Guia completo de difusão estável - de iniciante a especialista
Fiquei interessado em usar SD para gerar imagens para aplicações militares. A maior parte dos recursos é retirada dos fóruns NSFW do 4chan, já que os Anons usam SD para fazer hentai. Curiosamente, o SD WebUI canônico tem funcionalidade integrada com painéis de imagens de anime/hentai... Um dos primeiros casos de uso de SD logo após DALL-E estava gerando garotas de anime, então o salto para hentai não é surpreendente.
De qualquer forma, as técnicas desses esquisitos são aplicáveis a uma variedade de aplicações, mais especificamente LoRAs, que são como modelos de sintonizadores finos. A ideia é trabalhar com LoRAs específicos (por exemplo, veículos militares, aeronaves, armas, etc.) para gerar dados de imagens sintéticas para treinamento de modelos de visão. A formação de LoRAs novos e úteis também é de interesse. Coisas posteriores podem incluir pintura interna para perturbação.
Isenção de responsabilidade e fontes
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
Brinque com isso!
O que você realmente pode fazer com SD? Huggingface e alguns outros têm alguns aplicativos no navegador para você. Brinque com eles para ver o poder! O que faremos neste guia é obter a WebUI completa e extensível para nos permitir fazer tudo o que quisermos.
- Huggingface texto para imagem SD Playground
- Aplicativo Dreamstudio de texto para imagem SD
- Aplicativo Dezgo de texto para imagem SD
- Huggingface imagem para imagem SD Playground
- Parque de pintura Huggingface
Índice
- Noções básicas de WebUI
- Configurar o uso da GPU local
- Configuração do Linux
- Indo mais fundo
- Solicitando
- Modelo NovelAI
- LoRA
- Brincando com modelos
- VAEs
- Junte tudo
- O Processo Geral de SD
- Salvando prompts
- Configurações do txt2img
- Regenerando uma imagem gerada anteriormente
- Solução de erros
- Ficando confortável
- Teste
- WebUI Avançado
- Edição imediata
- Xformers
- Img2Img
- Pintura
- Extras
- Redes de controle
- Fazendo coisas novas (WIP)
- Fusão de ponto de verificação
- Treinamento de LoRAs
- Treinando Novos Modelos
- Configuração do Google Colab (WIP)
