여 사용합니다. 또한 정렬 세금을 최소화하기 위해 새로운 온라인 병합 최적화 프로그램을 사용합니다. 이러한 결합된 노력은 아래 표에 표시된 것처럼 모델의 기능과 지능을 크게 향상시킵니다.
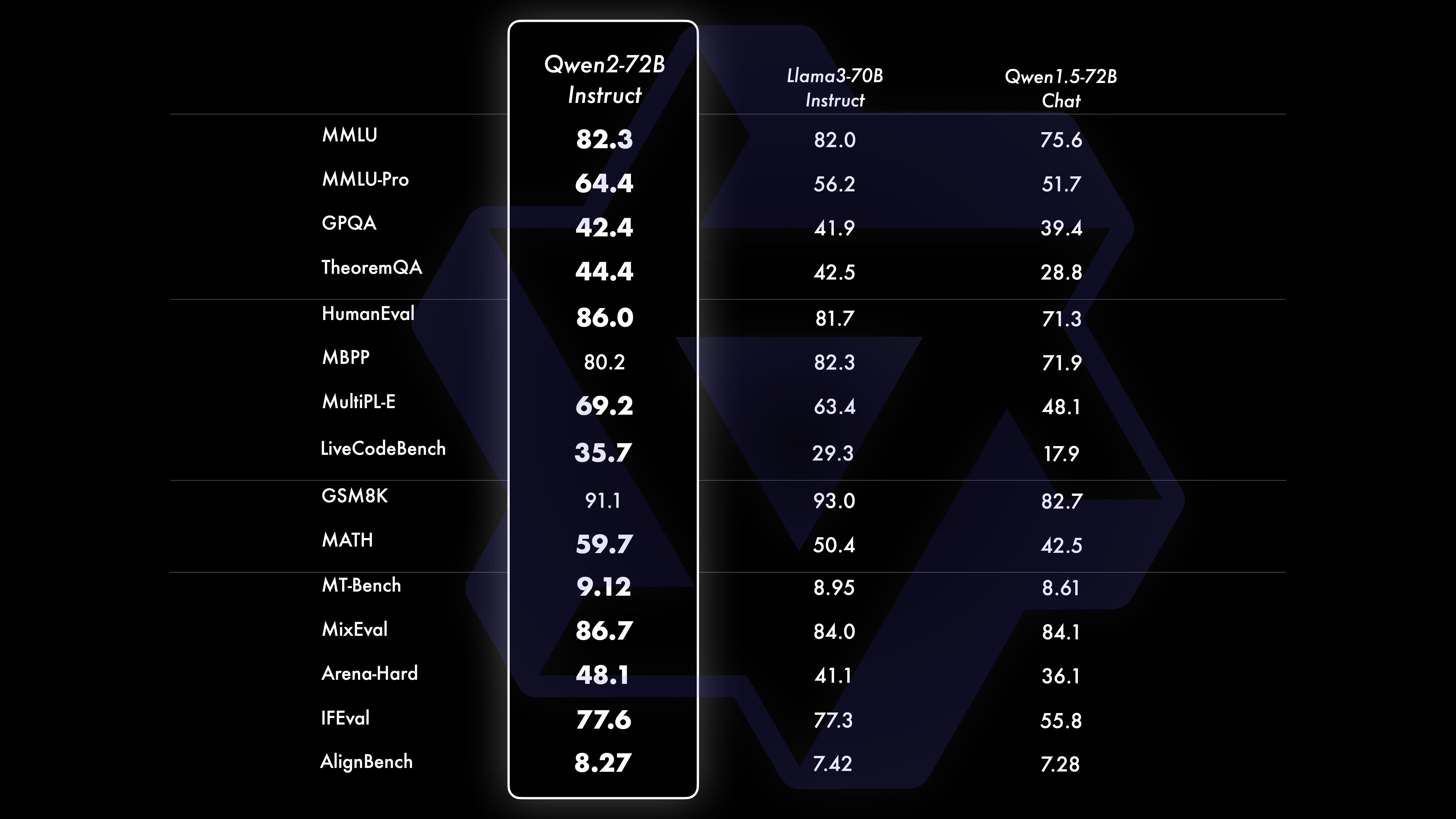
우리는 다양한 분야의 16개 벤치마크를 포괄하여 Qwen2-72B-Instruct에 대한 종합적인 평가를 수행했습니다. Qwen2-72B-Instruct는 더 나은 능력을 얻는 것과 인간의 가치에 부합하는 것 사이에서 균형을 유지합니다. 특히, Qwen2-72B-Instruct는 모든 벤치마크에서 Qwen1.5-72B-Chat보다 훨씬 뛰어난 성능을 발휘하며 Llama-3-70B-Instruct에 비해 경쟁력 있는 성능을 달성합니다.
