horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod é uma estrutura de treinamento de aprendizagem profunda distribuída para TensorFlow, Keras, PyTorch e Apache MXNet. O objetivo do Horovod é tornar o aprendizado profundo distribuído rápido e fácil de usar.
Horovod é hospedado pela LF AI & Data Foundation (LF AI & Data). Se você é uma empresa profundamente comprometida com o uso de tecnologias de código aberto em inteligência artificial, máquina e aprendizado profundo e deseja apoiar comunidades de projetos de código aberto nesses domínios, considere ingressar na LF AI & Data Foundation. Para obter detalhes sobre quem está envolvido e como o Horovod desempenha um papel, leia o anúncio da Linux Foundation.
Conteúdo
A principal motivação para este projeto é facilitar a utilização de um script de treinamento de GPU única e escalá-lo com sucesso para treinar em muitas GPUs em paralelo. Isto tem dois aspectos:
Internamente na Uber, descobrimos que o modelo MPI é muito mais direto e exige muito menos alterações de código do que soluções anteriores, como o Distributed TensorFlow com servidores de parâmetros. Depois que um script de treinamento for escrito para escalar com Horovod, ele poderá ser executado em uma única GPU, em várias GPUs ou até mesmo em vários hosts sem quaisquer alterações adicionais no código. Consulte a seção Uso para obter mais detalhes.
Além de fácil de usar, o Horovod é rápido. Abaixo está um gráfico que representa o benchmark feito em 128 servidores com 4 GPUs Pascal, cada uma conectada por uma rede de 25 Gbit/s compatível com RoCE:
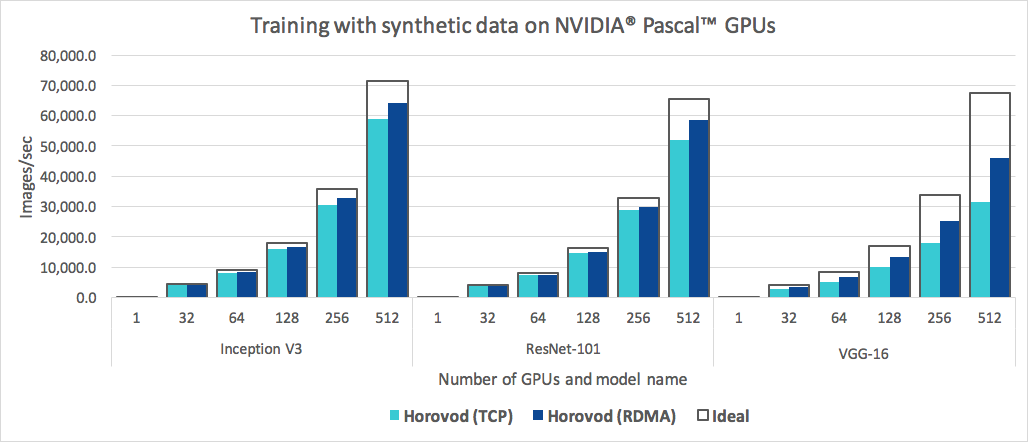
Horovod atinge 90% de eficiência de escalonamento para Inception V3 e ResNet-101 e 68% de eficiência de escalonamento para VGG-16. Consulte Benchmarks para descobrir como reproduzir esses números.
Embora a instalação do MPI e do NCCL possa parecer um incômodo extra, ela só precisa ser feita uma vez pela equipe que lida com a infraestrutura, enquanto todos os demais na empresa que constroem os modelos podem aproveitar a simplicidade de treiná-los em escala.
Para instalar o Horovod no Linux ou macOS:
Se você instalou o TensorFlow do PyPI, certifique-se de que g++-5 ou superior esteja instalado. A partir do TensorFlow 2.10, será necessário um compilador compatível com C++17, como g++8 ou superior.
Se você instalou o PyTorch do PyPI, certifique-se de que g++-5 ou superior esteja instalado.
Se você instalou qualquer um dos pacotes do Conda, certifique-se de que o pacote gxx_linux-64 Conda esteja instalado.
Instale o pacote horovod pip.
Para rodar em CPUs:
$ pip install horovodPara executar em GPUs com NCCL:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodPara obter mais detalhes sobre a instalação do Horovod com suporte para GPU, leia Horovod na GPU.
Para obter a lista completa de opções de instalação do Horovod, leia o Guia de instalação.
Se você quiser usar MPI, leia Horovod com MPI.
Se você quiser usar o Conda, leia Construindo um ambiente Conda com suporte de GPU para Horovod.
Se você quiser usar o Docker, leia Horovod no Docker.
