gptty
0.2.7
Wrapper ChatGPT em seu TTY
Observação
Esta versão suporta gpt4 e gpt4-turbo!
gptty é uma interface shell ChatGPT que permite (1) interagir com ChatGPT de maneira semelhante à aplicação web, mas sem precisar depender da estabilidade da aplicação web; (2) preserve o contexto nas sessões de bate-papo e estruture suas conversas da maneira que desejar; (3) salve cópias locais de suas conversas para fácil referência.
Talvez você seja um administrador de sistema configurando um servidor web para seu empregador. Você está acessando o sistema a partir de uma interface física, com conexão à Internet, mas sem ambiente de desktop ou interface gráfica de usuário. Ao configurar o servidor da web, você recebe um erro inexplicável que redireciona para um arquivo, mas não quer ter que se esforçar para copiá-lo para outro sistema com um navegador para poder procurar o erro. Em vez disso, você instala o gptty e redireciona o erro para o cliente de bate-papo com comandos como gptty query --tag error --question "$(cat app.error | tr 'n' ' ')" (que eliminará quebras de linha para você) ou cat app.error | xargs -d 'n' -I {} gptty query --tag error --question "{}" (que presume que seu erro abrange apenas uma única linha).
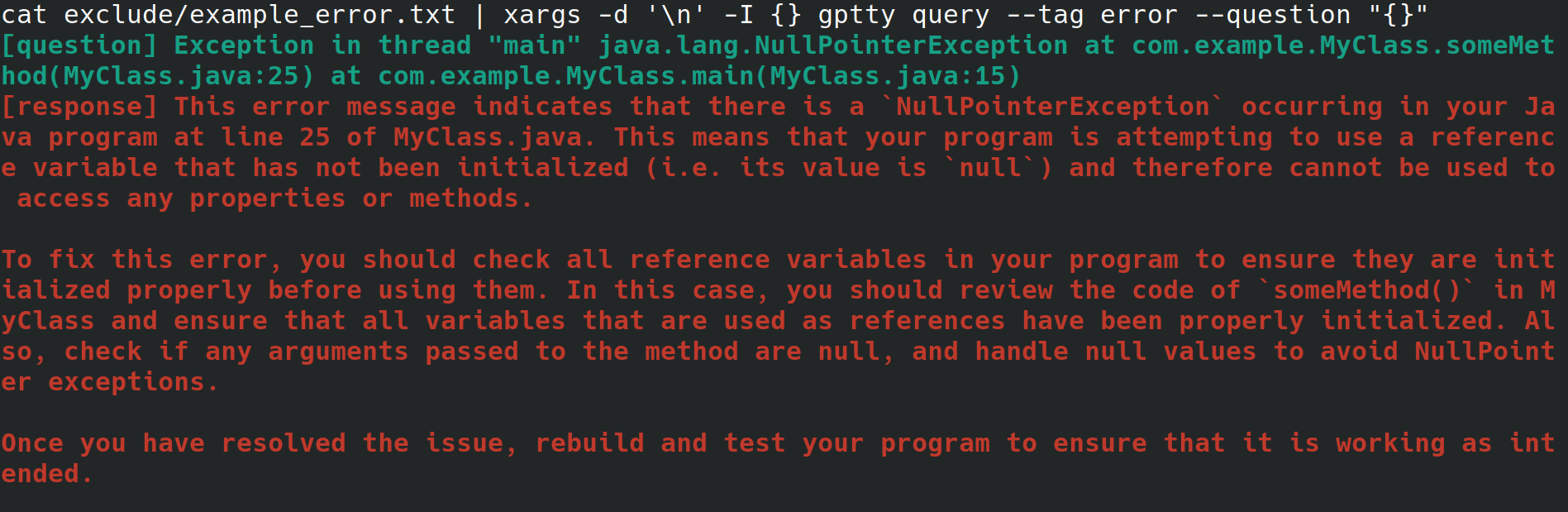
Como alternativa, você é um desenvolvedor de software ou cientista de dados que deseja canalizar dados por meio do ChatGPT, mas deseja empregar uma API altamente abstrata para fazer essas solicitações, em vez de se familiarizar intimamente com a API OpenAI e seus vários wrappers específicos de linguagem. Quando você deseja atualizar sua base de código para usar um modelo diferente, você deseja modificar apenas um único arquivo de configuração e esperar que o formato de resposta da consulta permaneça consistente em vários modelos.
