distrifuser
v0.0.1beta0
[29 de julho de 2024] DistriFusion é compatível com ColossalAI!
[4 de abril de 2024] DistriFusion é selecionada como pôster de destaque no CVPR 2024!
[29 de fevereiro de 2024] DistriFusion é aceito pelo CVPR 2024! Nosso código está disponível publicamente!
 Apresentamos o DistriFusion, um algoritmo sem treinamento para aproveitar várias GPUs para acelerar a inferência do modelo de difusão sem sacrificar a qualidade da imagem. O Naïve Patch (Visão geral (b)) sofre com o problema de fragmentação devido à falta de interação do patch. Os exemplos apresentados são gerados com SDXL usando um amostrador Euler de 50 etapas com resolução de 1280×1920, e a latência é medida em GPUs A100.
Apresentamos o DistriFusion, um algoritmo sem treinamento para aproveitar várias GPUs para acelerar a inferência do modelo de difusão sem sacrificar a qualidade da imagem. O Naïve Patch (Visão geral (b)) sofre com o problema de fragmentação devido à falta de interação do patch. Os exemplos apresentados são gerados com SDXL usando um amostrador Euler de 50 etapas com resolução de 1280×1920, e a latência é medida em GPUs A100.
DistriFusion: Inferência Paralela Distribuída para Modelos de Difusão de Alta Resolução
Muyang Li*, Tianle Cai*, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li e Song Han
MIT, Princeton, Lepton AI e NVIDIA
Em CVPR 2024.
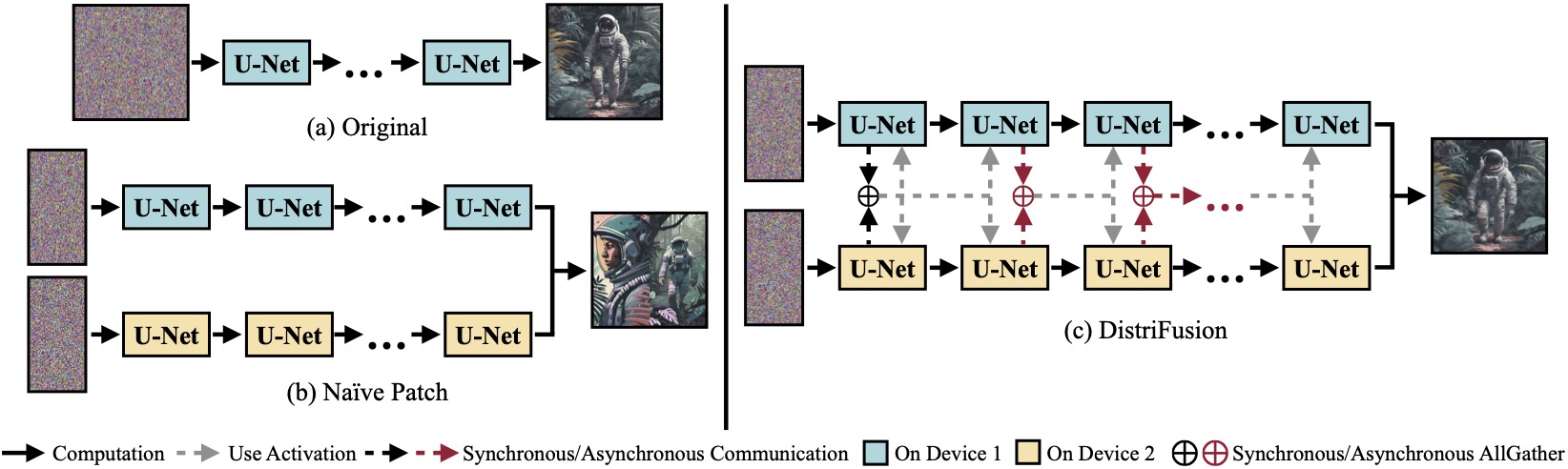 (a) Modelo de difusão original rodando em um único dispositivo. (b) A divisão ingênua da imagem em 2 patches em 2 GPUs tem uma costura evidente no limite devido à ausência de interação entre os patches. (c) Nosso DistriFusion emprega comunicação síncrona para interação de patch na primeira etapa. Depois disso, reaproveitamos as ativações da etapa anterior via comunicação assíncrona. Dessa forma, a sobrecarga de comunicação pode ser ocultada no pipeline de computação.
