datablations
1.0.0
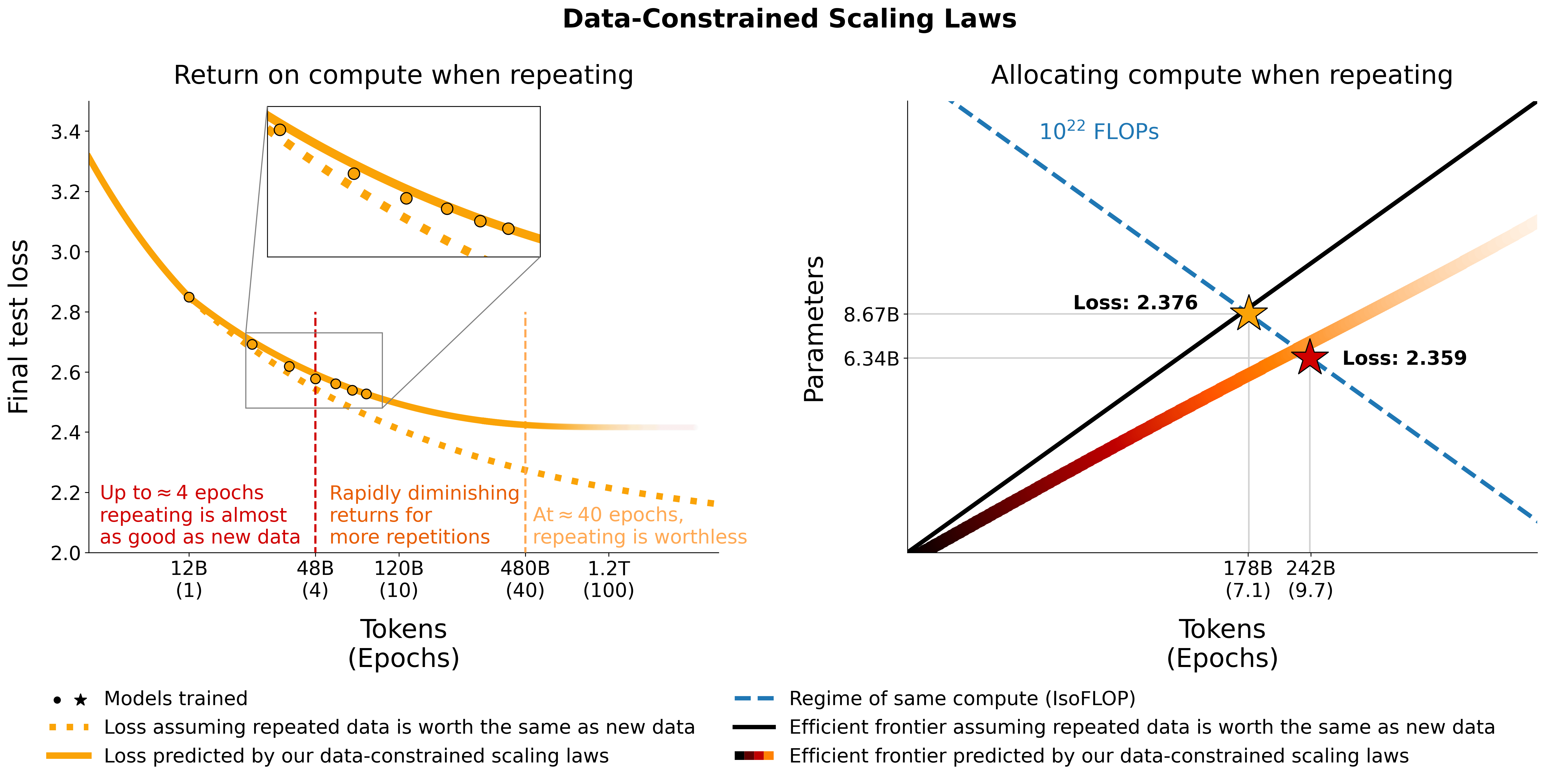
Este repositório fornece uma visão geral de todos os componentes do artigo Scaling Data-Constrained Language Models. Palestras no papel:
Investigamos modelos de linguagem em escala em regimes com restrição de dados. Executamos um grande conjunto de experimentos variando a extensão da repetição de dados e o orçamento computacional, variando até 900 bilhões de tokens de treinamento e 9 bilhões de modelos de parâmetros. Com base em nossas execuções, propomos e validamos empiricamente uma lei de escala para otimização de computação que leva em conta o valor decrescente de tokens repetidos e parâmetros em excesso. Também experimentamos abordagens para mitigar a escassez de dados, incluindo o aumento do conjunto de dados de treinamento com dados de código, filtragem de perplexidade e desduplicação. Modelos e conjuntos de dados de nossas 400 execuções de treinamento estão disponíveis neste repositório.
