ai toolkit
1.0.0
Este é meu repositório de pesquisa. Faço muitas experiências com isso e é possível que quebre coisas. Se algo quebrar, verifique um commit anterior. Este repositório pode treinar muitas coisas e é difícil acompanhar todas elas.
Meu trabalho neste projeto não seria possível sem o incrível apoio de Glif e de todos da equipe. Se você quiser me apoiar, apoie Glif. Cadastre-se no site, junte-se a nós no Discord, siga-nos no Twitter e venha fazer algumas coisas legais com a gente
Requisitos:
Linux:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python3 -m venv venv
source venv/bin/activate
# .venvScriptsactivate on windows
# install torch first
pip3 install torch
pip3 install -r requirements.txtWindows:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
. v env S cripts a ctivate
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txtPara começar rapidamente, confira o tutorial @araminta_k sobre Finetuning Flux Dev em um 3090 com 24 GB VRAM.
Atualmente, você precisa de uma GPU com pelo menos 24 GB de VRAM para treinar o FLUX.1. Se você estiver usando-o como GPU para controlar seus monitores, provavelmente precisará definir o sinalizador low_vram: true no arquivo de configuração em model: . Isso quantizará o modelo na CPU e permitirá que ele seja treinado com monitores conectados. Os usuários conseguiram que ele funcionasse no Windows com WSL, mas há alguns relatos de um bug durante a execução nativa no Windows. Eu só testei no Linux por enquanto. Isso ainda é extremamente experimental e muitos truques e quantizações tiveram que acontecer para que ele coubesse em 24 GB.
FLUX.1-dev possui uma licença não comercial. O que significa que qualquer coisa que você treinar herdará a licença não comercial. Também é um modelo fechado, portanto é necessário aceitar a licença em HF antes de utilizá-lo. Caso contrário, isso falhará. Aqui estão as etapas necessárias para configurar uma licença.
.env na raiz desta pasta.env assim HF_TOKEN=your_key_hereFLUX.1-schnell é o Apache 2.0. Qualquer pessoa treinada nele pode ser licenciada como você quiser e não requer um HF_TOKEN para treinar. No entanto, é necessário um adaptador especial para treinar, ostris/FLUX.1-schnell-training-adapter. Também é altamente experimental. Para melhor qualidade geral, recomenda-se o treinamento em FLUX.1-dev.
Para usá-lo, você só precisa adicionar o assistente à seção model do seu arquivo de configuração, assim:
model :
name_or_path : " black-forest-labs/FLUX.1-schnell "
assistant_lora_path : " ostris/FLUX.1-schnell-training-adapter "
is_flux : true
quantize : trueVocê também precisa ajustar as etapas da amostra, pois o schnell não exige tantos
sample :
guidance_scale : 1 # schnell does not do guidance
sample_steps : 4 # 1 - 4 works wellconfig/examples/train_lora_flux_24gb.yaml ( config/examples/train_lora_flux_schnell_24gb.yaml para schnell) para a pasta config e renomeie-o whatever_you_want.ymlpython run.py config/whatever_you_want.ymlUma pasta com o nome e a pasta de treinamento do arquivo de configuração será criada quando você iniciar. Ele terá todos os pontos de verificação e imagens. Você pode interromper o treinamento a qualquer momento usando ctrl+c e quando você retomar, ele retomará do último ponto de verificação.
IMPORTANTE. Se você pressionar crtl+c enquanto estiver salvando, provavelmente corromperá esse ponto de verificação. Então espere até terminar de salvar
Por favor, não abra um relatório de bug, a menos que seja um bug no código. Você está convidado a entrar no meu Discord e pedir ajuda lá. No entanto, evite me enviar PM diretamente com perguntas ou suporte geral. Pergunte no discord e responderei quando puder.