- Meio da jornada
- Parâmetros MJ
- Solicitações avançadas de MJ
- DreamStudio (WIP)
- Horda Estável (WIP)
- Dream Booth (WIP)
- Difusão de Vídeo (WIP)
Noções básicas de WebUI
É um pouco assustador entrar nisso... mas o 4channers fez um bom trabalho tornando isso acessível. Abaixo estão as etapas que executei, nos termos mais simples. Sua intenção é fazer com que o Stable Diffusion WebUI (construído com Gradio) seja executado localmente para que você possa começar a solicitar e criar imagens.
Configurar o uso da GPU local
Faremos a configuração do Google Colab Pro mais tarde, para que possamos executar o SD em qualquer dispositivo em qualquer lugar que desejarmos; mas para começar, vamos configurar a WebUI em um PC. Você precisa de 16 GB de RAM, uma GPU com 2 GB de VRAM, Windows 7+ e 20+ GB de espaço em disco.
- Conclua o guia de configuração inicial
- Eu segui isso até a etapa 7, após a qual entramos no material hentai
- A etapa 3 leva de 15 a 45 minutos na velocidade média da Internet, já que os modelos têm mais de 5 GB cada
- A etapa 7 pode levar mais de meia hora e pode parecer "travada" na CLI
- Na etapa 3 baixei o SD1.5, não as versões 2.x, pois 1.5 produz resultados muito melhores
- CivitAI possui todos os modelos SD; é como HuggingFace, mas especificamente para SD
- Verifique se o WebUI funciona
- Copie a URL que a CLI gera quando terminar, por exemplo,
127.0.0.1:7860 ( NÃO use Ctrl + C porque este comando pode fechar a CLI) - Cole no navegador e pronto; tente um prompt e você estará pronto para as corridas
- As imagens serão salvas automaticamente quando geradas em
stable-diffusion-webuioutputstxt2img-images<date>
- Lembre-se, para atualizar, basta abrir uma CLI na pasta stable-diffusion-webui e digitar o comando
git pull
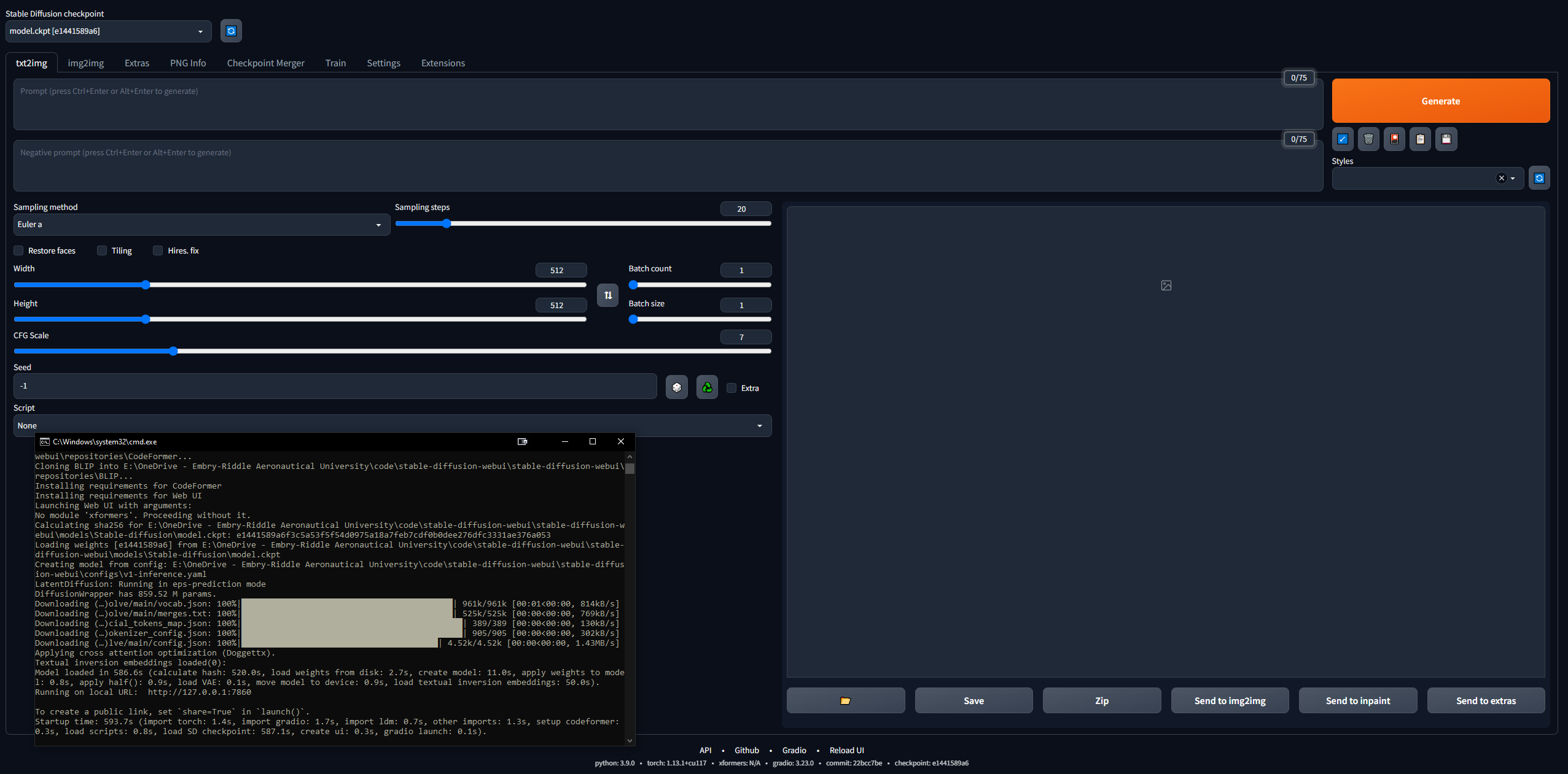
Configuração do Linux
Ignore isso completamente se você tiver o Windows. Também consegui fazê-lo rodar no Linux, embora seja um pouco mais complicado. Comecei seguindo este guia, mas ele está mal escrito, então abaixo estão as etapas que executei para executá-lo no Linux. Eu estava usando o Linux Mint 20, que é uma distribuição do Ubuntu 20.