Ou talvez você seja um entusiasta que deseja manter cópias locais de suas conversas ou exercer um controle mais direto sobre os métodos de categorização empregados para essas conversas.
OpenAI disponibiliza vários modelos por meio de sua API. [1] Atualmente, gptty suporta Completions (davinci, curie) e ChatCompletions (gpt-3.5-turbo, gpt-4). Tudo o que você precisa fazer é especificar o nome do modelo em sua configuração (o padrão é text-davinci-003) e o aplicativo cuidará do resto.
Você pode instalar gptty no pip:
pip install gptty
Você também pode instalar a partir do git:
cd ~/Code # replace this with whatever directory you want to use
git clone https://github.com/signebedi/gptty.git
cd gptty/
# now install the requirements
python3 -m venv venv
source venv/bin/activate
pip install -e .
Agora você pode verificar se está funcionando executando gptty --help . Se ocorrer um erro, tente configurar o aplicativo.
gptty lê as definições de configuração de um arquivo chamado gptty.ini , que o aplicativo espera estar localizado no mesmo diretório em que você está executando gptty , a menos que você passe um config_file personalizado. O arquivo usa o formato de arquivo INI, que consiste em seções, cada uma com seus próprios pares de valores-chave.
| Chave | Tipo | Valor padrão | Descrição |
|---|---|---|---|
| chave_api | Corda | "" | Sua chave API para o serviço GPT da OpenAI |
| id_org | Corda | "" | O ID da sua organização para o serviço GPT da OpenAI |
| seu_nome | Corda | "pergunta" | O nome do prompt de entrada |
| nome_gpt | Corda | "resposta" | O nome da resposta gerada |
| arquivo_de_saída | Corda | "saída.txt" | O nome do arquivo onde a saída será salva |
| modelo | Corda | "texto-davinci-003" | O nome do modelo GPT a ser usado |
| temperatura | Flutuador | 0,0 | A temperatura a ser usada para amostragem |
| max_tokens | Inteiro | 250 | O número máximo de tokens a serem gerados para a resposta |
| max_context_length | Inteiro | 150 | O comprimento máximo do contexto de entrada |
| context_keywords_only | Bool | Verdadeiro | Tokenize palavras-chave para reduzir o uso da API |
| preserve_new_lines | Bool | Falso | Mantenha a formatação original da resposta |
| verificar_internet_endpoint | Corda | "google. com" | Endereço para validar conexão com a internet |
Você pode modificar as configurações no arquivo de configuração para atender às suas necessidades. Se uma chave não estiver presente no arquivo de configuração, o valor padrão será usado. A seção [principal] é usada para especificar as configurações do programa.
[main]
api_key =my_api_key Este repositório fornece um arquivo de configuração de amostra assets/gptty.ini.example que você pode usar como ponto de partida.
O recurso de bate-papo fornece uma interface de bate-papo interativa para comunicação com o ChatGPT. Você pode fazer perguntas e receber respostas em tempo real.
Para iniciar a interface de bate-papo, execute gptty chat . Você também pode especificar um caminho de arquivo de configuração personalizado executando:
gptty chat --config_path /path/to/your/gptty.ini
Dentro da interface de chat, você pode digitar suas perguntas ou comandos diretamente. Para visualizar a lista de comandos disponíveis, digite :help , que mostrará as seguintes opções.
| Metacomando | Descrição |
|---|---|
| :ajuda | Exiba uma lista de comandos disponíveis e suas descrições. |
| :desistir | Saia do ChatGPT. |
| :registros | Exibir as definições de configuração atuais. |
| :contexto[a:b] | Exiba o histórico de contexto, especificando opcionalmente um intervalo a e b. Em desenvolvimento |
Para usar um comando, basta digitá-lo no prompt de comando e pressionar Enter. Por exemplo, use o seguinte comando para exibir as definições de configuração atuais no terminal:
> :configs
api_key: SOME_KEY_HERE
org_id: org-SOME_CHARS_HERE
your_name: question
gpt_name: response
output_file: output.txt
model: text-davinci-003
temperature: 0.0
max_tokens: 250
max_context_length: 5000
Você pode digitar uma pergunta no prompt a qualquer momento e isso gerará uma resposta para você. Se desejar compartilhar contexto entre consultas, consulte a seção de contexto abaixo.