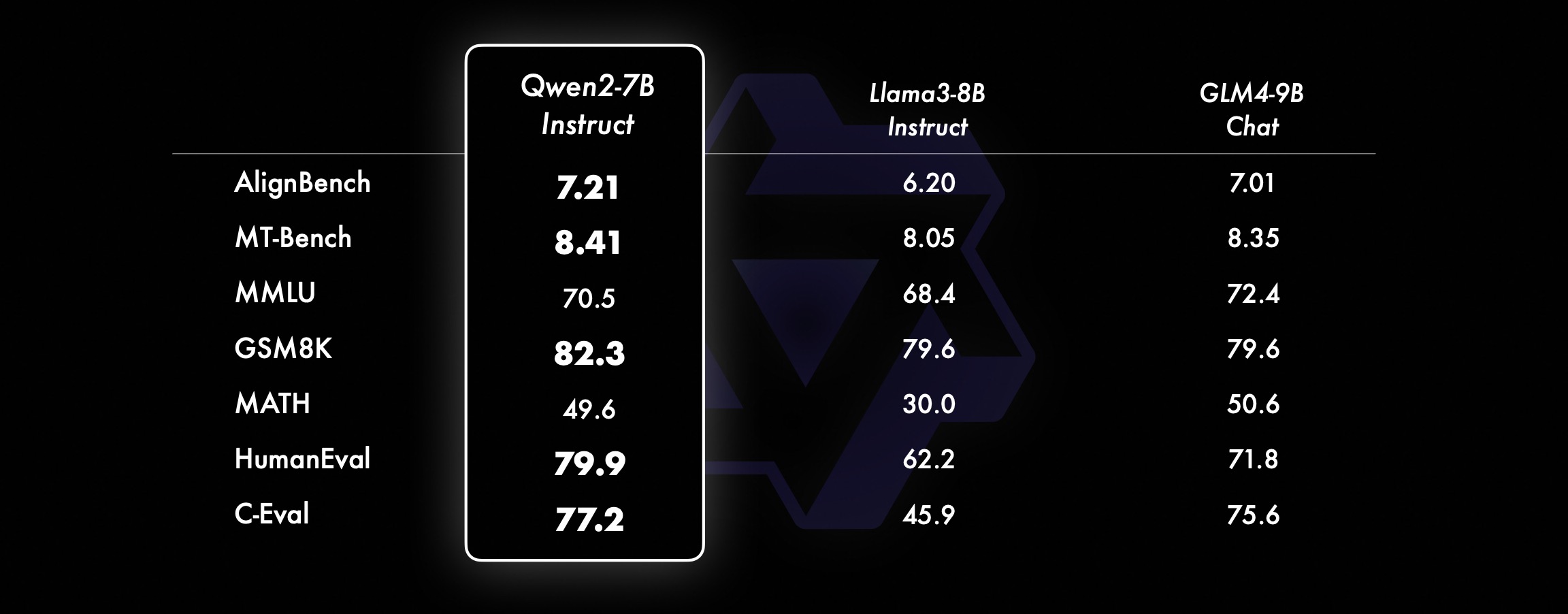
소형 모델의 경우 Qwen2 모델은 유사하거나 더 큰 크기의 SOTA 모델보다 성능이 뛰어납니다. 방금 출시된 SOTA 모델과 비교해 Qwen2-7B-Instruct는 다양한 벤치마크 테스트, 특히 인코딩 및 중국어 관련 지표에서 여전히 장점을 보여줍니다.