Para começar a treinar localmente com uma interface de usuário personalizada, depois de seguir as etapas acima e ai-toolkit estar instalado:
cd ai-toolkit # in case you are not yet in the ai-toolkit folder
huggingface-cli login # provide a `write` token to publish your LoRA at the end
python flux_train_ui.py Você instanciará uma UI que permitirá fazer upload de suas imagens, legendá-las, treinar e publicar seu LoRA 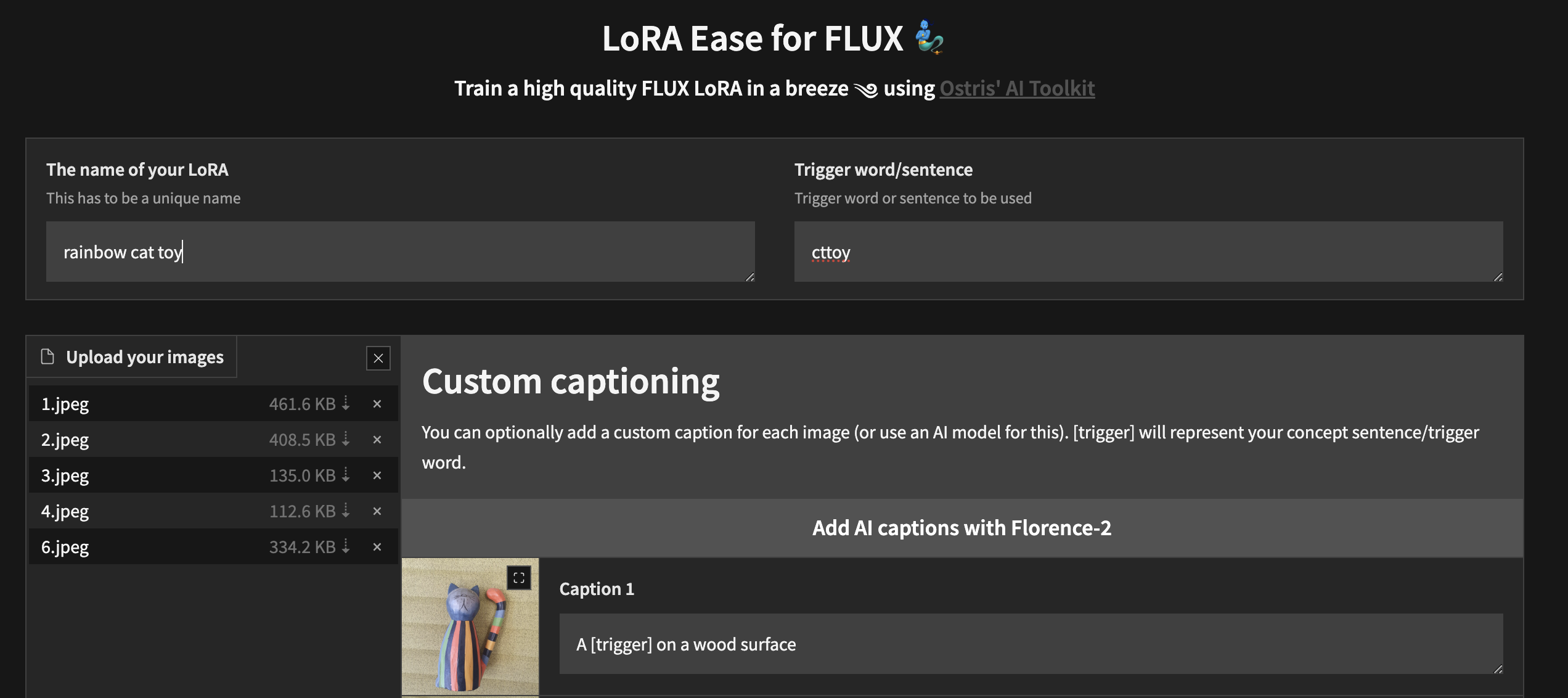
Exemplo de modelo RunPod: runpod/pytorch:2.2.0-py3.10-cuda12.1.1-devel-ubuntu22.04
Você precisa de no mínimo 24 GB de VRAM, escolha uma GPU de sua preferência.