Experimentamos repetir dados em C4 e a divisão em inglês não desduplicada do OSCAR. Para cada conjunto de dados, baixamos os dados e os transformamos em um único arquivo jsonl, c4.jsonl e oscar_en.jsonl respectivamente.
Em seguida, decidimos a quantidade de tokens exclusivos e o respectivo número de amostras que precisamos do conjunto de dados. Observe que C4 possui 478.625834583 tokens por amostra e OSCAR possui 1312.0951072 com o GPT2Tokenizer. Isso foi calculado tokenizando todo o conjunto de dados e dividindo o número de tokens pelo número de amostras. Usamos esses números para calcular as amostras necessárias.
Por exemplo, para tokens exclusivos de 1,9B, precisamos de 1.9B / 478.625834583 = 3969697.96178 amostras para C4 e 1.9B / 1312.0951072 = 1448065.76107 amostras para OSCAR. Para tokenizar os dados, primeiro precisamos clonar o repositório Megatron-DeepSpeed e seguir seu guia de configuração. Em seguida, selecionamos essas amostras e as tokenizamos da seguinte forma:
C4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64OSCAR:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64 onde gpt2 aponta para uma pasta contendo todos os arquivos de https://huggingface.co/gpt2/tree/main. Ao usar head garantimos que diferentes subconjuntos terão amostras sobrepostas para reduzir a aleatoriedade.
Para avaliação durante o treinamento e avaliação final, utilizamos o conjunto de validação para C4:
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2 Para OSCAR que não tem conjunto de validação oficial, participamos do conjunto de treinamento fazendo tail -364608 oscar_en.jsonl > oscarvalidation.jsonl e então tokenizamos da seguinte forma:
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2Carregamos vários subconjuntos pré-processados para uso com megatron:
Alguns arquivos bin eram muito grandes para o git e, portanto, divididos usando, por exemplo, split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. e split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. . Para usá-los para treinamento, você precisa cat-los juntos novamente usando cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin e cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin .
Experimentamos misturar código com dados de linguagem natural usando a divisão Python do stack-dedup. Baixamos os dados, transformamos-os em um único arquivo jsonl e os pré-processamos usando a mesma abordagem descrita acima.
Carregamos a versão pré-processada para uso com megatron aqui: https://huggingface.co/datasets/datablations/python-megatron. Dividimos o arquivo bin usando split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. , então você precisa reuni-los novamente usando cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin para treinamento.
Criamos versões de C4 e OSCAR com metadados de filtragem relacionados à perplexidade e desduplicação:
Para recriar esses conjuntos de dados de metadados, há instruções em filtering/README.md .
Fornecemos as versões tokenizadas que podem ser usadas para treinamento com Megatron em:
Os arquivos .bin foram divididos usando algo como split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. , então você precisa concatená-los novamente via cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin .
Para recriar as versões tokenizadas de acordo com o conjunto de dados de metadados,
filtering/deduplication/filter_oscar_jsonl.pyPara criar os percentis de perplexidade, siga as instruções abaixo.
C4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )OSCAR:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )Você pode então tokenizar os arquivos jsonl resultantes para treinamento com Megatron conforme descrito na seção Repetição.
C4: Para C4 você só precisa remover todas as amostras onde o campo repetitions está preenchido, por exemplo
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR: Para OSCAR, fornecemos um script em filtering/filter_oscar_jsonl.py para criar o conjunto de dados desduplicado, dado o conjunto de dados com filtragem de metadados.
Você pode então tokenizar os arquivos jsonl resultantes para treinamento com Megatron conforme descrito na seção Repetição.
Todos os modelos podem ser baixados em https://huggingface.co/datablations.
Os modelos são geralmente nomeados da seguinte forma: lm1-{parameters}-{tokens}-{unique_tokens} , especificamente modelos individuais nas pastas são nomeados como: {parameters}{tokens}{unique_tokens}{optional specifier} , por exemplo 1b12b8100m seria 1,1 bilhão de parâmetros, 2,8 bilhões de tokens, 100 milhões de tokens exclusivos. A convenção xby ( 1b1 , 2b8 etc.) introduz alguma ambigüidade se os números pertencem a parâmetros ou tokens, mas você sempre pode verificar o script sbatch na respectiva pasta para ver os parâmetros/tokens/tokens exclusivos exatos. Se você deseja converter modelos que ainda não foram convertidos para huggingface/transformers , você pode seguir as instruções em Treinamento.
