spelltest
v0.0.4
? Se você achar este projeto útil, considere dar-lhe uma estrela! Seu apoio me motiva a continuar melhorando! ?
As aplicações atuais baseadas em IA dependem em grande parte de Large Language Models (LLMs), como o GPT-4, para fornecer soluções inovadoras. No entanto, garantir que fornecem respostas relevantes e precisas em todas as situações é um desafio. O Spelltest aborda isso simulando respostas LLM usando personas de usuário sintéticas e uma técnica de avaliação para avaliar essas respostas automaticamente (mas ainda requer supervisão humana).
spellforge.yaml : project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

Agora você pode experimentar este projeto em um ambiente interativo baseado na web por meio do Google Colab! Nenhuma instalação é necessária.
Basta clicar no selo acima para começar!
Qualidade garantida : simule as interações do usuário para obter respostas ideais.
Eficiência e economia : Economize em custos de testes manuais.
Integração suave do fluxo de trabalho : adapta-se perfeitamente ao seu processo de desenvolvimento.
Esteja ciente de que esta é uma versão muito antiga do Spelltest. Como tal, ainda não foi extensivamente testado em diversos ambientes e casos de uso. Ao decidir usar esta versão, você aceita que está usando a estrutura Spelltest por sua conta e risco. Encorajamos fortemente os usuários a relatar quaisquer problemas ou bugs que encontrarem para ajudar na melhoria do projeto.
Em relação aos custos operacionais, é importante ressaltar que a execução de simulações com Spelltest incorre em cobranças baseadas no uso da API OpenAI. Não há estimativas de custos ou limite orçamentário no momento. Para contextualizar, executar um lote de 100 simulações pode custar aproximadamente US$ 0,7 a US$ 1,8 (gpt-3,5-turbo), dependendo de vários fatores, incluindo o LLM específico e a complexidade das simulações.
Dados esses custos, é altamente recomendável começar com um número menor de simulações para manter seus custos iniciais baixos e ajudá-lo a estimar melhor as despesas futuras. À medida que você se familiarizar com a estrutura e suas implicações de custo, poderá ajustar o número de simulações de acordo com seu orçamento e necessidades.
Lembre-se de que o objetivo do Spelltest é garantir respostas de alta qualidade dos LLMs, ao mesmo tempo que permanece o mais econômico possível em seu processo de desenvolvimento e teste de IA.

Spelltest adota uma abordagem diferenciada para garantia de qualidade. Ao usar personas de usuário sintéticas, não apenas simulamos interações, mas também capturamos expectativas exclusivas do usuário, fornecendo um ambiente de teste rico em contexto. Essa profundidade de contexto nos permite avaliar a qualidade das respostas do LLM de uma maneira que reflete de perto as aplicações do mundo real.