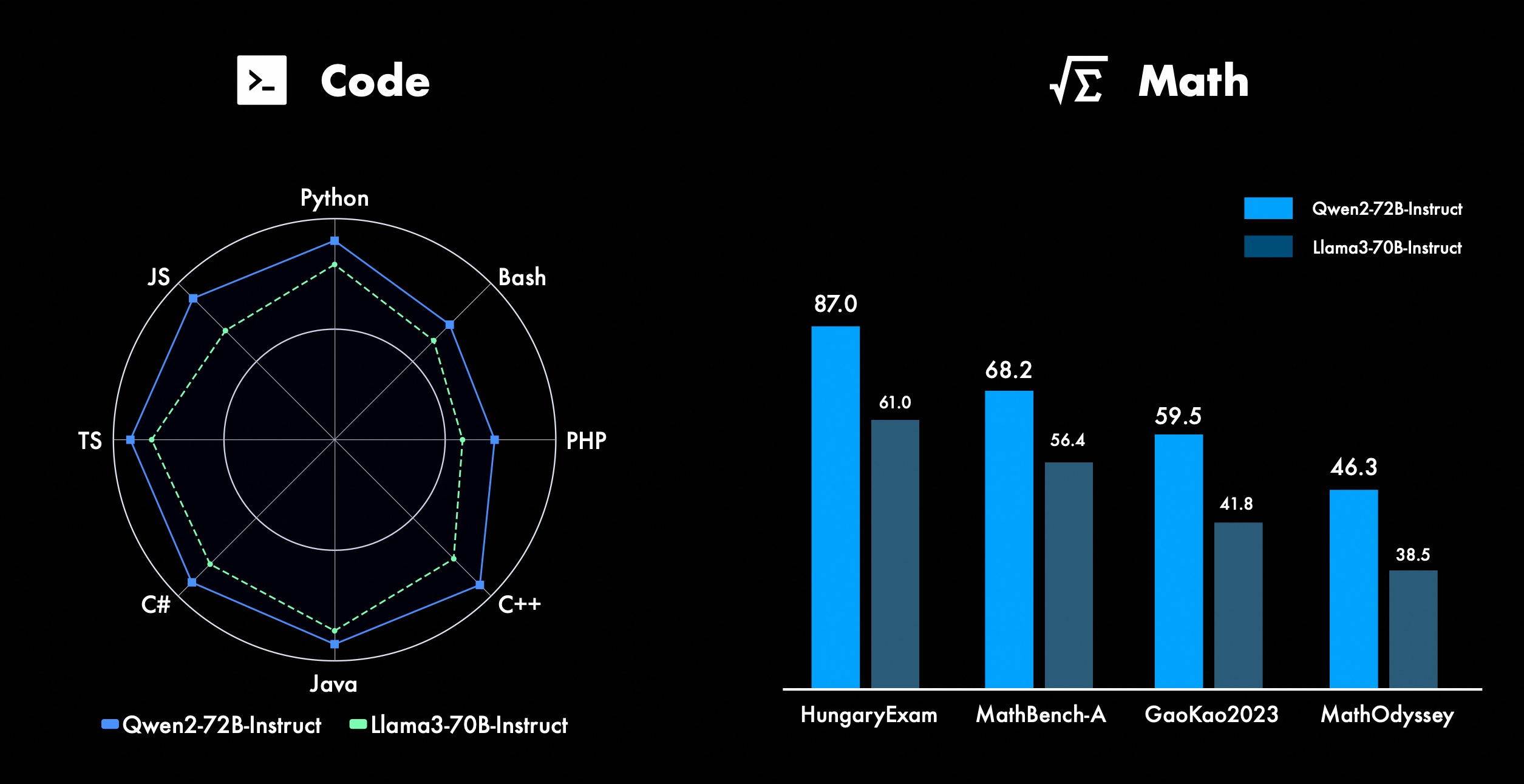
우리는 특히 코딩과 수학 분야에서 Qwen의 고급 기능을 개선하기 위해 지속적으로 노력하고 있습니다. 코딩 측면에서 CodeQwen1.5의 코드 교육 경험과 데이터를 성공적으로 통합하여 Qwen2-72B-Instruct가 다양한 프로그래밍 언어에서 상당한 개선을 달성했습니다. 수학에서 Qwen2-72B-Instruct는 광범위한 고품질 데이터 세트를 활용하여 수학적 문제를 해결하는 향상된 기능을 보여줍니다.