- Comece clonando o repositório webui:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - Obtenha um modelo SD (por exemplo, SD 1.5, como na seção anterior)
- Coloque o arquivo ckpt do modelo
stable-diffusion-webui/models/Stable-diffusion - Baixe Python (se ainda não o tiver):
sudo apt install python3 python3-pip python3-virtualenv wget git - E a WebUI é muito particular, então precisamos instalar o Conda, um gerenciador de ambiente virtual, para funcionar dentro de:
wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- Agora crie o ambiente:
conda create --name sdwebui python=3.10.6 - Ative o ambiente:
conda activate sdwebui - Navegue até a pasta WebUI e digite
./webui.sh - Ele deve ser executado por um tempo até você receber um erro sobre não conseguir acessar CUDA/sua GPU... tudo bem, porque é o nosso próximo passo
- Comece limpando todos os drivers Nvidia existentes:
sudo apt update
sudo apt purge *nvidia*
- Agora, seguindo alguns trechos deste guia, descubra qual GPU sua máquina Linux possui (a maneira mais fácil de fazer isso é abrir o aplicativo Driver Manager e sua GPU será listada; mas há uma dúzia de maneiras, basta pesquisar no Google)
- Vá para esta página e clique em "Latest New Feature Branch" no Linux x86_64 (para mim, era 530.xx.xx)
- Clique na aba “Produtos Suportados” e Ctrl + F para encontrar sua GPU; se estiver listado, prossiga; caso contrário, volte e tente "Versão mais recente da filial de produção"; anote o número, por exemplo, 530
- Em um terminal, digite:
sudo add-apt-repository ppa:graphics-drivers/ppa - Atualizar com
sudo apt-get update - Inicie o aplicativo Driver Manager e você verá uma lista deles; NÃO selecione o recomendado (por exemplo, nvidia-driver-530-open), selecione exatamente o anterior (por exemplo, nvidia-driver-530) e Aplicar alterações; OU instale-o no terminal com
sudo apt-get install nvidia-driver-530 - NESTE PONTO, você deverá receber um pop-up em sua CLI sobre inicialização segura, solicitando uma senha de 8 dígitos: defina-a e anote-a
- Reinicie o seu PC e antes da criptografia/login do usuário, você deverá ver uma tela semelhante à do BIOS (estou escrevendo isso da memória) com a opção de inserir uma chave MOK; clique nele e digite sua senha, depois envie e inicialize; algumas informações aqui
- Faça login normalmente e digite o comando
nvidia-smi ; se for bem-sucedido, deverá imprimir uma tabela; caso contrário, dirá algo como "Não foi possível conectar à GPU; certifique-se de que o driver mais atualizado esteja instalado" - Agora, para instalar o CUDA (o último comando aqui deve imprimir algumas informações sobre sua nova instalação do CUDA); deste guia:
sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
- Agora volte e execute as etapas 7 a 9; se você receber este "ERRO: Não é possível ativar python venv, abortando...", vá para a próxima etapa (caso contrário, você estará pronto para as corridas e copiará o endereço IP da CLI normalmente e poderá começar a jogar com SD)
- Este problema do Github tem algumas soluções para esse problema de venv... para mim, o que funcionou foi rodar
python3 -c 'import venv'
python3 -m venv venv/
E então indo para a pasta /stable-diffusion-webui e executando:
rm -rf venv/
python3 -m venv venv/
Depois disso, funcionou para mim.
Indo mais fundo
- Leia sobre técnicas de solicitação, porque há muitas coisas para saber (por exemplo, solicitação positiva versus solicitação negativa, etapas de amostragem, método de amostragem, etc.)
- Guia do Promptbook OpenArt
- Guia definitivo de solicitação de SD
- Um guia sucinto de sugestões
- Dicas de solicitação do 4chan (NSFW)
- Coleção de prompts e imagens
- Guia passo a passo para estimular garotas de anime
- Leia sobre o conhecimento de SD em geral:
- Publicação seminal de difusão estável
- CompVis / Stability AI Github (casa dos modelos SD originais)
- Compêndio de difusão estável (bom recurso externo)
- Hub de links de difusão estável (recurso incrível do 4chan)
- Mina de ouro de difusão estável
- Mina de ouro SD simplificada
- Aleatório/Diversos. Ligações SD
- Perguntas frequentes (NSFW)
- Outra pergunta frequente
- Junte-se ao Discord de difusão estável
- Mantenha-se atualizado com as notícias da Difusão Estável
- Você sabia que a partir de março de 2023, um modelo de difusão de texto para vídeo com parâmetro de 1,7B está disponível?
- Mexa na WebUI, brinque com diferentes modelos, configurações, etc.
Solicitando
A ordem das palavras em um prompt tem um efeito: as palavras anteriores têm precedência. A estrutura geral de um bom prompt, daqui:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
E outro bom guia diz que o prompt deve seguir esta estrutura:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
Um artigo seminal sobre modelos txt2img de engenharia imediata, aqui. O recurso definitivo sobre sugestões de LLM, aqui.
O que quer que você solicite, tente seguir algum tipo de estrutura para que seu processo seja replicável. Abaixo estão os elementos de sintaxe de prompt necessários:
- () = modificador x1,05
- [] = /1,05 modificador
- (palavra:1,05) == (palavra)
- (palavra:1.1025) == ((palavra))
- (palavra: 0,952) == [palavra]
- (palavra: 0,907) == [[palavra]]
- A palavra-chave AND permite solicitar dois prompts separados ao mesmo tempo para mesclá-los; bom para que as coisas não se quebrem no espaço latente
- Por exemplo,
1girl standing on grass in front of castle AND castle in background
Modelo NovelAI
O modelo padrão é bastante elegante, mas, como costuma acontecer na história, o sexo impulsiona a maioria das coisas. NovelAI (NAI) era um serviço de geração de conteúdo SD focado em anime e seu modelo principal vazou. A maioria das imagens geradas em SD de homens e mulheres de anime que você vê (NSFW ou não) vêm deste modelo que vazou.
Em qualquer caso, é muito bom para gerar pessoas e a maioria dos modelos ou LoRAs com os quais você irá brincar são compatíveis com ele porque são treinados em imagens de anime. Além disso, os humanos apresentam um caso de uso inicial realmente bom para ajustar exatamente quais LoRAs você deseja usar para fins profissionais. Você solucionará muitos problemas e a maioria dos guias disponíveis são para imagens de mulheres. Posteriormente entraremos em codificadores automáticos variáveis (VAEs), o que traz verdadeiro realismo ao modelo.