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
dataset ou como quiser.huggingface-cli login e cole seu token.config/examples para a pasta de configuração e renomeie-o whatever_you_want.yml .folder_path: "/path/to/images/folder" para o caminho do conjunto de dados, como folder_path: "/workspace/ai-toolkit/your-dataset" .python run.py config/whatever_you_want.yml .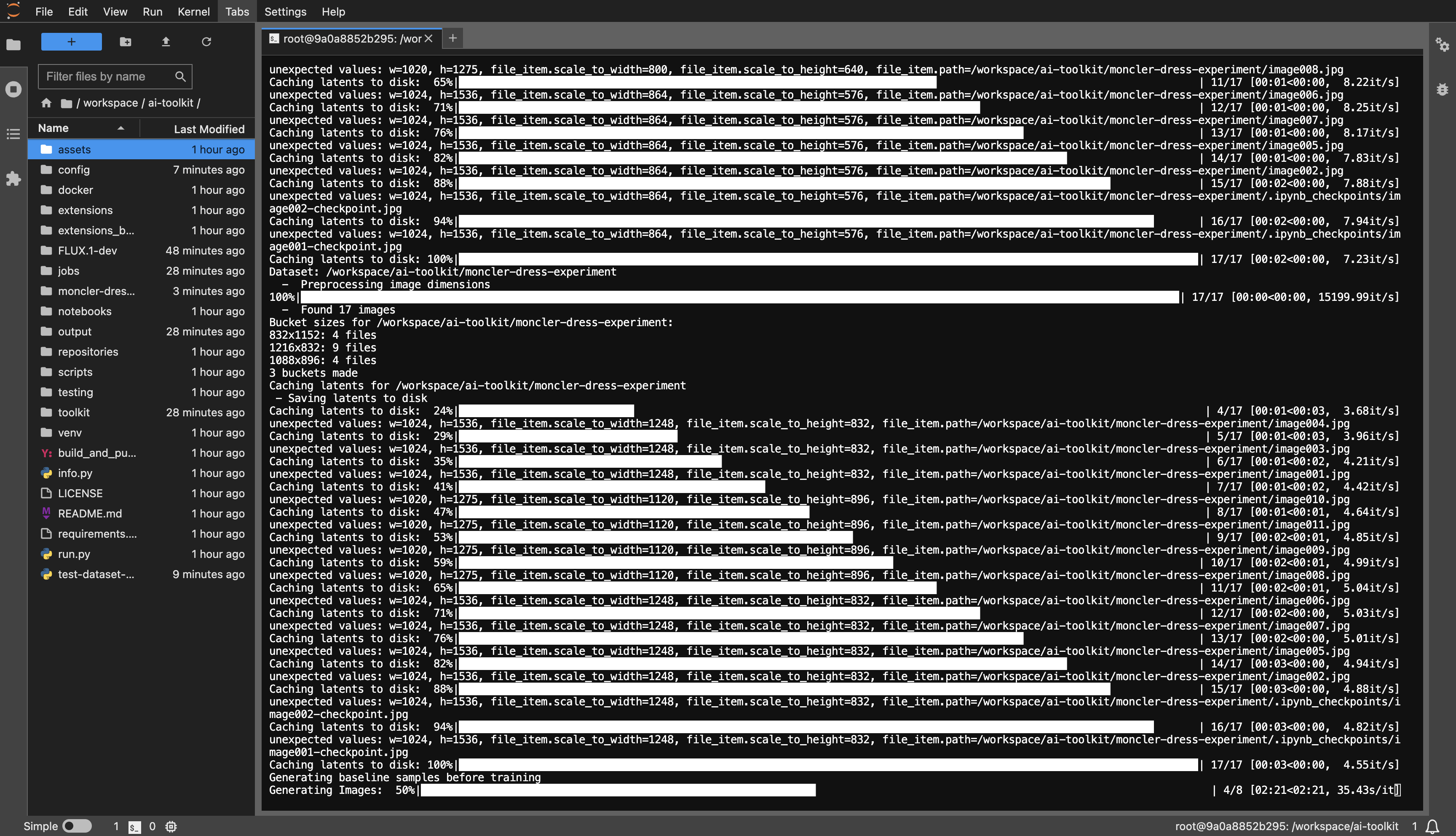
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
pip install modal para instalar o pacote Python modal.modal setup para autenticar (se isso não funcionar, tente python -m modal setup ). huggingface-cli login e cole seu token.ai-toolkit .config/examples/modal para a pasta config e renomeie-o whatever_you_want.yml ./root/ai-toolkit paths . Defina todo o caminho local ai-toolkit em code_mount = modal.Mount.from_local_dir como:
code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit")
Escolha uma GPU e Timeout em @app.function (o padrão é A100 40GB e tempo limite de 2 horas) .