A maneira mais fácil de baixar um único modelo é, por exemplo:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553 Se demorar muito, você também pode usar wget para baixar diretamente arquivos individuais da pasta, por exemplo:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.ptPara modelos correspondentes aos experimentos do artigo, consulte os seguintes repositórios:
lm1-misc/*dedup* para comparação de desduplicação em 100 milhões de tokens exclusivos no apêndiceOutros modelos não analisados no artigo:
Treinamos modelos com nosso fork do Megatron-DeepSpeed que funciona com GPUs AMD (via ROCm): https://github.com/TurkuNLP/Megatron-DeepSpeed Se você quiser usar GPUs NVIDIA (via cuda), você pode usar o biblioteca original: https://github.com/bigscience-workshop/Megatron-DeepSpeed
Você precisa seguir as instruções de configuração de qualquer repositório para criar seu ambiente (nossa configuração específica para LUMI é detalhada em training/megdssetup.md ).
Cada pasta de modelo contém um script em lote que foi usado para treinar o modelo. Você pode usá-los como referência para treinar seus próprios modelos adaptando as variáveis de ambiente necessárias. Os scripts sbatch fazem referência a alguns arquivos adicionais:
*txt arquivos que especificam os caminhos de dados. Você pode encontrá-los em utils/datapaths/* , no entanto, provavelmente precisará adaptar o caminho para apontar para seu conjunto de dados.model_params.sh , que está em utils/model_params.sh e contém predefinições de arquitetura.launch.sh que você pode encontrar em training/launch.sh . Ele contém comandos específicos para nossa configuração, que você pode querer remover. Após o treinamento, você pode converter seu modelo em transformadores com, por exemplo, python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1 .
Para modelos repetidos, também carregamos seus tensorboards após o treinamento usando, por exemplo, tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar" , o que os torna fáceis de usar para visualização no artigo.
Para a ablação muP no Apêndice usamos o script em training_scripts/mup.py . Ele contém instruções de configuração.
Você pode usar nossa fórmula para calcular a perda esperada, dados parâmetros, dados e tokens exclusivos da seguinte forma:
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867Observe que é improvável que o valor real da perda seja útil, mas sim a tendência da perda à medida que, por exemplo, o número de parâmetros aumenta ou para comparar dois modelos como no exemplo acima. Para calcular a alocação ideal, você pode usar uma pesquisa simples em grade:
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test Se você derivar uma expressão de formato fechado para a alocação ideal em vez da pesquisa de grade acima, informe-nos :) Ajustamos as leis de escala com restrição de dados e os coeficientes de escala C4 usando o código em utils/parametric_fit.ipynb equivalente a esta colab .
Training > Regular models para configurar um ambiente de treinamento.pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git . Usamos a versão 0.2.0, mas versões mais recentes também devem funcionar.sbatch utils/eval_rank.sh modificando primeiro as variáveis necessárias no scriptpython Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.jsonaddtasks do equipamento de avaliação: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13 ou seja, todos os requisitos, exceto promptsource, que é instalado a partir de um fork com os prompts corretossbatch utils/eval_generative.sh modificando primeiro as variáveis necessárias no scriptpython utils/merge_generative.py e depois os convertemos para csv com python utils/csv_generative.py merged.jsonbabi do chicote de avaliação: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (Observe que este branch não é compatível com o branch addtasks para tarefas generativas, pois se origina de EleutherAI/lm-evaluation-harness , enquanto addtasks é baseado em bigscience/lm-evaluation-harness )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh modificando primeiro as variáveis necessárias no script plotstables/return_alloc.pdf , plotstables/return_alloc.ipynb , colabplotstables/dataset_setup.pdf , plotstables/dataset_setup.ipynb , colabplotstables/contours.pdf , plotstables/contours.ipynb , colabplotstables/isoflops_training.pdf , plotstables/isoflops_training.ipynb , colabplotstables/return.pdf , plotstables/return.ipynb , colabplotstables/strategies.pdf , plotstables/strategies.drawioplotstables/beyond.pdf , plotstables/beyond.ipynb , colabplotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf e mesmo colab da Figura 3plotstables/mup.pdf , plotstables/dd.pdf , plotstables/dedup.pdf , plotstables/mup_dd_dd.ipynb , colabplotstables/isoloss_alphabeta_100m.pdf e mesmo colab da Figura 3plotstables/galactica.pdf , plotstables/galactica.ipynb , colabtraining_c4.pdf , validation_c4oscar.pdf , training_oscar.pdf , validation_epochs_c4oscar.pdf e mesmo colab da Figura 4plotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf , plotstables/training_validation_filter.pdf , plotstables/beyond_losses.ipynb & colabutils/parametric_fit.ipynb equivalentes a este colab.plotstables/repetition.ipynb & colabplotstables/python.ipynb & colabplotstables/filtering.ipynb & colabTodos os modelos e códigos são licenciados sob Apache 2.0. Os conjuntos de dados filtrados são lançados com a mesma licença dos conjuntos de dados dos quais provêm.
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