- Siga o Guia NovelAI Speedrun
- Você precisará baixar o modelo vazado por Torrent ou encontrá-lo em outro lugar
- Depois de colocar os arquivos na pasta do WebUI,
stable-diffusion-webuimodelsStable-diffusion e selecionar o modelo lá, você deverá esperar alguns minutos enquanto a CLI carrega os pesos VAE- Se você tiver problemas aqui, copie o arquivo config.yaml da pasta onde estava o modelo e siga o mesmo esquema de nomenclatura (como neste guia)
- Isto é importante... Recrie a imagem Asuka exatamente, consultando o guia de solução de problemas se ela não corresponder
- Encontre novos modelos SD e LoRAs
- CivitAI
- Abraçando cara
- Modelos ODS
- Carga-mãe do modelo SDG (NSFW)
- Carga mãe ODS LoRA (NSFW)
- Muitos modelos populares (também o guia anterior) (NSFW)
LoRA
A adaptação de baixa classificação (LoRA) permite o ajuste fino para um determinado modelo. Mais informações sobre LoRAs aqui. Na WebUI, você pode adicionar LoRAs a um modelo como a cereja do bolo. Treinar novos LoRAs também é muito fácil. Existem outros meios “ancestrais” de ajuste fino (por exemplo, inversão textual e hiperredes), mas os LoRAs são o que há de mais moderno.
- Tanque ZTZ99A - tanque militar LoRA (um tanque específico)
- Jatos de combate - jato de combate LoRA
- epi_noiseoffset - LoRA que faz as imagens se destacarem, aumenta o contraste
Usarei o tanque LoRA ao longo do guia. Observe que este não é um LoRA muito bom, pois se destina a imagens no estilo anime, mas é bom para brincar.
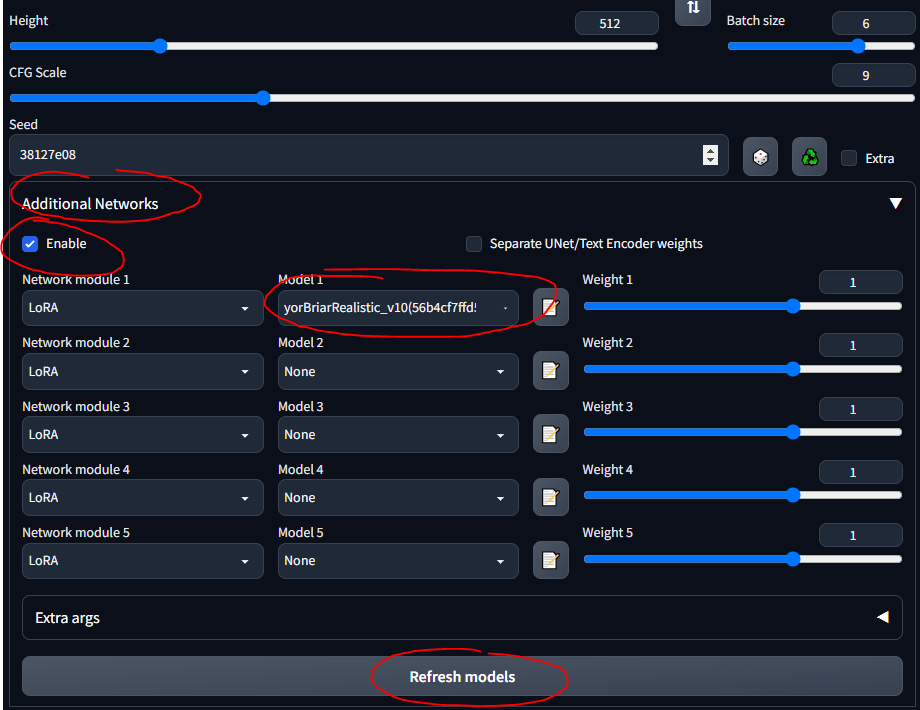
- Siga este guia rápido para instalar a extensão
- Agora você deve ver uma seção "Redes Adicionais" na IU
- Coloque seus LoRAs em
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora - Selecione e vá
- CERTIFIQUE-SE DE MARCAR 'ATIVAR'
- Saiba que qualquer LoRA que você baixar provavelmente terá informações que descrevem como usá-lo... como "use a palavra-chave tank" ou algo assim; certifique-se de que de onde você baixá-lo (por exemplo, CivitAI), você leia sua descrição
Brincando com modelos
Com base na seção anterior... modelos diferentes têm dados de treinamento e palavras-chave de treinamento diferentes... portanto, usar tags booru em alguns modelos não funciona muito bem. Abaixo estão alguns dos modelos com os quais brinquei e as “instruções” para eles.
Modelo SDG Motherload, utilizado para obter a maioria dos modelos, estou apenas resumindo as instruções aqui para referência rápida; a maioria dos modelos é para pornografia literal, concentrei-me nos realistas. Siga os links para ver exemplos de prompts, imagens e notas detalhadas sobre como usar cada um deles.