(a) Modelo de difusão original rodando em um único dispositivo. (b) A divisão ingênua da imagem em 2 patches em 2 GPUs tem uma costura evidente no limite devido à ausência de interação entre os patches. (c) Nosso DistriFusion emprega comunicação síncrona para interação de patch na primeira etapa. Depois disso, reaproveitamos as ativações da etapa anterior via comunicação assíncrona. Dessa forma, a sobrecarga de comunicação pode ser ocultada no pipeline de computação.
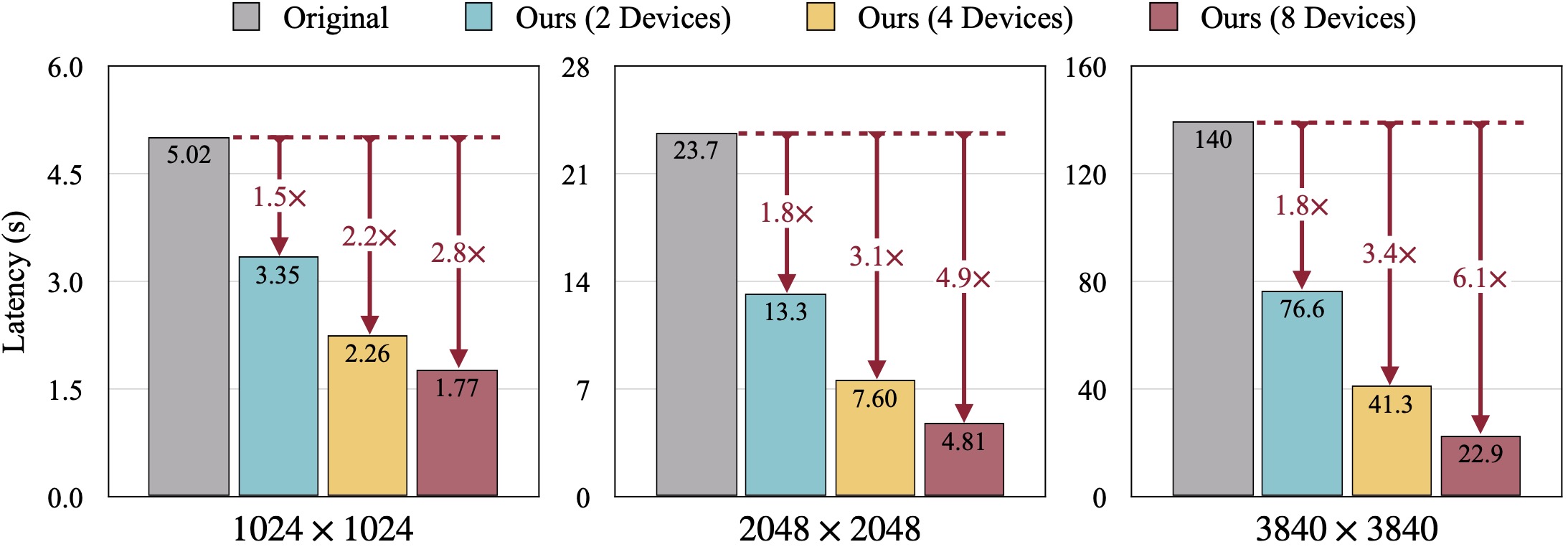
 Resultados qualitativos do SDXL. O FID é calculado em relação às imagens reais. Nosso DistriFusion pode reduzir a latência de acordo com a quantidade de dispositivos utilizados, preservando a fidelidade visual.
Resultados qualitativos do SDXL. O FID é calculado em relação às imagens reais. Nosso DistriFusion pode reduzir a latência de acordo com a quantidade de dispositivos utilizados, preservando a fidelidade visual.