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.yml .Storage > flux-lora-models .modal volume ls flux-lora-models .modal volume get flux-lora-models your-model-name .modal volume get flux-lora-models my_first_flux_lora_v1 .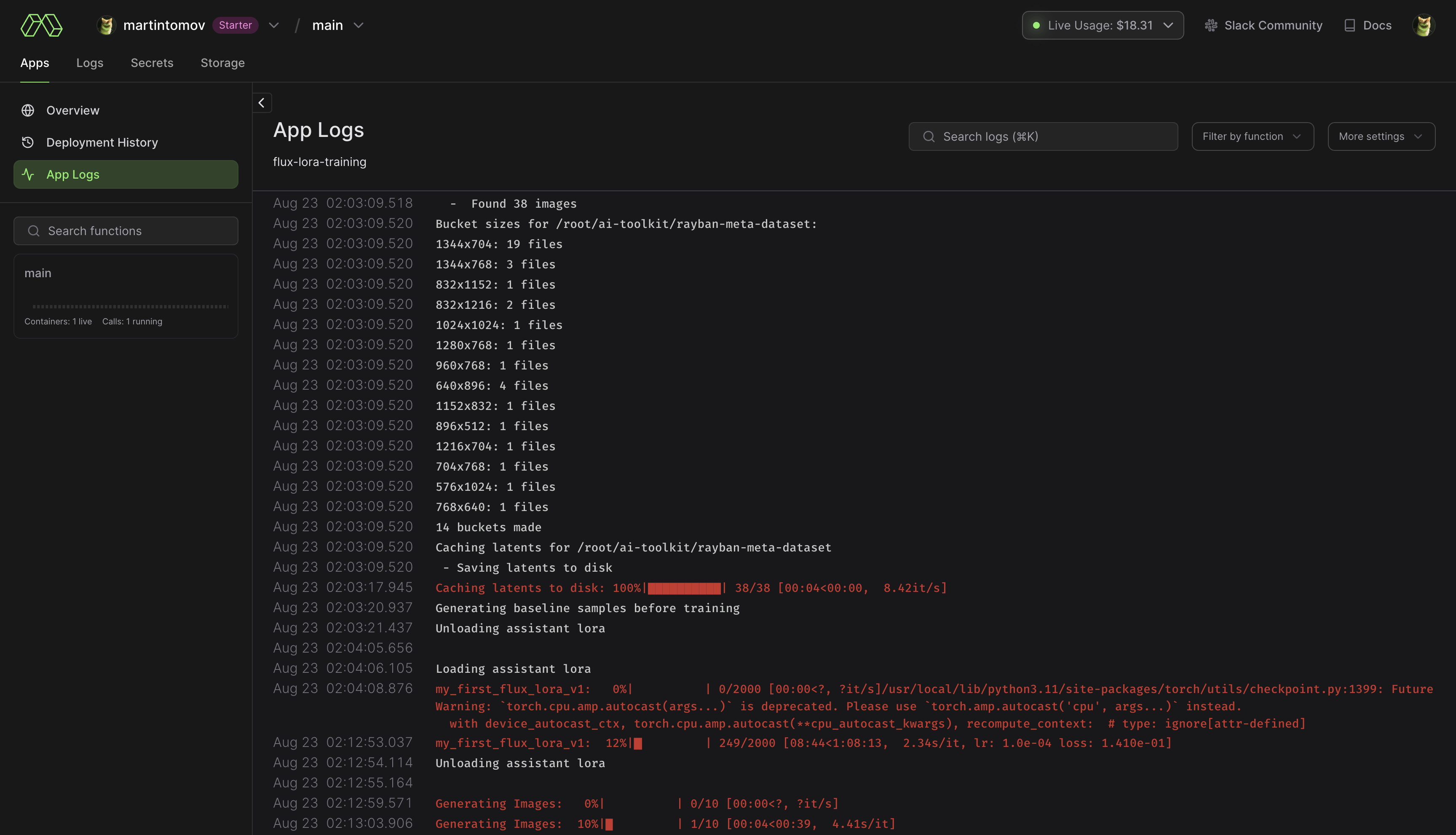
Os conjuntos de dados geralmente precisam ser uma pasta contendo imagens e arquivos de texto associados. Atualmente, os únicos formatos suportados são jpg, jpeg e png. Webp atualmente tem problemas. Os arquivos de texto devem ter o mesmo nome das imagens, mas com extensão .txt . Por exemplo image2.jpg e image2.txt . O arquivo de texto deve conter apenas a legenda. Você pode adicionar a palavra [trigger] no arquivo de legenda e se tiver trigger_word em sua configuração, ela será substituída automaticamente.