- Modelo SD padrão (1.5, desde a etapa de configuração; você pode brincar com as versões 2.x do SD, mas para ser franco, elas são uma droga)
- Modelo NovelAI (do primeiro guia)
- Qualquer coisa v3 - modelo de anime de uso geral
- Dreamshaper - realismo, para todos os fins
- Deliberado - realismo, fantasia, pinturas, cenários
- Neverending Dream - realismo, fantasia, bom para pessoas e animais
- Usa o sistema de tag booru
- Epic Diffusion - ultra-realismo, destinado a substituir o SD original
- AbyssOrangeMix (AOM) – anime, realismo, artístico, pinturas, extremamente comum e bom para testes
- Kotosmix - propósito geral, realismo, anime, cenário, pessoas, amostrador DPM++ 2M Karras recomendado
CivitAI foi usado para obter todos os outros. Você precisa criar uma conta , caso contrário não poderá ver o material NSFW, incluindo armas e equipamento militar. No CivitAI, alguns modelos (pontos de verificação) incluem VAEs; se estiver indicado, baixe-o também e coloque-o ao lado do modelo.
- ChilloutMix - ultra-realismo, retratos, um dos mais populares
- Protogen x3.4 - ultra-realismo
- Use palavras-gatilho: estilo modelshoot, estilo analógico, estilo mdjrny-v4, robô nousr
- Dreamlike Photoreal 2.0 - ultra-realismo
- Use a palavra-chave: fotorrealista
- Kit de ferramentas do SPYBG para artistas digitais - realismo, arte conceitual
- Use palavras-gatilho: tk-char, tk-env
VAEs
Os codificadores automáticos variáveis fazem com que as imagens pareçam melhores, mais nítidas e menos distorcidas. Alguns também consertam mãos e rostos. Mas é principalmente uma questão de saturação e sombreamento. Explicado aqui e aqui (NSFW). O NovelAI / Anything VAE é comumente usado. É basicamente um complemento ao seu modelo, assim como um LoRA.
Encontre VAEs na lista VAE:
- NAI / Qualquer coisa - para modelos de anime
- Vem com o modelo NAI por padrão quando você o coloca na pasta de modelos
- SD 1.5 – para modelos realistas
- Baixe um VAE
- Siga esta seção rápida do guia para configurar VAEs na WebUI
- Certifique-se de colocá-los em
stable-diffusion-webuimodelsVAE
- Experimente fazer imagens com e sem VAE, para ver as diferenças
Junte tudo
Aqui estão algumas notas gerais e coisas úteis que aprendi ao longo do caminho e que não se enquadram necessariamente no fluxo cronológico deste guia.
O Processo Geral de SD
Uma boa maneira de aprender é navegar por imagens legais no CivitAI, AIbooru ou outros sites SD (4chan, Reddit, etc.), abrir o que quiser e copiar os parâmetros de geração para a WebUI. Divulgação completa: nem sempre é possível recriar uma imagem com exatidão, conforme descrito aqui. Mas geralmente você pode chegar bem perto. Para realmente brincar, diminua o CFG para que o modelo possa ser mais criativo. Experimente os lotes e afaste-se do computador para voltar aos lotes para escolher.
O processo geral para um fluxo de trabalho WebUI é:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
- txt2img - solicita e obtém imagens
- img2img - edita imagens e gera outras semelhantes
- inpainting - edita partes de imagens (discutiremos mais tarde)
- extra - edições finais da imagem (discutiremos mais tarde)
Salvando prompts
Às vezes você deseja voltar aos prompts sem colar imagens ou escrevê-las do zero. Você pode salvar prompts para reutilizá-los na WebUI.
- Escreva um prompt positivo e/ou negativo
- No botão Gerar, clique no botão à direita para salvar seu "estilo"
- Digite um nome e salve
- Selecione-o a qualquer momento clicando no menu suspenso Estilos
Configurações do txt2img
Esta seção é mais ou menos um resumo das informações deste guia.
- Mais etapas de amostragem geralmente significam mais precisão (exceto para amostradores "a", como Euler a, que mudam de vez em quando)
- Brinque com isso ligado e desligado; geralmente, quando ativado, realmente faz os rostos parecerem bons
- Alta resolução. a correção é boa para imagens acima de 512x512; útil se houver mais de uma pessoa em uma imagem
- CFG é melhor em valores médios-baixos, como 5-10
Regenerando uma imagem gerada anteriormente
Trabalhar a partir de uma imagem gerada por SD que já existe; talvez alguém tenha enviado para você ou você queira recriar um que você fez:
- Na WebUI, vá para a guia Informações PNG
- Arraste e solte a imagem de seu interesse na IU
- Eles são salvos em
stable-diffusion-webuioutputstxt2img-images<date>
- Veja os parâmetros usados à direita
- Funciona porque PNGs podem armazenar metadados
- Você pode enviá-lo diretamente para a página txt2img com o botão correspondente
- Pode ser necessário verificar se o modelo, VAE e outros parâmetros são preenchidos automaticamente corretamente
Esteja ciente de que alguns sites removem metadados PNG quando as imagens são carregadas (por exemplo, 4chan), então procure URLs para as imagens completas ou use sites que retêm metadados SD, como CivitAI ou AIbooru.