Qwen2에서 모든 명령 튜닝 모델은 32k 길이 컨텍스트에서 훈련되고 YARN 또는 Dual Chunk Attention과 같은 기술을 사용하여 더 긴 컨텍스트 길이로 추정됩니다.
아래 그림은 Needle in a Haystack에 대한 테스트 결과를 보여줍니다. Qwen2-72B-Instruct는 고유한 강력한 성능과 함께 128k 컨텍스트에서 정보 추출 작업을 완벽하게 처리할 수 있다는 점에 주목할 가치가 있습니다. . 경우에는 긴 텍스트 작업을 처리하기 위한 첫 번째 선택이 됩니다.
또한, 시리즈의 다른 모델의 인상적인 기능에 주목할 가치가 있습니다. Qwen2-7B-Instruct는 최대 128k의 컨텍스트를 거의 완벽하게 처리하고, Qwen2-57B-A14B-Instruct는 최대 64k의 컨텍스트를 관리하며, 시리즈는 두 가지입니다. 더 작은 모델은 32k 컨텍스트를 지원합니다.
긴 컨텍스트 모델 외에도 최대 1백만 개의 태그가 포함된 문서를 효율적으로 처리하기 위한 프록시 솔루션을 오픈 소스로 제공했습니다. 자세한 내용은 이 주제에 대한 전용 블로그 게시물을 참조하세요.
아래 표는 네 가지 범주의 다국어 안전하지 않은 쿼리(불법 활동, 사기, 음란물, 사적 폭력)에 대해 대규모 모델에서 생성된 유해한 응답의 비율을 보여줍니다. 테스트 데이터는 Jailbreak에서 제공되며 평가를 위해 여러 언어로 번역됩니다. 우리는 Llama-3가 다국어 단서를 효율적으로 처리하지 못하므로 비교에 포함하지 않는다는 것을 발견했습니다. 유의성 테스트(P_value)를 통해 Qwen2-72B-Instruct 모델의 보안 성능이 GPT-4와 동일하며 Mistral-8x22B 모델보다 훨씬 우수하다는 것을 확인했습니다.
언어 불법 활동 사기 포르노 개인 정보 보호 폭력 GPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Chinese0%13%0 %0%17%0%43%47%53%0%10%0%English0%7%0%0%23% 0%37%67%63%0%27%3%미수금0%13%0% 0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%프랑스0%3%0% 3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%point0%7%0%3% 7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0%4% 11%0%22%26%22%0%0%0%average0%8%0% 3%11%2%27%39%31%3%16%2% 개발에 Qwen2 사용현재 모든 모델은 Hugging Face와 ModelScope로 출시되었습니다. 모델 카드를 방문하시면 각 모델의 자세한 사용 방법과 특징, 성능, 기타 정보를 확인하실 수 있습니다.
오랫동안 많은 친구들이 미세 조정(Axolotl, Llama-Factory, Firefly, Swift, XTuner), 정량화(AutoGPTQ, AutoAWQ, Neural Compressor), 배포(vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI), API 플랫폼(Together, Fireworks, OpenRouter), 로컬 실행(MLX, Llama.cpp, Ollama, LM Studio), 에이전트 및 RAG 프레임워크(LlamaIndex, CrewAI, OpenDevin), 평가(LMSys, OpenCompass, Open LLM Leaderboard), 모델 교육(Dolphin, Openbuddy) 등 타사 프레임워크와 함께 Qwen2를 사용하는 방법은 해당 문서와 공식 문서를 참조하세요.