As imagens nunca são aumentadas, mas são reduzidas e colocadas em grupos para processamento em lote. Você não precisa cortar/redimensionar suas imagens . O carregador irá redimensioná-los automaticamente e pode lidar com proporções variadas.
Para treinar camadas específicas com LoRA, você pode usar os kwargs de rede only_if_contains . Por exemplo, se você quiser treinar apenas as 2 camadas usadas por The Last Ben, mencionadas neste post, você pode ajustar seus kwargs de rede assim:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks.7.proj_out "
- " transformer.single_transformer_blocks.20.proj_out " As convenções de nomenclatura das camadas estão no formato difusores, portanto, verificar o ditado de estado de um modelo revelará o sufixo do nome das camadas que você deseja treinar. Você também pode usar esse método para treinar apenas grupos específicos de pesos. Por exemplo, para treinar apenas o single_transformer para FLUX.1, você pode usar o seguinte:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks. " Você também pode excluir camadas por seus nomes usando ignore_if_contains network kwarg. Então, para excluir todos os blocos transformadores individuais,
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
ignore_if_contains :
- " transformer.single_transformer_blocks. " ignore_if_contains tem prioridade sobre only_if_contains . Portanto, se um peso for coberto por ambos, será ignorado.
Ainda pode funcionar assim, mas não o testo há algum tempo.
Um gerador de imagens que pode pegar frompts de um arquivo de configuração ou formar um arquivo txt e gerá-los para uma pasta. Eu precisava disso principalmente para um teste SDXL que estou fazendo, mas adicionei um pouco de polimento para que possa ser usado para gerar geração de imagens em lote. Tudo funciona em um arquivo de configuração, do qual você pode encontrar um exemplo em config/examples/generate.example.yaml . Meras informações estão nos comentários do exemplo
É baseado no extrator da ferramenta LyCORIS, mas adicionando alguns recursos de QV e suporte LoRA (lierla). Ele pode fazer vários tipos de extrações em uma única execução. Tudo é executado em um arquivo de configuração, do qual você pode encontrar um exemplo em config/examples/extract.example.yml . Basta copiar esse arquivo para a pasta config e renomeá-lo whatever_you_want.yml . Então você pode editar o arquivo ao seu gosto. e chame assim:
python3 run.py config/whatever_you_want.ymlVocê também pode colocar um caminho completo para um arquivo de configuração, se quiser mantê-lo em outro lugar.
python3 run.py " /home/user/whatever_you_want.yml "Mais notas sobre como funciona estão disponíveis no próprio arquivo de configuração de exemplo. LoRA e LoCON suportam extrações de 'fixo', 'limiar', 'proporção', 'quantil'. Atualizarei o que isso significa e significa mais tarde. A maioria das pessoas usava fixo, que é a extração tradicional de dimensão fixa.
process é uma série de processos diferentes a serem executados. Você pode adicionar alguns e misturar e combinar. Um LoRA, um LyCON, etc.
Mude <lora:my_lora:4.6> para <lora:my_lora:1.0> ou o que quiser com o mesmo efeito. Uma ferramenta para redimensionar os pesos de um LoRA. Deveria fazer com LoCON também, mas não testei. Tudo funciona em um arquivo de configuração, do qual você pode encontrar um exemplo em config/examples/mod_lora_scale.yml . Basta copiar esse arquivo para a pasta config e renomeá-lo whatever_you_want.yml . Então você pode editar o arquivo ao seu gosto. e chame assim:
python3 run.py config/whatever_you_want.ymlVocê também pode colocar um caminho completo para um arquivo de configuração, se quiser mantê-lo em outro lugar.