O recurso de consulta permite enviar uma ou várias perguntas ao ChatGPT e receber as respostas diretamente na linha de comando.
Para usar o recurso de consulta, execute algo como:
gptty query --question "What is the capital of France?" --question "What is the largest mammal?"
Você também pode fornecer uma tag opcional para categorizar sua consulta:
gptty query --question "What is the capital of France?" --tag "geography"
Você pode especificar um caminho de arquivo de configuração personalizado, se necessário:
gptty query --config_path /path/to/your/gptty.ini --question "What is the capital of France?"
Lembre-se de que o gptty usa um arquivo de configuração (por padrão, gptty.ini) para armazenar configurações como chaves de API, configurações de modelo e caminhos de arquivo de saída. Certifique-se de ter um arquivo de configuração válido antes de executar comandos gptty.
Ao adicionar a tag --verbose no final dos comandos de chat e consulta, o aplicativo fornecerá dados de depuração adicionais, incluindo contagens de tokens para cada solicitação. Isso pode ser útil quando você precisa monitorar as taxas de uso da API.

Ao adicionar a opção --additional_context [some_string_here] aos seus comandos de consulta, o aplicativo adicionará qualquer string que você passar como adicional, fora do contexto da sua pergunta.
Ao adicionar a tag --json no final dos comandos de consulta, o aplicativo irá ignorar a gravação de texto legível por humanos no stdout e, em vez disso, escreverá as perguntas e respostas como objetos json como [{"question":QUESTION_1, "response":RESPONSE_1},{"question":QUESTION_1, "response":RESPONSE_1},...] .

Ao adicionar a tag --quiet no final dos comandos de consulta, o aplicativo irá ignorar a gravação de qualquer coisa no stdout, mas ainda gravará respostas no output_file designado no arquivo de configuração do aplicativo.
Marcar texto para contexto ao usar os subcomandos chat e query neste aplicativo pode ajudar a melhorar a precisão das respostas geradas. Veja como o aplicativo lida com o contexto com o subcomando chat :