우리가 언급하지 않았지만 Qwen에 기여한 많은 팀과 개인이 있습니다. 우리는 그들의 지원에 진심으로 감사드리며, 우리의 협력이 오픈 소스 AI 커뮤니티의 연구 개발을 촉진할 수 있기를 바랍니다.
특허이번에는 모델의 권한을 다른 권한으로 변경해 보겠습니다. Qwen2-72B 및 해당 명령 튜닝 모델은 여전히 원래 Qianwen 라이센스를 사용하는 반면 Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B 및 Qwen2-57B-A14B를 포함한 다른 모든 모델은 Apache2.0으로 전환되었습니다!우리는 믿습니다 우리 모델을 커뮤니티에 추가로 개방하면 전 세계적으로 Qwen2의 적용 및 상용화를 가속화할 수 있습니다.
Qwen2의 다음 단계는 무엇입니까?우리는 모델 확장과 최근 데이터 확장을 더 자세히 탐색하기 위해 더 큰 Qwen2 모델을 훈련하고 있습니다. 또한 Qwen2 언어 모델을 다중 모드로 확장하여 시각적 및 오디오 정보를 이해할 수 있습니다. 가까운 미래에 우리는 오픈소스 AI를 가속화하기 위해 계속해서 오픈소스 새 모델을 선보일 예정입니다. 계속 지켜봐 주시기 바랍니다!
인용하다곧 Qwen2에 대한 기술 보고서를 공개할 예정입니다. 견적을 환영합니다!
@article{qwen2, 부록 기본 언어 모델 평가기본모델의 평가는 주로 자연어 이해, 일반 질의응답, 코딩, 수학, 과학지식, 추론, 다국어 능력 등 모델 성능에 중점을 둡니다.
평가된 데이터 세트는 다음과 같습니다.
영어 과제: MMLU(5회), MMLU-Pro(5회), GPQA(5회), Theorem QA(5회), BBH(3회), HellaSwag(10회), Winogrande(5회), TruthfulQA( 0회), ARC-C(25회)
코딩 작업: EvalPlus(0-shot)(HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E(0-shot)(Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
수학 과제: GSM8K(4회), MATH(4회)
중국 과제: C-Eval(5발), CMMLU(5발)
다국어 과제: 다중 시험(M3Exam 5회, IndoMMLU 3회, ruMMLU 5회, mmMLU 5회), 다중 이해(BELEBELE 5회, XCOPA 5회, XWinograd 5회, XStoryCloze 0회, PAWS-X 5회) , 다중 수학(MGSM 8회), 다중 번역(Flores-1015회)
Qwen2-72B 성능 데이터 세트 DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BArchitecture 교육부DenseDenseDenseDense#활성화된 매개변수 21B39B70B72B110B72B#매개변수 236B140B70B72B110B 72B 영어 Mohrman ·Lu 78.577.879.577.580.484.2MMLU-Professional Edition-49.552. 845.849.455.6품질보증-34.336.336.335.937.9정리Q&A-35.932.329.334.943.1바이비헤이 78.978.981.065.574.88 2.4시라스와그 87.888.788.086. 587.6 대형 윈도우 84.885.085.383.083.585.1ARC-C70.070.768.865.969. 668.9 정직한 Q&A 42.251.045.659.649.654.8 코딩인력평가 45.746.348.246.354.364.6 말레이시아 공공서비스부 73 .971.770.466.970.976.9 평가 55.054.154.852.957.765. 4 다양함 44.446.746.341.852.759.6 수학 GSM8K79. 283.783.079.585.489.5 수학 43.641.742.534.149.651.1 중국어 C-평가 81.754.665. 284.189.191.0 캐나다 몬트리올 대학교 84.053 .467.283.588.390.1다양한 언어 및 다중 시험 67.563.570.066.475.676.6다중 이해 77.077.779.978.278.280.7다중 수학 58.862.967.161.764.476.0다중 번역 36.023.338.035.636.2 37.8Qwen2-57B-A14B 데이터 세트 Jabba Mixtral-8x7B Instrument-1.5-34BQwen1.5-32 BQwen2-57B-A14B 아키텍처 MoE MoE 밀도 밀도 MoE #활성화 매개변수 12B12B34B32B14B #매개변수 52B47B34B32B57B 영어 Moleman Lu 67.471.877.174.376.5MMLU - Professional Edition - 41.048.344.043.0 품질 보증 - 29.2 - 30.834.3 정리 Q&A - 23.2 - 28.833.5 바이베이 블랙 45.450.376.466.867.0 