Solução de erros
Recebi alguns erros de vez em quando. Principalmente erros de falta de memória (VRAM) que foram corrigidos reduzindo os valores de alguns parâmetros. Às vezes o Restaura enfrenta e Contrata. configurações de correção podem causar isso. No arquivo stable-diffusion-webuiwebui-user.bat , na linha set COMMANDLINE_ARGS= , você pode colocar alguns sinalizadores que corrigem erros comuns.
- Um erro NaN, algo como "um VAE produziu algo NaN", adicione o parâmetro
--disable-nan-check - Se você obtiver imagens pretas, adicione
--no-half - Se você continuar sem VRAM, adicione
--medvram ou para computadores de batata, --lowvram - Correção do Codeformer de restauração facial aqui (se quebrar, tente redefinir sua Internet primeiro)
- O carregamento lento do modelo (ao mudar para um novo) provavelmente ocorre porque os arquivos .safetensors carregam lentamente se as coisas não estiverem configuradas corretamente. Este tópico discute isso.
Um problema realmente comum é ter uma versão incorreta do Python ou do Torch. Você receberá erros como “não é possível instalar o Torch” ou “O Torch não consegue encontrar a GPU”. A solução mais simples é:
- Desinstale qualquer versão do Python que você atualizou, porque o SD WebUI espera 3.10.6 (usei 3.11.5 e ignorei o erro inicial, mas 3.10.6 parece funcionar melhor) (você também pode usar um gerenciador de versão se desejar estamos avançados o suficiente)
- Instale o Python 3.10.6, certificando-se de adicioná-lo ao seu PATH (sua pasta
Python e as pastas Python/Scripts ) - Exclua a pasta
venv em sua pasta stable-diffusion-webui - Execute
stable-diffusion-webuiwebui-user.bat e deixe-o reconstruir o venv corretamente - Aproveitar
Todos os argumentos da linha de comando podem ser encontrados aqui.
Ficando confortável
Algumas extensões podem melhorar o uso da WebUI. Obtenha o link do Github, vá para a guia Extensões, instale a partir do URL; opcionalmente, na guia Extensões, clique em Disponível e em Carregar de e você pode navegar pelas extensões localmente, isso reflete o wiki de extensões do Github.
- Tag Completer - recomenda e completa automaticamente tags booru conforme você digita
- Estado da IU da Web de difusão estável - preserva o estado da IU mesmo após a reinicialização
- Test My Prompt - um script que você pode executar para remover palavras individuais do seu prompt e ver como isso afeta a geração de imagens
- Model-Keyword - preenche automaticamente palavras-chave associadas a alguns modelos e LoRAs, bastante bem conservadas e atualizadas em abril de 2023
- Verificador NSFW - oculta imagens NSFW; útil se você estiver trabalhando em um escritório, pois muitos modelos bons permitem conteúdo NSFW e você pode não querer ver isso no trabalho
- ESTEJA ATENTO: esta extensão pode atrapalhar a pintura ou até mesmo a geração ao escurecer imagens NSFW (não temporariamente, ela literalmente exibe uma imagem preta), então certifique-se de desligá-la conforme necessário
- Prompt Gelbooru - extrai tags e cria um prompt automático de qualquer imagem Gelbooru usando seu hash
- booru2prompt - semelhante ao Gelbooru Prompt, mas com um pouco mais de funcionalidade
- Prompt Dinâmico - uma linguagem de modelo para geração de prompts que permite executar prompts aleatórios ou combinatórios para gerar várias imagens (usa curingas)
- Descrito um pouco mais aqui
- Kit de ferramentas de modelo – extensão popular que ajuda você a gerenciar, editar e criar modelos
- Conversor de Modelos - útil para converter modelos, alterar precisões, etc., quando você está treinando seus próprios
Teste
Então agora você tem alguns modelos, LoRAs e prompts... como você pode testar para ver o que funciona melhor? Abaixo do painel Redes Adicionais, há o menu suspenso Script. Aqui, clique em gráfico X/Y/Z. No tipo X, selecione Nome do Checkpoint; nos valores X, clique no botão à direita para colar todos os seus modelos. No tipo Y, experimente VAE, ou talvez semente, ou escala CFG. Qualquer que seja o atributo escolhido, cole (ou insira) os valores que deseja representar graficamente. Por exemplo, se você tiver 5 modelos e 5 VAEs, você fará uma grade de 25 imagens, comparando a saída de cada modelo com cada VAE. Isso é muito versátil e pode ajudá-lo a decidir o que usar. Apenas tome cuidado, pois se seus eixos X ou Y forem modelos de VAEs, será necessário carregar o modelo ou pesos VAE para cada combinação, por isso pode demorar um pouco.
