paperchat
1.0.0
Bem-vindo ao arXivchat!
arXivchat é um software baseado em LLM que permite falar sobre artigos publicados no arXiv de maneira conversacional. Funciona como uma ferramenta cli, provedor de API e plugin ChatGPT.
Feito por Operadores Avançados. Trabalhamos com algumas das pessoas mais inteligentes em projetos relacionados a LLM e ML.
Você é mais que bem-vindo para contribuir!
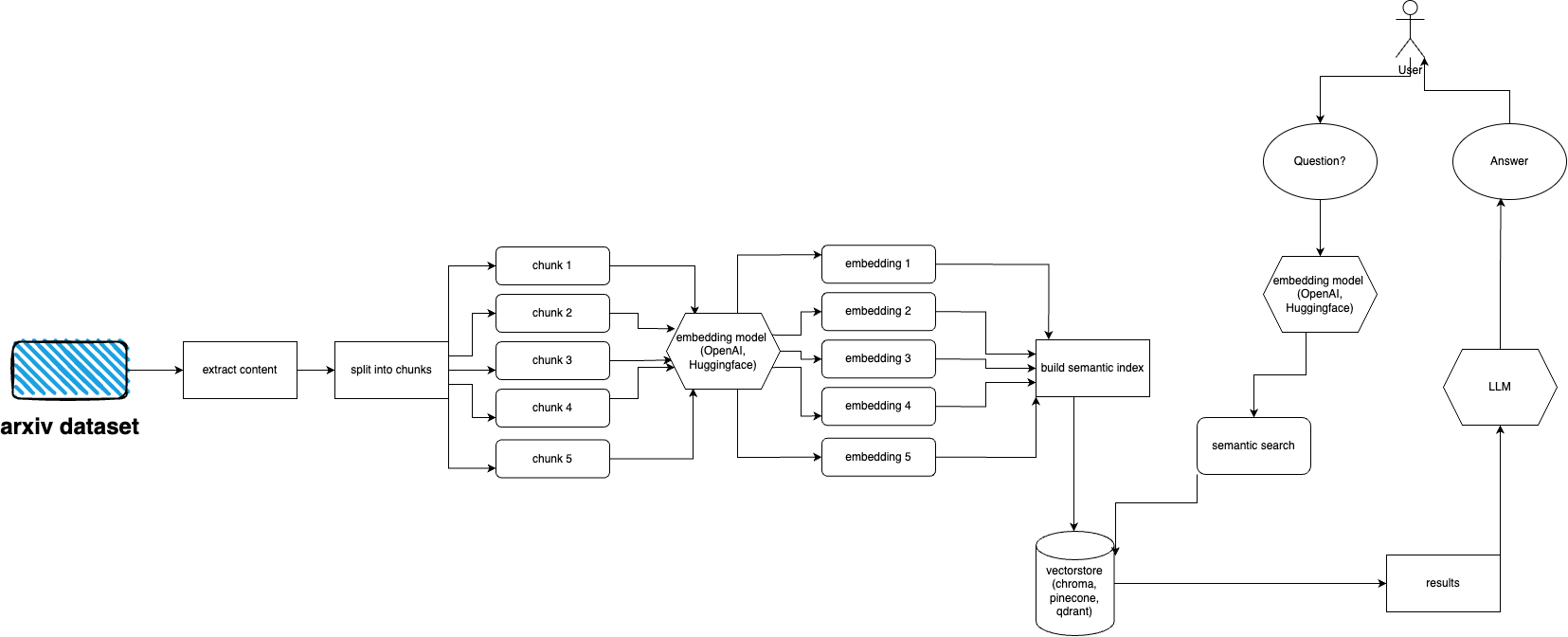
Siga estas etapas para configurar e executar rapidamente o plugin arXiv:
Instale o Python 3.10, se ainda não estiver instalado.
Clone o repositório: git clone https://github.com/Forward-Operators/arxivchat.git
Navegue até o diretório do repositório clonado: cd /path/to/arxivchat
Instale poesia: pip install poetry
Crie um novo ambiente virtual com Python 3.10: poetry env use python3.10
Ative o ambiente virtual: poetry shell
Instale dependências de aplicativos: poetry install
Defina as variáveis de ambiente necessárias:
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
Execute a API localmente: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
Acesse a documentação da API em http://0.0.0.0:8000/docs e teste os endpoints da API.
arXiv possui um conjunto de dados de quase 2 milhões de publicações. é contra os ToS do arXiv buscar muitos dados de seu site (pois isso cria carga). Felizmente, boas pessoas do kaggle, juntamente com a Cornell University, criam um conjunto de dados disponível publicamente que você pode usar. O conjunto de dados está disponível gratuitamente por meio dos buckets do Google Cloud Storage e é atualizado semanalmente.
Agora, a principal questão é: como obter apenas um subconjunto de todo esse conjunto de dados se não quisermos ingerir mais de 5 terabytes de arquivos PDF? O conjunto de dados é dividido em diretórios por mês e por ano, portanto, se desejar obter todas as publicações de setembro de 2021, basta executar: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
Se desejar obter um conjunto de dados inteiro: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
Mas se você deseja obter apenas um subconjunto (para uma determinada categoria e datas), dê uma olhada no arquivo download.py .
Por padrão, o ingester espera que esses arquivos estejam em /mnt/dataset/arxiv/pdf com todos os arquivos PDF lá.
Confira e execute python scripy.py para ingerir dados. Você também pode ativar a depuração se algo não funcionar.
TODO: talvez mude para o carregador de diretório TODO: implemente a implantação do aipo e use o trabalhador para ingestão
python cli.py 
Faça a pergunta sobre o tópico que você alimentou no banco de dados antes. Também retorna informações sobre fontes e é executado continuamente. Outra opção é usar a API REST (execute uvicorn main:app --reload --host 0.0.0.0 --port 8000 do diretório app ) ou usá-lo como plugin ChatGPT (após a implantação)
Existem arquivos terraform no diretório deployment . Use aquele que melhor se adapta a você. Há um arquivo README em cada um deles com instruções. Você também pode simplesmente construir uma imagem Docker e executá-la onde quiser. O arquivo de imagem é bastante grande.
Por enquanto pode ser implantado como Cloud Run usando imagem docker, portanto é implantação apenas de API. A ingestão de dados deve ser executada em outra máquina (eu recomendo Compute Engines habilitados para GPU, especialmente se você quiser usar embeddings Hugging Face e porque você pode montar dados do Google Storage diretamente usando gcsfuse ) Solução potencial para usar o bucket GCS com Cloud Correr
Por enquanto, ele pode ser implantado como aplicativos de contêiner (implantação somente de API, você precisa de outra implantação para ingestão)
AWS ainda não é compatível. Em breve.
arxivchat usa text-embedding-ada-002 para OpenAI por padrão, você pode alterar isso em app/tools/factory.py
Por enquanto você pode usar qualquer modelo que funcione com sentence_transformers . Você pode alterar o modelo em app/tools/factory.py
Se você tiver algum problema, use os problemas do GitHub para relatá-los.
Adoraríamos sua ajuda para tornar o arXivchat ainda melhor! Para contribuir, siga estes passos:
arXivchat é lançado sob a licença MIT.