Para compilar o Horovod a partir da fonte, siga as instruções no Guia do Colaborador.
Os princípios básicos do Horovod são baseados em conceitos MPI como tamanho , classificação , classificação local , allreduce , allgather , broadcast e alltoall . Veja esta página para mais detalhes.
Consulte estas páginas para exemplos e práticas recomendadas do Horovod:
Para usar o Horovod, faça as seguintes adições ao seu programa:
hvd.init() para inicializar o Horovod.Fixe cada GPU em um único processo para evitar contenção de recursos.
Com a configuração típica de uma GPU por processo, defina-a como classificação local . O primeiro processo no servidor receberá a primeira GPU, o segundo processo receberá a segunda GPU e assim por diante.
Dimensione a taxa de aprendizagem pelo número de trabalhadores.
O tamanho efetivo do lote no treinamento distribuído síncrono é dimensionado pelo número de trabalhadores. Um aumento na taxa de aprendizagem compensa o aumento do tamanho do lote.
Envolva o otimizador em hvd.DistributedOptimizer .
O otimizador distribuído delega a computação de gradiente ao otimizador original, calcula a média dos gradientes usando allreduce ou allgather e, em seguida, aplica esses gradientes médios.
Transmita os estados iniciais das variáveis da classificação 0 para todos os outros processos.
Isto é necessário para garantir uma inicialização consistente de todos os trabalhadores quando o treinamento é iniciado com pesos aleatórios ou restaurado a partir de um ponto de verificação.
Exemplo de uso do TensorFlow v1 (consulte o diretório de exemplos para obter exemplos completos de treinamento):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )Os comandos de exemplo abaixo mostram como executar o treinamento distribuído. Consulte Executar Horovod para obter mais detalhes, incluindo ajustes de RoCE/InfiniBand e dicas para lidar com travamentos.
Para rodar em uma máquina com 4 GPUs:
$ horovodrun -np 4 -H localhost:4 python train.pyPara rodar em 4 máquinas com 4 GPUs cada:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py Para executar usando Open MPI sem o wrapper horovodrun , consulte Executando Horovod com Open MPI.
Para executar no Docker, consulte Horovod no Docker.
Para executar no Kubernetes, consulte Helm Chart, Kubeflow MPI Operator, FfDL e Polyaxon.
Para executar no Spark, consulte Horovod no Spark.
Para rodar em Ray, consulte Horovod em Ray.
Para executar no Singularity, consulte Singularity.
Para executar em um cluster LSF HPC (por exemplo, Summit), consulte LSF.
Para executar no Hadoop Yarn, consulte TonY.
Gloo é uma biblioteca de comunicação coletiva de código aberto desenvolvida pelo Facebook.
O Gloo vem incluído no Horovod e permite que os usuários executem o Horovod sem a necessidade de instalação do MPI.
Para ambientes que suportam MPI e Gloo, você pode optar por usar o Gloo em tempo de execução passando o argumento --gloo para horovodrun :
$ horovodrun --gloo -np 2 python train.pyHorovod suporta misturar e combinar coletivos Horovod com outras bibliotecas MPI, como mpi4py, desde que o MPI tenha sido construído com suporte multi-threading.
Você pode verificar o suporte multithreading MPI consultando a função hvd.mpi_threads_supported() .
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()Você também pode inicializar o Horovod com um subcomunicador mpi4py; nesse caso, cada subcomunicador executará um treinamento Horovod independente.
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))Aprenda como otimizar seu modelo para inferência e remover operações Horovod do gráfico aqui.
Uma das coisas únicas do Horovod é sua capacidade de intercalar comunicação e computação, juntamente com a capacidade de agrupar pequenas operações allreduce , o que resulta em melhor desempenho. Chamamos esse recurso de lote de Tensor Fusion.
Veja aqui para obter detalhes completos e instruções de ajustes.
Horovod tem a capacidade de registrar a linha do tempo de sua atividade, chamada Horovod Timeline.