Referências:
Depois de instalar o PyTorch, você poderá instalar distrifuser com PyPI
pip install distrifuserou via GitHub:
pip install git+https://github.com/mit-han-lab/distrifuser.gitou localmente para o desenvolvimento
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e . Em scripts/sdxl_example.py , fornecemos um script mínimo para executar SDXL com DistriFusion.
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" ) Especificamente, nosso distrifuser compartilha as mesmas APIs dos difusores e pode ser usado de maneira semelhante. Você só precisa definir um DistriConfig e usar nosso DistriSDXLPipeline empacotado para carregar o modelo SDXL pré-treinado. Então, podemos gerar a imagem como o StableDiffusionXLPipeline em difusores. O comando de execução é
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py onde $N_GPUS é o número de GPUs que você deseja usar.
Também fornecemos um script mínimo para executar SD1.4/2 com DistriFusion em scripts/sd_example.py . O uso é o mesmo.
Nossos resultados de benchmark estão usando PyTorch 2.2 e difusores 0.24.0. Primeiro, pode ser necessário instalar algumas dependências adicionais:
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid Você pode usar scripts/generate_coco.py para gerar imagens com legendas COCO. O comando é
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
onde $N_GPUS é o número de GPUs que você deseja usar. Por padrão, os resultados gerados serão armazenados em results/coco . Você também pode personalizá-lo com --output_root . Alguns argumentos adicionais que você pode querer ajustar:
--num_inference_steps : o número de etapas de inferência. Usamos 50 por padrão.--guidance_scale : A escala de orientação sem classificador. Usamos 5 por padrão.--scheduler : O amostrador de difusão. Usamos o amostrador DDIM por padrão. Você também pode usar euler para amostrador Euler e dpm-solver para solucionador DPM.--warmup_steps : O número de etapas de aquecimento adicionais (4 por padrão).--sync_mode : Diferentes modos de sincronização GroupNorm. Por padrão, ele usa nosso GroupNorm assíncrono corrigido.--parallelism : O paradigma de paralelismo que você usa. Por padrão, é paralelismo de patch. Você pode usar tensor para paralelismo de tensor e naive_patch para patch ingênuo. Depois de gerar todas as imagens, você pode usar nosso script scripts/compute_metrics.py para calcular PSNR, LPIPS e FID. O uso é
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1 onde $IMAGE_ROOT0 e $IMAGE_ROOT1 são caminhos para as pastas de imagens que você está tentando comparar. Se IMAGE_ROOT0 for o foler verdadeiro, adicione um sinalizador --is_gt para redimensionar. Também fornecemos um script scripts/dump_coco.py para despejar as imagens verdadeiras.
Você pode usar scripts/run_sdxl.py para avaliar a latência de nossos diferentes métodos. O comando é
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent onde $N_GPUS é o número de GPUs que você deseja usar. Semelhante a scripts/generate_coco.py , você também pode alterar alguns argumentos:
--num_inference_steps : o número de etapas de inferência. Usamos 50 por padrão.--image_size : O tamanho da imagem gerada. Por padrão, é 1024×1024.--no_split_batch : Desative a divisão de lote para orientação sem classificador.--warmup_steps : O número de etapas de aquecimento adicionais (4 por padrão).--sync_mode : Diferentes modos de sincronização GroupNorm. Por padrão, ele usa nosso GroupNorm assíncrono corrigido.--parallelism : O paradigma de paralelismo que você usa. Por padrão, é paralelismo de patch. Você pode usar tensor para paralelismo de tensor e naive_patch para patch ingênuo.--warmup_times / --test_times : O número de execuções de aquecimento/teste. Por padrão, são 5 e 20, respectivamente. Se você usar este código para sua pesquisa, cite nosso artigo.
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}Nosso código é desenvolvido com base em huggingface/diffusers e lmxyy/sige. Agradecemos ao torchprofile pela medição de MACs, ao clean-fid pela computação FID e ao Lightning-AI/torchmetrics para PSNR e LPIPS.
Agradecemos a Jun-Yan Zhu e Ligeng Zhu pela discussão útil e feedback valioso. O projeto é apoiado pelo MIT-IBM Watson AI Lab, Amazon, MIT Science Hub e National Science Foundation.