시엘라 Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 정직한 질문과 답변 46.451.153.957.457.7 코딩인력평가 29.337.246.343.353 .0 말레이시아 공공 서비스 - 63.965.564.271.9 평가 - 46.451 .950.457.2 다양함 - 39.03 9.538.549 .8 수학 GSM8K59.962.582.776.880.7 수학-30.841.736.143.0 중국어 C-평가---83.587.7 캐나다 몬트리올 대학교--84.882.388.5 다국어 그리고 다중시험 - 56.158.361.665.5 다자간이해 -70.773.976.577.0 다중수학 -45.049.356.162.3 다중번역 -29.830.033.534.5Qwen2-7B Dataset Mistral -7B Jemma -7B Camel -3-8BQwen1.5 -7BQwen2-7B# 매개변수 7.2B850백만 8.0B7.7B7.6B# 비-emb 매개변수 7.0B780백만 7.0B650백만 650백만 영어 Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 품질 보증 24.72 5 .725.826. 731.8 정리 Q&A 19.221.522.114.231.1 바이베이 블랙 56.155.157.740.262.6 시라스와거 83.282.282.178.580.7 위노그랜드 78.479.077.471.377.0ARC-C60.061.159 54.260.6정직한 질문과 답변 42.244 .844.051.154.2 코딩인력평가 29.337.233.536 .051.2 공공 서비스 말레이시아 51.150.653.951.665.9 평가 36.439.640.340.054.2 다중 29.429.722.628.146.3 수학 GSM8K52.246.456.0 62.579.9 수학 13.124.320.520. 344.2 중국 인간 C-평가 47.443.649.574.183.2 Université de Montréal , 캐나다 -- 50.873.183.9 다국어 다중 시험 47.142.752.347.759.2 다중 이해 63.358.368.667.672.0 다변량 수학 26.339.136.337.357.5 다중 번역 23.331.231 .928.431.5Qwen2 - 0.5B 및 Qwen2-1.5B 데이터 세트 Phi-2Gemma -2B 최소 CPM Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B# 비Emb 매개변수 2억 5천만 2.0B2.4B1.3B035백만 1.3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional-15.9--14.721.8 정리 Q&A----8.915.0 인력 평가 47.622.050.020.122.031.1 말레이시아 공공 서비스 부서 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 수학 3.511.810.210.110.721. 7 바이비 블랙 43.435.236.924.228.437. 2 Shiela Swag 73.171.468.361.449.366.6 Winogrand 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 정직한 Q&A 44.533.1-39.439.745.9C - 평가 23.428.051. 159.758.270.6 몬트리올 대학교, 캐나다 24.2 - 51.157.855.170.3 명령 튜닝 모델 평가 Qwen2-72B - 안내 데이터 세트 Camel - 3-70B - 안내 Qwen1.5-72B - 채팅 Qwen2-72B - 안내 영어 Mohr Man Lu 82.075.682.3MMLU - Professional Edition 56.251. 764.4 품질 보증 41.939.442.4 정리 Q&A 42.528.844.4MT - 벤치8.958.619.12 경기장 - 하드 41.136.148.1 IFEval(신속한 엄격한 액세스) 77.355.877.6 코딩 인력 평가 81.771.386.0 공공 서비스 말레이시아 82 .371.980.2 다중 63.448.169.2 평가 75.266.979.0 라이브 코드 테스트 29.317.935.7 수학 GSM 8K93.082.7 91.1 수학 50.442.559.7 중국어 C-평가 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-Instruction DatasetMix tral-8x7B-Instruct-v0.1Yi-1.5 -34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - 지침 아키텍처 교육부 Dense Dense 교육부 #활성화 매개변수 12B34B32B14B #매개변수 47B34B32B57B 영어 Mohr Man Lu 71.476.874.875.4MMLU - Professional Edition 43.352.346.452. 