bananas ou shakespeare .[tag] . Por exemplo, se o contexto da sua pergunta for "cozinhar", você poderá marcá-la como [cooking] . Certifique-se de usar a mesma tag de forma consistente para todas as consultas relacionadas. Aqui está um exemplo de como isso pode ser, usando perguntas marcadas como [shakespeare] . Observe como, na segunda questão, o nome 'William Shakespeare' não é mencionado.
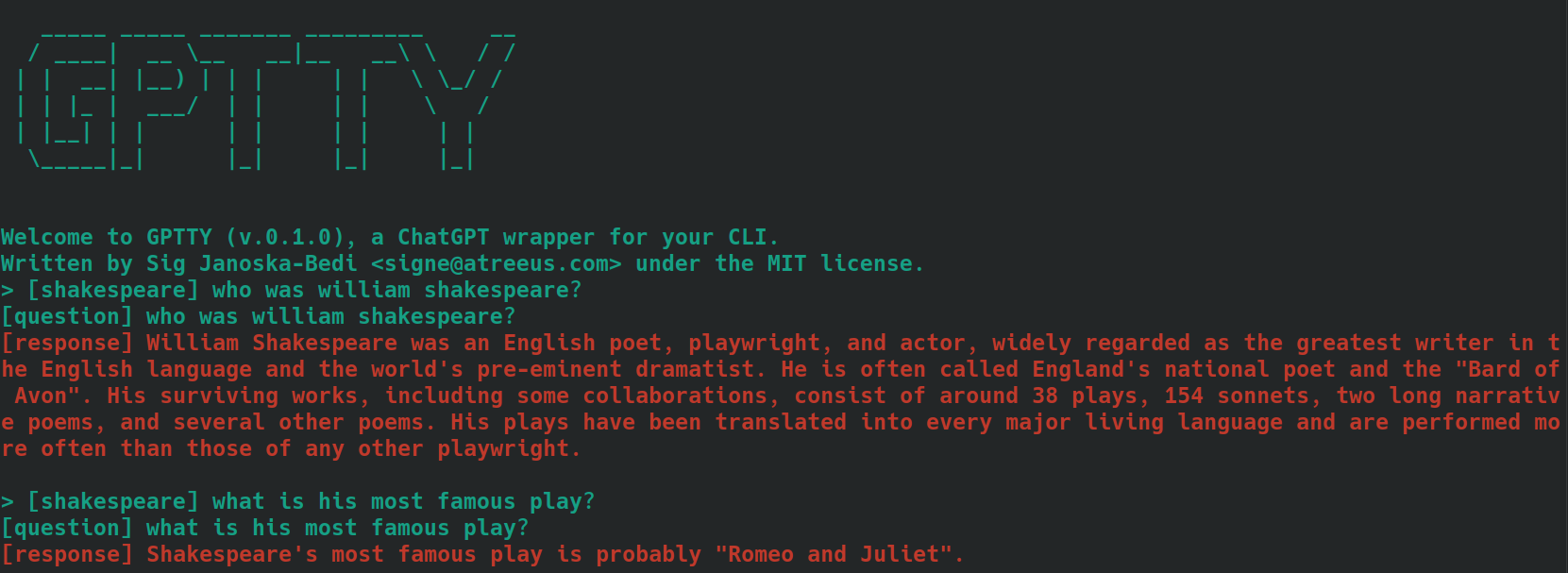
Ao usar o subcomando query , siga as mesmas etapas descritas acima, mas, em vez de preceder o texto de suas perguntas com a tag desejada, use a opção --tag para incluir a tag ao enviar sua consulta. Por exemplo, se o contexto da sua pergunta for “culinária”, você poderá usar:
gptty --question "some question" --tag cooking
O aplicativo salvará sua pergunta e resposta marcadas no arquivo de saída especificado no arquivo de configuração.
Você pode automatizar o processo de envio de várias perguntas para o comando gptty query usando um script bash. Isso pode ser particularmente útil se você tiver uma lista de perguntas armazenadas em um arquivo e quiser processá-las todas de uma vez. Por exemplo, digamos que você tenha um arquivo questions.txt com cada pergunta em uma nova linha, como abaixo.
What are the key differences between machine learning, deep learning, and artificial intelligence?
How do I choose the best programming language for a specific project or task?
Can you recommend some best practices for code optimization and performance improvement?
What are the essential principles of good software design and architecture?
How do I get started with natural language processing and text analysis in Python?
What are some popular Python libraries or frameworks for building web applications?
Can you suggest some resources to learn about data visualization and its implementation in Python?
What are some important concepts in cybersecurity, and how can I apply them to my projects?
How do I ensure that my machine learning models are fair, ethical, and unbiased?
