BeatLearning
1.0.0
Você já quis tocar uma música que não estava disponível no seu jogo de ritmo favorito? Você já quis tocar variações infinitas dessa música?
Este projeto de pesquisa Open Source visa democratizar o processo de criação automática de beatmaps, oferecendo ferramentas acessíveis e modelos básicos para desenvolvedores de jogos, jogadores e entusiastas, abrindo caminho para uma nova era de criatividade e inovação em jogos de ritmo.
Exemplos (mais em breve):
Primeiro você precisará instalar o Python 3.12, ir ao diretório do repositório e criar um ambiente virtual via:
python3 -m venv venv
Em seguida, chame source venv/bin/activate ou venvScriptsactivate se você estiver em uma máquina Windows. Após a ativação do ambiente virtual, você poderá instalar as bibliotecas necessárias por meio de:
pip3 install -r requirements.txt
Você pode usar o Jupyter para acessar os notebooks/ :
jupyter notebook
Você também pode experimentar a versão Google Collab, desde que tenha instâncias de GPU disponíveis (as CPU padrão demoram uma eternidade para converter uma música).
O pipeline suporta apenas beatmaps OSU no momento.
Este repositório ainda é um TRABALHO EM ANDAMENTO . O objetivo é desenvolver modelos generativos capazes de produzir automaticamente beatmaps para uma ampla gama de jogos de ritmo, independentemente da música. Esta pesquisa ainda está em andamento, mas o objetivo é lançar MVPs o mais rápido possível.
Todas as contribuições são valorizadas, especialmente na forma de doações computacionais para modelos de fundação de treinamento. Então, se você estiver interessado, fique à vontade para contribuir!
Junte-se a nós para explorar as infinitas possibilidades de geração de beatmaps orientadas por IA e moldar o futuro dos jogos de ritmo!
Os modelos estão disponíveis no HuggingFace.
Os beatmaps de jogos de ritmo são inicialmente convertidos em um formato de arquivo intermediário, que é então tokenizado em pedaços de 100 ms. Cada token é capaz de codificar até dois eventos diferentes dentro deste período de tempo (retenções e/ou acertos) quantizados com precisão de 10ms. O vocabulário do tokenizer é pré-calculado em vez de aprendido com os dados para atender a esse critério. A extensão do contexto e o tamanho do vocabulário são intencionalmente mantidos pequenos devido à escassez de exemplos de treinamento de qualidade na área.
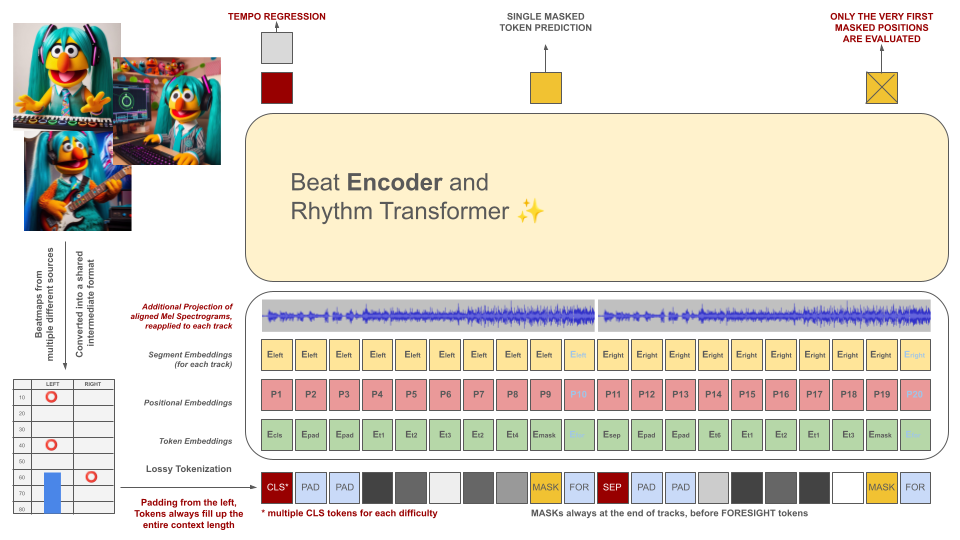 Esses tokens, juntamente com fatias dos dados de áudio (seu espectro Mel projetado alinhado com os tokens), servem como entradas para um modelo de codificador mascarado. Semelhante ao BeRT, o modelo do codificador tem dois objetivos durante o treinamento: estimar o andamento por meio de uma tarefa de regressão e prever o(s) próximo(s) token(s) mascarado(s) por meio de uma função de perda auditiva . Beatmaps com 1, 2 e 4 faixas são suportados. Cada token é previsto da esquerda para a direita, espelhando o processo de geração de uma arquitetura decodificadora. No entanto, os tokens mascarados também têm acesso a informações de áudio adicionais do futuro, denotadas como tokens de previsão à direita.
Esses tokens, juntamente com fatias dos dados de áudio (seu espectro Mel projetado alinhado com os tokens), servem como entradas para um modelo de codificador mascarado. Semelhante ao BeRT, o modelo do codificador tem dois objetivos durante o treinamento: estimar o andamento por meio de uma tarefa de regressão e prever o(s) próximo(s) token(s) mascarado(s) por meio de uma função de perda auditiva . Beatmaps com 1, 2 e 4 faixas são suportados. Cada token é previsto da esquerda para a direita, espelhando o processo de geração de uma arquitetura decodificadora. No entanto, os tokens mascarados também têm acesso a informações de áudio adicionais do futuro, denotadas como tokens de previsão à direita.
O objetivo do modelo de IA não é desvalorizar beatmaps criados individualmente, mas sim:
Todo o conteúdo gerado deve cumprir os regulamentos da UE e ser devidamente rotulado, incluindo metadados que indiquem o envolvimento do modelo de IA.
A GERAÇÃO DE BEATMAPS PARA MATERIAL PROTEGIDO POR DIREITOS AUTORAIS É ESTRITAMENTE PROIBIDA! USE SOMENTE MÚSICAS SOBRE AS QUAIS VOCÊ POSSA DIREITOS!
O áudio apresentado nos exemplos de arquivos da OSU é originário de artistas listados no site da OSU na seção artistas em destaque e é licenciado para uso especificamente em conteúdo relacionado ao osu!.
Para evitar que seu beatmap seja utilizado como dados de treinamento no futuro, inclua os seguintes metadados em seu arquivo de beatmap:
robots: disallow
O projeto se inspira em uma tentativa anterior conhecida como AIOSU.
Além de contar com o wiki da OSU, o osu-parser tem sido fundamental para esclarecer as declarações do beatmap (especialmente os sliders). O modelo do transformador foi influenciado pelo NanoGPT e pela implementação pytorch do BeRT.