Um recurso realmente bom sobre comparações de SD pode ser encontrado aqui (NSFW). Existem muitos links para seguir. Você pode começar a entender como os vários modelos, VAEs, LoRAs, valores de parâmetros e assim por diante afetam a geração de imagens.
Adotei um prompt de teste daqui e usei o tanque LoRA para fazer essa grade X/Y. Você pode ver como os vários modelos e amostradores funcionam uns com os outros. A partir deste teste, podemos avaliar que:
- Os modelos ChilloutMix, Deliber, Dreamlike Photoreal e Epic Diffusion parecem produzir as imagens de tanques mais "realistas"
- Em testes independentes posteriores, descobriu-se que o Protogen X34 Photorealism e o SpyBGs Toolkit também eram muito bons em tanques.
- Os amostradores mais promissores aqui parecem ser o DPM++ SDE ou qualquer um dos amostradores Karras.

Os parâmetros exatos usados (sem incluir o modelo ou amostrador) para cada uma dessas imagens de tanque são fornecidos abaixo (novamente, retirados daqui):
- Alerta positivo: tanque, bf2042, melhor qualidade, obra-prima, resolução ultra alta, (fotorrealista: 1,4), pele detalhada, iluminação cinematográfica, fotografia cinematográfica altamente detalhada, colorida, moderna, um grupo de soldados no campo de batalha, explosão no campo de batalha em todos os lugares, caças a jato e helicópteros voando no céu, dois tanques no chão, em área deserta, prédios em chamas e um veículo blindado militar abandonado ao fundo
- Prompt negativo: nu, (pior qualidade: 2), (qualidade baixa: 2), (qualidade normal: 2), resolução baixa, anatomia ruim, mãos ruins, qualidade normal, ((monocromático)), ((escala de cinza)), recolhido sombra, múltiplas sobrancelhas, cabelo rosa, buracos nos seios, ng_deepnegative_v1_75t, nsfw, mamilos, dedos extras, ((braços extras)), (pernas extras), mãos mutantes, (fundidas dedos), (muitos dedos), (pescoço longo: 1,3)
- Etapas: 22
- Escala CFG: 7,5
- Semente: 1656460887
- Tamanho: 480x480
- Pular clipe: 2
- AddNet habilitado: Verdadeiro, Módulo AddNet 1: LoRA, AddNet Modelo 1: ztz99ATank_ztz99ATank (82a1a1085b2b), Peso AddNet A 1: 1, Peso AddNet B 1: 1
WebUI Avançado
Nesta seção estão as coisas mais avançadas que você pode fazer depois de obter uma boa familiaridade com o uso de modelos, LoRAs, VAEs, prompts, parâmetros, scripts e extensões na guia txt2image da WebUI.
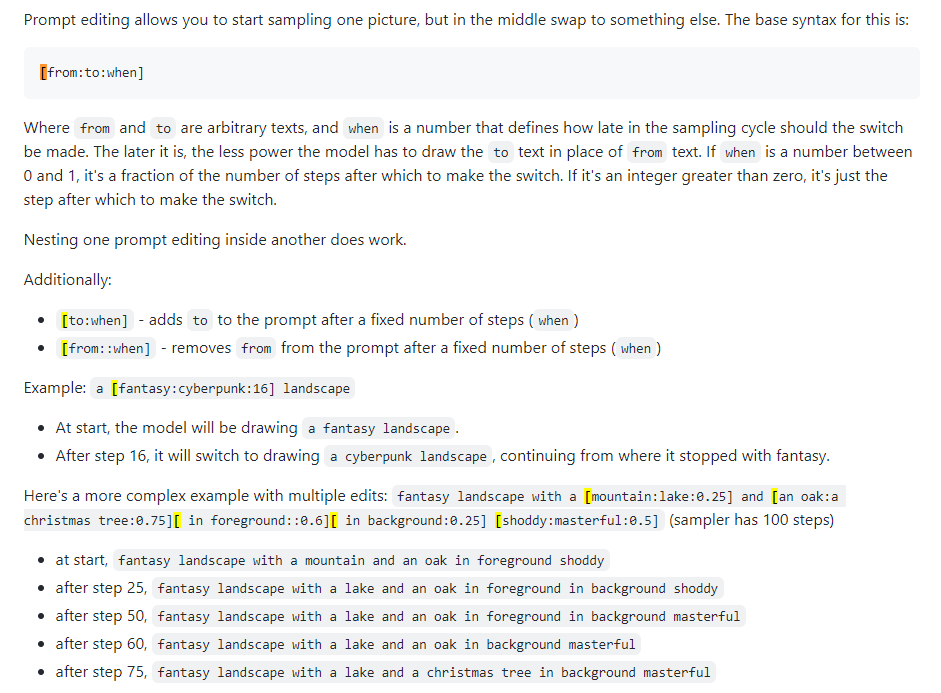
Edição imediata
Também conhecido como mistura imediata. A edição de prompt permite que o modelo altere seu prompt em etapas especificadas. A imagem abaixo foi tirada de uma postagem do 4chan e descreve a técnica. Por exemplo, conforme indicado neste guia, a edição imediata pode ser usada para mesclar faces.