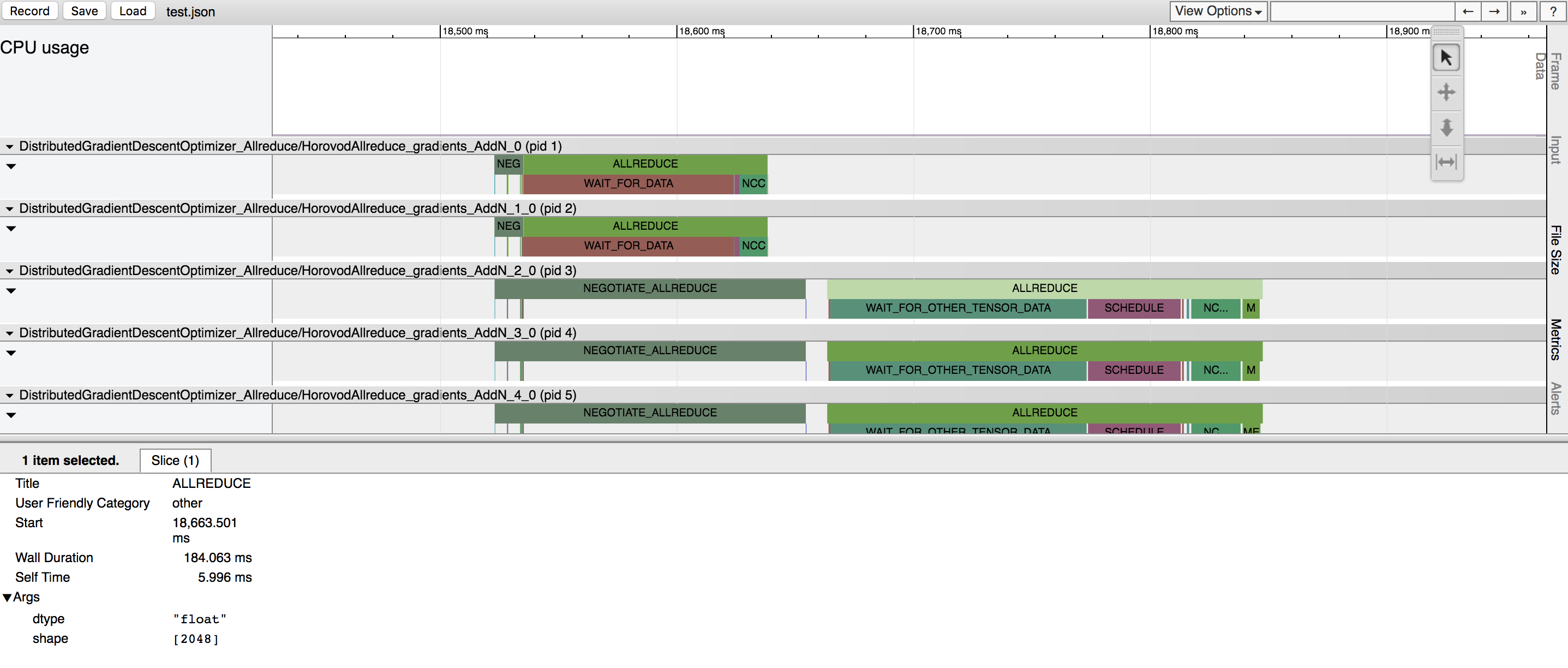
Use a linha do tempo do Horovod para analisar o desempenho do Horovod. Veja aqui todos os detalhes e instruções de uso.
Selecionar os valores certos para fazer uso eficiente do Tensor Fusion e outros recursos avançados do Horovod pode envolver uma boa quantidade de tentativa e erro. Fornecemos um sistema para automatizar esse processo de otimização de desempenho chamado autotuning , que você pode ativar com um único argumento de linha de comando para horovodrun .
Veja aqui todos os detalhes e instruções de uso.
Horovod permite executar simultaneamente operações coletivas distintas em diferentes grupos de processos que participam de um treinamento distribuído. Configure objetos hvd.process_set para usar esse recurso.
Consulte Conjuntos de processos para obter instruções detalhadas.
Envie-nos links para quaisquer guias do usuário que você deseja publicar neste site
Consulte Solução de problemas e envie um ticket se não encontrar uma resposta.
Por favor, cite Horovod em suas publicações se isso ajudar em sua pesquisa:
@artigo{sergeev2018horovod,
Autor = {Alexander Sergeev e Mike Del Balso},
Diário = {pré-impressão arXiv arXiv:1802.05799},
Title = {Horovod: aprendizado profundo distribuído rápido e fácil em {TensorFlow}},
Ano = {2018}
}
1. Sergeev, A., Del Balso, M. (2017) Conheça Horovod: Estrutura de aprendizagem profunda distribuída de código aberto da Uber para TensorFlow . Obtido em https://eng.uber.com/horovod/
2. Sergeev, A. (2017) Horovod - TensorFlow distribuído facilitado . Obtido em https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A., Del Balso, M. (2018) Horovod: aprendizado profundo distribuído rápido e fácil no TensorFlow . Obtido de arXiv:1802.05799
O código-fonte do Horovod foi baseado no repositório Baidu tensorflow-allreduce escrito por Andrew Gibiansky e Joel Hestness. Seu trabalho original é descrito no artigo Trazendo técnicas de HPC para aprendizado profundo.