python3 run.py " /home/user/whatever_you_want.yml "Mais notas sobre como funciona estão disponíveis no próprio arquivo de configuração de exemplo. Isso é útil ao fazer todos os LoRAs, já que o peso ideal raramente é 1,0, mas agora você pode consertar isso. Para controles deslizantes, eles podem ter escalas estranhas de -2 a 2 ou mesmo -15 a 15. Isso permitirá que você ajuste para que todos tenham a escala desejada
É assim que treino a maioria dos sliders recentes que tenho no Civitai, você pode conferir no meu perfil do Civitai. É baseado no trabalho de p1atdev/LECO e rohitgandikota/erasing, mas foi fortemente modificado para criar controles deslizantes em vez de apagar conceitos. Tenho muito mais planos sobre isso, mas é muito funcional como está. Também é muito fácil de usar. Basta copiar o arquivo de configuração de exemplo em config/examples/train_slider.example.yml para a pasta config e renomeá-lo whatever_you_want.yml . Então você pode editar o arquivo ao seu gosto. e chame assim:
python3 run.py config/whatever_you_want.ymlHá muito mais informações nesse arquivo de exemplo. Você pode até executar o exemplo como está, sem nenhuma modificação, para ver como funciona. Ele criará um controle deslizante que transforma todos os animais em cães (neg) ou gatos (pos). Basta executá-lo assim:
python3 run.py config/examples/train_slider.example.ymlE você poderá ver como funciona sem configurar nada. Nenhum conjunto de dados é necessário para este método. Em breve postarei um tutorial melhor.
Agora você pode criar e compartilhar extensões personalizadas. Que funcionam dentro desta estrutura e têm todas as ferramentas integradas disponíveis. Provavelmente usarei isso como o principal método de desenvolvimento daqui para frente, para não continuar adicionando e adicionando mais e mais recursos a este repositório base. Provavelmente também migrarei muitas das funcionalidades existentes para tornar tudo modular. Há um exemplo de extensão na pasta extensions que mostra como fazer uma extensão de fusão de modelos. Todo o código está fortemente documentado, o que esperamos ser suficiente para você começar. Para fazer uma extensão, basta copiar esse exemplo e substituir tudo o que for necessário.
Ele está localizado na pasta de extensions . É uma fusão de modelos totalmente funcional que pode mesclar quantos modelos você desejar. É um bom exemplo de como fazer uma extensão, mas também é um recurso bastante útil, já que a maioria das fusões só pode fazer um modelo por vez e este levará quantos você quiser para alimentá-lo. Há um exemplo de arquivo de configuração lá, basta copiá-lo para sua pasta config e renomeá-lo whatever_you_want.yml . e use-o como qualquer outro arquivo de configuração.
Isso funciona, mas não está pronto para ser usado por outros e, portanto, não possui um exemplo de configuração. Ainda estou trabalhando nisso. Vou atualizar isso quando estiver pronto. Estou adicionando muitos recursos aos critérios que usei em meu trabalho de ampliação de imagens. Um crítico (discriminador), perda de conteúdo, perda de estilo e mais alguns. Se você não sabe, o VAE para difusão estável (sim, até mesmo o MSE e SDXL), é horrível em faces menores e retém o SD. Eu vou consertar isso. Postarei mais sobre isso mais tarde com exemplos melhores, mas aqui está um teste rápido de uma execução com vários VAEs. Apenas entrei e saí. É muito pior em rostos menores do que os mostrados aqui.
extensions . Leia mais sobre isso acima.Outra grande refatoração para tornar o SD mais modular.
Feito script de geração de imagens em lote
Principais mudanças e atualização. Nova ferramenta de redimensionamento LoRA, veja detalhes acima. Adicionados metadados melhores para que o Automatic1111 saiba qual é o modelo base. Adicionados alguns experimentos e muitas atualizações. Essa coisa ainda está instável no momento, então espero que não haja alterações significativas.
Infelizmente, estou com preguiça de escrever um changelog adequado com todas as alterações.
Adicionei treinamento SDXL aos controles deslizantes... mas... não funciona corretamente. O treinamento do controle deslizante depende da capacidade de um modelo de entender que um incondicional (prompt negativo) significa que você não deseja esse conceito na saída. SDXL não entende isso por qualquer motivo, o que torna difícil separar conceitos dentro do modelo. Tenho certeza de que a comunidade encontrará uma maneira de consertar isso com o tempo, mas, por enquanto, não funcionará corretamente. E se algum de vocês estiver pensando: "Poderíamos consertar isso adicionando mais 1 ou 2 codificadores de texto ao modelo, bem como mais algumas redes de difusão totalmente separadas?" Não. Deus, não. Ele só precisa de um pouco de treinamento, sem que nenhum novo artigo experimental seja adicionado a ele. O diretor do KISS.
Adicionadas "âncoras" ao treinador de controle deslizante. Isso permite que você defina um prompt que será usado como regularizador. Você pode definir o multiplicador de rede para forçar a consistência da propagação em pesos altos


