Artigo: Sobre a generalização zero-shot em tempo de teste de modelos de linguagem de visão: realmente precisamos de aprendizado imediato? .
Autores: Maxime Zanella, Ismail Ben Ayed.
Este é o repositório oficial do GitHub para nosso artigo aceito no CVPR '24. Este trabalho apresenta o método MeanShift Test-time Augmentation (MTA), aproveitando modelos de Visão-Linguagem sem a necessidade de aprendizado imediato. Nosso método aumenta aleatoriamente uma única imagem em N visualizações aumentadas e, em seguida, alterna entre duas etapas principais (consulte mta.py e detalhes na seção de código):
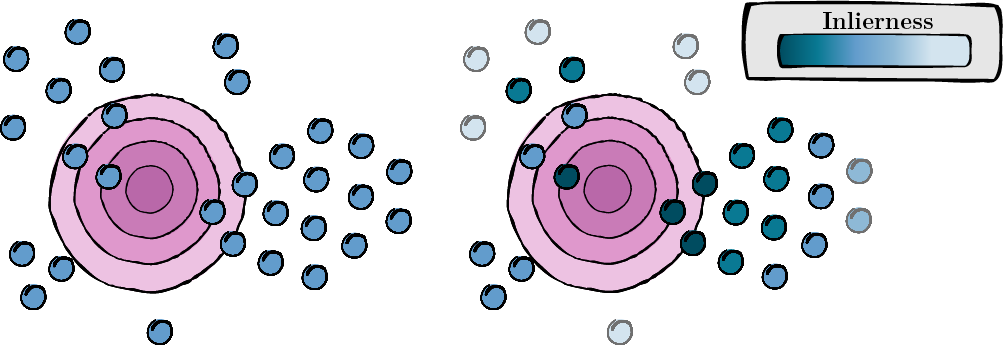
Esta etapa envolve o cálculo de uma pontuação para cada visualização aumentada para avaliar sua relevância e qualidade (pontuação de inlierness).
Figura 1: Cálculo da pontuação para cada visualização aumentada.
Com base nas pontuações calculadas na etapa anterior, buscamos a moda dos pontos de dados (MeanShift).
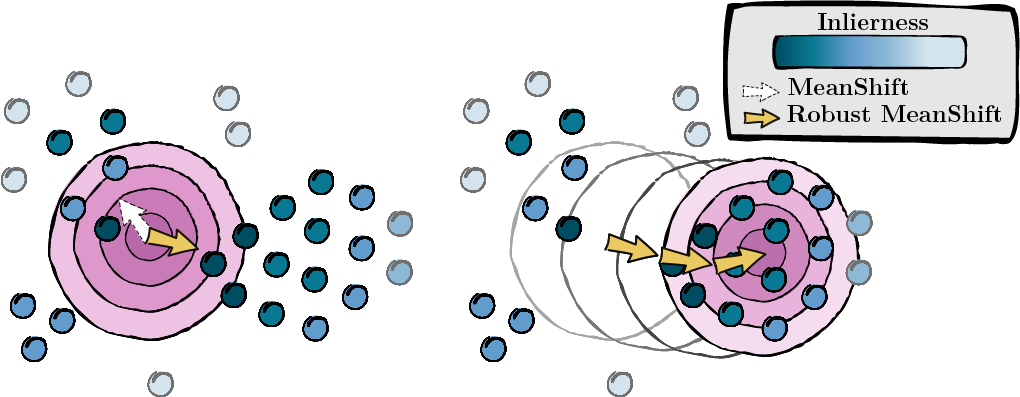
Figura 2: Busca da moda, ponderada pelas pontuações de inlierness.
Seguimos a instalação e o pré-processamento do TPT. Isso garante que seu conjunto de dados seja formatado adequadamente. Você pode encontrar o repositório deles aqui. Se for mais conveniente, você pode alterar os nomes das pastas de cada conjunto de dados no dicionário ID_to_DIRNAME em data/datautils.py (linha 20).
Execute o MTA no conjunto de dados ImageNet com uma semente aleatória de 1 e prompt 'a photo of a' digitando o seguinte comando:
python main.py --data /path/to/your/data --mta --testsets I --seed 1Ou os 15 conjuntos de dados de uma vez:
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1Mais informações sobre o procedimento em mta.py.
gaussian_kernelsolve_mtay ) uniformemente.Se você achar este projeto útil, cite-o da seguinte forma:
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}Expressamos nossa gratidão aos autores do TPT por sua contribuição de código aberto. Você pode encontrar o repositório deles aqui.