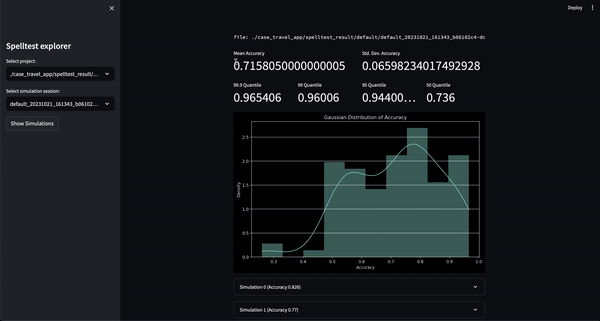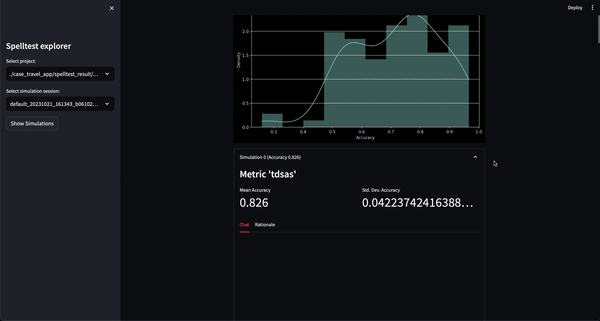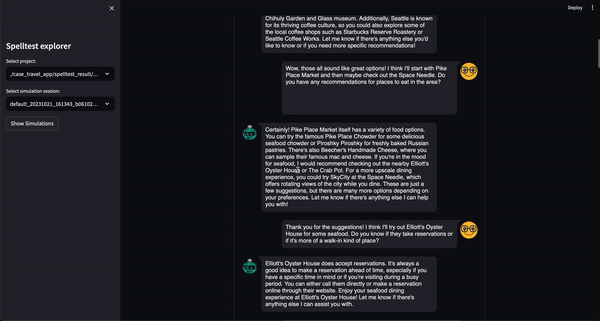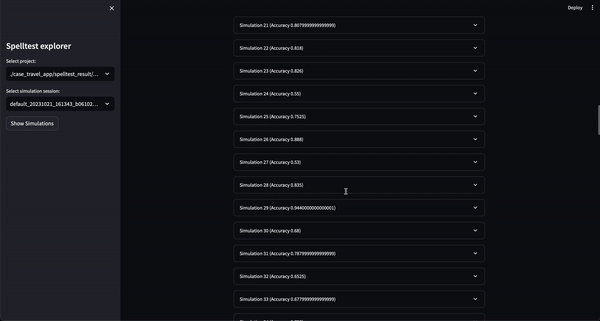
O resultado? Uma pontuação de qualidade que varia de 0,0 a 1,0, atuando como um ensaio geral abrangente antes que seu aplicativo atinja seus usuários reais. Seja no modo de bate-papo ou de conclusão, o Spelltest garante que as respostas do LLM estejam alinhadas com as expectativas do usuário, aumentando a satisfação geral do usuário.
Instale a estrutura usando pip:
pip install spelltest O .spellforge.yaml é central para o Spelltest, contendo perfis de usuário sintéticos, métricas, prompts e simulações. Abaixo está um detalhamento de sua estrutura:
Os usuários sintéticos imitam usuários do mundo real, cada um com experiência, expectativa e compreensão únicas do aplicativo. A configuração para usuários sintéticos inclui:
Subprompts : são elementos descritivos que fornecem contexto ao perfil do usuário. Eles incluem:
description : Um resumo sobre o usuário sintético.expectation : o que o usuário espera da interação.user_knowledge_about_app : Nível de familiaridade com o aplicativo.Cada usuário sintético também possui:
name : o identificador do usuário sintético.llm_name : os modelos LLM a serem usados (testados apenas em modelos OpenAI).temperature : ...Exemplo de configuração de usuário sintética:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
... As métricas são usadas para avaliar e pontuar as respostas do LLM. Cada métrica contém uma description de subprompt que fornece contexto sobre o que a métrica avalia.
Exemplo de configuração de métrica simples:
...
metrics :
accuracy :
description : " Accuracy "
...Exemplo de configuração de métrica complexa/personalizada:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
... Prompts são perguntas ou tarefas que o aplicativo apresenta. Eles são usados em simulações para testar a capacidade do LLM de gerar respostas adequadas. Cada prompt é definido com uma description e o texto ou tarefa real prompt .
...
prompts :
book_flight :
file : book-flight-prompt.txt
... As simulações especificam o cenário de teste. Os principais elementos incluem prompt , users , llm_name , temperature , size , chat_mode e quality_threshold .
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
A configuração completa com arquivos de prompt está aqui.
Custos do OpenAI : O uso desta estrutura pode levar a um número significativo de solicitações ao OpenAI, especialmente ao executar simulações extensas. Isso pode resultar em custos substanciais na sua conta OpenAI. Certifique-se de estar atento ao seu orçamento OpenAI e compreender o modelo de preços. Não me responsabilizo por quaisquer despesas incorridas.
Lançamento Antecipado : Esta versão do Spelltest está em seus estágios iniciais e não tem garantias de estabilidade. Use-o com cautela e sinta-se à vontade para fornecer comentários ou relatar problemas.