8 품질 보증 -- 30.834.3 정리 질문 및 답변 - -30.933.1MT-Bench8.308.508.308.55 코딩 인력 평가 45.175.268.379.9 공공 서비스 말레이시아 59.574.667.970.9 다양 --50.766.4 평가 48.5-63.671.6 라이브 코드 테스트 12.3-15.225.5 수학 GSM8K65.790.283.679.6 수학 30.750.142.449.1 중국어 C-평가--76.780.5AlignBench5.707.207.197.36Qwen2-7B-Guide 데이터 세트 Camel-3-8B-Guide Yi-1.5- 9B -Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Guide 영어 Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 품질 보증 34.2--27.825.3 정리 Q&A 23.0- -14.125 .3MT-Bench8.058.208.357.608.41 코딩 인도주의 62.266.571.846.379.9 공공 서비스 말레이시아 67.9--48.967.2 다중 48.5--27.259.1 평가 60.9--44.870.3 라이브 코드 테스트 17.3-- 26. 6 수학 GSM8K79.684.879.660.382.3 수학 30.047.750.623.249.6 중국어 C-평가 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct 및 Qwen2-1.5B-Instruct 데이터 세트 Qwen 1. 5- 0.5B-Chat Qwen2-0.5B-가이드 Qwen1.5-1.8B-Chat Qwen2-1.5B-가이드 Morman Lu35.037.943.752.4 인력 평가 9.117.125.037.8GSM8K11.340.135.361.6C-평가 37.245.255.363. 8IF평가( 엄격한 액세스를 위한 프롬프트) 14.620.016.829.0 명령은 모델의 다중 언어 기능을 조정합니다.여러 언어 간 공개 벤치마크와 인간 평가를 통해 Qwen2 명령어 튜닝 모델을 다른 최신 LLM과 비교합니다. 기준선의 경우 2개의 평가 데이터 세트에 대한 결과를 제시합니다.
Okapi의 M-MMLU: 다국어 일반 지식 평가(평가를 위해 ar, de, es, fr, it, nl, ru, uk, vi, zh의 하위 집합을 사용함) MGSM: 독일어, 영어, 스페인어, 프랑스어, 수학 평가 일본어, 러시아어, 태국어, 중국어, 브라질어결과는 각 벤치마크에 대해 언어별로 평균을 낸 것이며 다음과 같습니다.
예시 M-MMLU(5발) MGSM(0발, CoT) 독점 LLM GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 오픈 소스 LL.M 명령-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B -가이드 60.057.0Qwen2-57B-A14B-가이드 68.074.0Qwen2-72B-가이드 78.086.6수동 평가를 위해 10개 언어 ar, es, fr, ko, th, vi, pt, id , ja 및 ru(점수 범위는 1~5):
모델 미수금 스페인어 프랑스어 Corri Six Points ID Jiaru Average Claude-3-Works-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3 93. 724.324.09 GPT-4-터보- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-가이드 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 53.923 .943.873.833.953.553.773.063.633.71GPT-3.5-터보-11062.524. 073.472.373.382.903.373.562.753.243.16작업 유형별로 그룹화하면 결과는 다음과 같습니다.
모델 지식 이해 Claude-3-Works-202402293.644.454.423.81GPT-4o-05133.764.354.453.53GPT-4-Turbo-04093.424.294.353.58Qwen2-72B-Guide3.414.074.363.61GPT - 4-06133.424. 32GPT-3.5-터보-11063.373.673.892.97이러한 결과는 Qwen2 명령어 튜닝 모델의 강력한 다국어 기능을 보여줍니다.
Alibaba의 오픈 소스 Qwen2 시리즈 모델은 성능과 다국어 기능을 크게 향상시켜 오픈 소스 AI 커뮤니티에 중요한 기여를 했습니다. 앞으로도 Qwen2는 계속해서 모델 규모와 다중 모드 기능을 개발하고 더욱 확장할 예정이며, 이는 기대할만한 가치가 있습니다.