Can you recommend strategies for staying up-to-date with the latest trends and advancements in technology and programming?
Você pode enviar cada pergunta do arquivo questions.txt para o comando gptty query usando a seguinte linha bash:
xargs -d ' n ' -I {} gptty query --question " {} " < questions.txt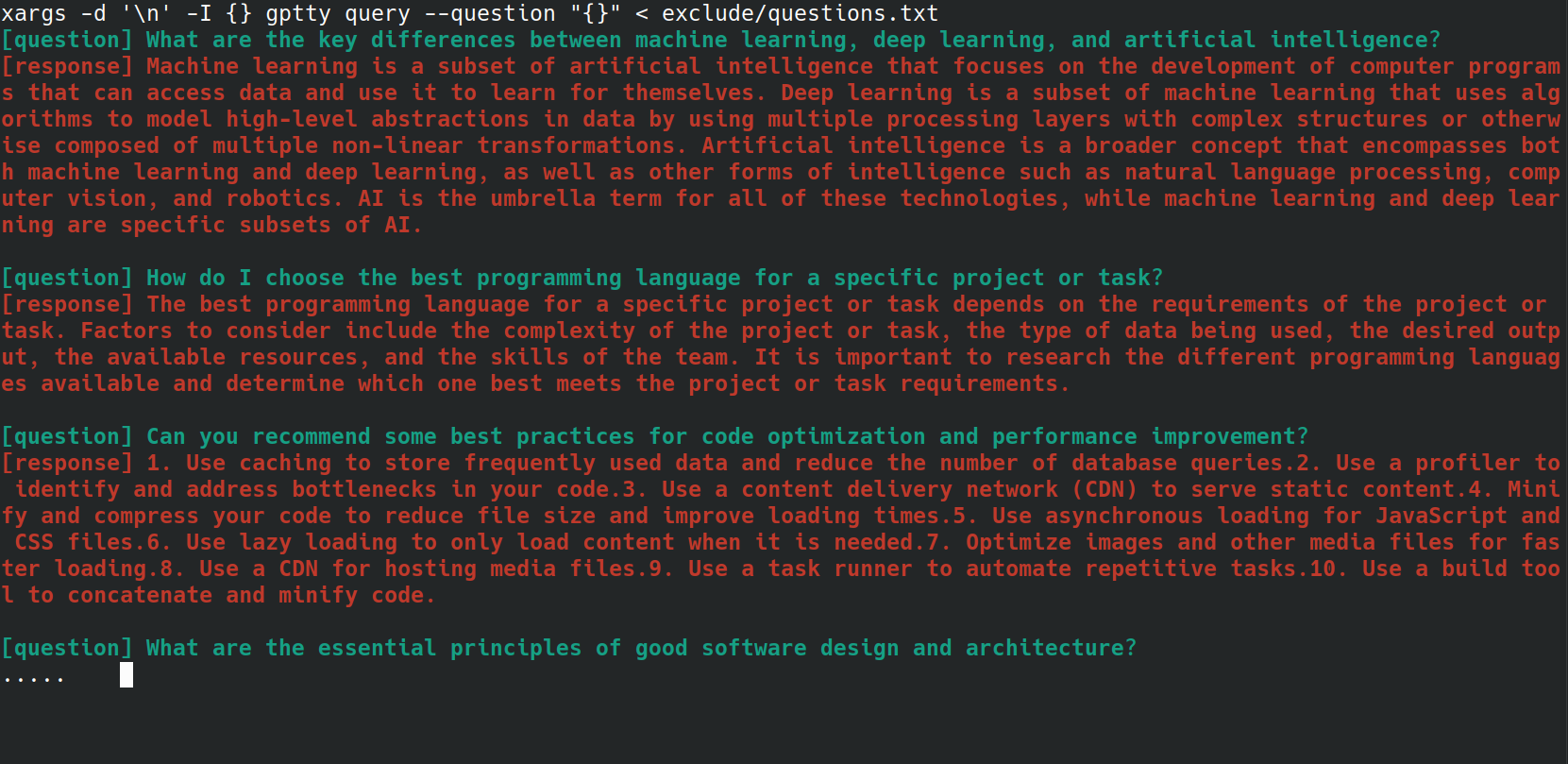
A classe UniversalCompletion fornece uma interface unificada para interagir com os modelos de linguagem OpenAI, (principalmente) abstraindo as especificidades de se o aplicativo está usando o modo Completion ou ChatCompletion. A ideia principal é facilitar a criação, configuração e gerenciamento dos modelos de linguagem. Aqui está um exemplo de uso.
# First, import the UniversalCompletion class from the gptty library.
from gptty import UniversalCompletion
# Now, we instantiate a new UniversalCompletion object.
# The 'api_key' parameter is your OpenAI API key, which you get when you sign up for the API.
# The 'org_id' parameter is your OpenAI organization ID, which is also provided when you sign up.
g = UniversalCompletion ( api_key = "sk-SOME_CHARS_HERE" , org_id = "org-SOME_CHARS_HERE" )
# This connects to the OpenAI API using the provided API key and organization ID.
g . connect ()
# Now we specify which language model we want to use.
# Here, 'gpt-3.5-turbo' is specified, which is a version of the GPT-3 model.
g . set_model ( 'gpt-3.5-turbo' )
# This method is used to verify the model type.
# It returns a string that represents the endpoint for the current model in use.
g . validate_model_type ( g . model ) # Returns: 'v1/chat/completions'
# We send a request to the language model here.
# The prompt is a question, given in a format that the model understands.
# The model responds with a completion - an extension of the prompt based on what it has learned during training.
# The returned object is a representation of the response from the model.
g . fetch_response ( prompt = [{ "role" : "user" , "content" : "What is an abstraction?" }])
# Returns a JSON response with the assistant's message.