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yamlConfira os resultados da simulação.
spelltest --analyzeA integração do Spelltest ao seu pipeline de lançamento aprimora sua estratégia de implantação, incorporando testes consistentes e automatizados. Esta etapa crucial garante que seus aplicativos baseados em LLM mantenham um alto padrão de qualidade, simulando e avaliando sistematicamente as interações do usuário antes de qualquer lançamento. Essa prática pode economizar um tempo significativo, reduzir erros manuais e fornecer insights importantes sobre como as alterações ou novos recursos afetarão a experiência do usuário.
Este guia orientará você no processo de configuração e automatização da integração contínua para seus projetos.
Antes de começar, certifique-se de ter os seguintes pré-requisitos em vigor:
Um repositório GitHub contendo seu projeto.
Acesso ao SpellForge com uma chave API. Se você não tiver um, poderá obtê-lo no site do SpellForge.
Uma chave de API OpenAI para usar serviços OpenAI. Se você não tiver um, poderá obtê-lo no site da OpenAI.
.spellforge.yaml Crie um arquivo .spellforge.yaml no diretório raiz do seu projeto. Este arquivo conterá as instruções para o Spelltest.
Crie um arquivo de fluxo de trabalho do GitHub Actions, por exemplo, .github/workflows/.spelltest.yaml, para automatizar os testes do SpellForge. Insira o seguinte código neste arquivo:
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATHEste fluxo de trabalho é acionado a cada push para o branch principal e executará seus testes SpellForge.
Vá para o seu repositório GitHub e navegue até a guia “Configurações”.
Em "Segredos" adicione dois novos segredos:
OPENAI_API_KEY : Defina este segredo para sua chave de API OpenAI.
Adicione uma variável de ambiente GitHub:
SPELLTEST_CONFIG_PATH : Defina esta variável como o caminho completo para seu arquivo .spellforge.yaml em seu repositório.
Eles simulam interações de usuários reais com características e expectativas específicas.
Histórico do usuário (campo description em .spellforge.yaml ): Um subprompt que fornece uma visão geral de quem é esse usuário sintético e os problemas que ele deseja resolver usando o aplicativo, por exemplo, um viajante gerenciando sua agenda.
Expectativa do usuário (campo expectation ): um subprompt que define o que o usuário sintético antecipa como uma interação ou solução bem-sucedida ao usar o aplicativo.
Conscientização ambiental (campo user_knowledge_about_app ): um sub-prompt que garante que o usuário sintético entenda o contexto do aplicativo, garantindo cenários de teste realistas.
Um subprompt que representa padrões ou critérios usados para avaliar e pontuar as respostas geradas pelo LLM nas simulações. As métricas podem variar de medidas gerais até métricas personalizadas mais específicas do aplicativo.
Exemplos de métricas gerais:
Similaridade semântica : mede o quão próxima a resposta fornecida se assemelha a uma resposta esperada em termos de significado.
Toxicidade : Avalia a resposta para qualquer linguagem ou conteúdo que possa ser considerado impróprio ou prejudicial.
Similaridade estrutural : compara a estrutura e o formato da resposta gerada com um padrão predefinido ou saída esperada.
Mais exemplos de métricas personalizadas:
TPAS (Pontuação de Precisão do Plano de Viagem) : "Esta métrica mede a precisão da resposta gerada avaliando a inclusão do resultado esperado e a qualidade do plano de viagem proposto. TPAS é um valor numérico entre 0 e 100, com 100 representando um perfeito corresponde à saída esperada e 0 indica um resultado não preciso."
EES (Pontuação de Engajamento de Empatia) : "O EES avalia a ressonância empática das respostas do LLM. Ao avaliar a compreensão, a validação e os elementos de apoio na mensagem, ele avalia o nível de empatia transmitido. O EES varia de 0 a 100, onde 100 indica um resposta altamente empática, enquanto 0 denota falta de envolvimento empático."
Torne seu aplicativo baseado em LLM melhor com Spelltest!