Xformers
Xformers, ou camadas de atenção cruzada. Uma forma de acelerar a geração de imagens (medida em segundos/iteração ou s/it) em GPUs Nvidia reduz o uso de VRAM, mas causa não determinismo. Considere isso apenas se você tiver uma GPU poderosa; realisticamente, você precisa de um Quadro.
img2img
Não é exatamente muito usado, é uma aba meio confusa. Pode ser usado para gerar imagens a partir de esboços, como no Huggingface Image to Image SD Playground. Esta aba possui uma subaba, inpainting, que é o assunto da próxima seção e um recurso muito importante da WebUI. Embora você possa usar esta seção para gerar imagens alteradas, considerando uma que você já criou (saída para stable-diffusion-webuioutputsimg2img-images ), a funcionalidade é irregular para mim... parece usar uma quantidade absurda de memória e Mal consigo fazê-lo funcionar. Vá para a próxima seção abaixo.
Pintura
É aqui que reside o poder para o criador do conteúdo ou alguém interessado na perturbação da imagem. A saída está em stable-diffusion-webuioutputsimg2img-images .
- Guia de pintura interna e externa
- Pintura interna 4chan (NSFW)
- Guia definitivo de pintura
- Pegue uma imagem que você goste, mas que não seja perfeita, algo está errado - ela precisa ser ajustada
- Ou gere um e clique em Enviar para inpaint (todas as configurações serão preenchidas automaticamente)
- Você está agora na subguia img2img -> inpaint
- Desenhe (com o mouse) na imagem o local exato que deseja alterar
- Defina o modo de máscara como "inpaint mascarado", o conteúdo mascarado como "original" e a área de pintura como "apenas mascarado"
- Na área de prompt acima, escreva o novo prompt para ajustar aquele ponto na imagem; faça um prompt negativo se desejar
- Gere uma imagem (idealmente, faça um lote de 4 ou mais)
- Qualquer que você quiser, clique em Enviar para pintar e itere até ter uma imagem finalizada
Pintura superior
Outpainting é um processo semântico bastante complexo. Outpainting permite que você pegue uma imagem e a expanda quantas vezes quiser, essencialmente aumentando suas bordas. O processo é descrito aqui. Você expande a imagem apenas 64 pixels por vez. Existem duas ferramentas de UI para isso (que pude encontrar):
- Alpha Canvas (integrado ao WebUI como uma extensão/script)
- Hua (aplicativo web para pintura interna/pintura externa)
Extras
Esta guia WebUI é especificamente para upscaling. Se você obtiver uma imagem que realmente goste, poderá aprimorá-la aqui, no final do seu fluxo de trabalho. Imagens ampliadas são armazenadas em stable-diffusion-webuioutputsextras-images . Alguns dos problemas de memória associados ao upscaling com upscalers mais poderosos durante a geração na aba txt2img (por exemplo, os 4x+) não acontecem aqui porque você não está gerando novas imagens, você está apenas upscaling as estáticas.
Redes de controle
A melhor maneira de entender o que um ControlNet faz é dizer “pintura com esteróides”. Você fornece uma imagem de entrada (gerada por SD ou não) e ela pode modificar tudo. Também são possíveis poses com ControlNets. Você pode fornecer uma pose de referência para uma pessoa e gerar imagens correspondentes de acordo com sua solicitação típica. Um bom começo para entender ControlNets está aqui.
- Instale a extensão ControlNet, sd-webui-controlnet na WebUI
- Certifique-se de recarregar a IU clicando no botão Recarregar IU na guia de configurações
- Verifique se o botão ControlNet agora está na aba txt2img (e img2img), abaixo de Redes Adicionais (onde você coloca seus LoRAs)
- Ative vários modelos ControlNet: Configurações -> ControlNet -> controle deslizante Mutli ControlNet -> 2+
- Recarregue a UI e na área ControlNet você deverá ver várias guias de modelo
- Você pode combinar ControlNets (por exemplo, Canny e OpenPose) da mesma forma que usar vários LoRAs
- Obtenha um modelo ControlNet
- Os modelos Canny são modelos de detecção de bordas; as imagens são convertidas em imagens de borda em preto e branco, onde as bordas informam ao SD, aproximadamente, como será a aparência da sua imagem
- Os modelos OpenPose pegam a imagem de uma pessoa e a convertem em um modelo de pose para usar em imagens posteriores
- Existem muitos outros modelos que também podem ser investigados lá
- Vamos pegar os modelos Canny e OpenPose
- Coloque-os em
stable-diffusion-webuiextensionssd-webui-controlnetmodels - Obtenha qualquer imagem de seu interesse ou gere uma nova; aqui, usarei esta imagem de tanque que gerei anteriormente

- Configurações em txt2img: método de amostragem "DDIM", etapas de amostragem 20, largura/altura iguais à imagem selecionada
- Configurações na aba ControlNet: marque Enable, Pré-processador "Canny", Modelo "control_canny-fp16", largura/altura da tela igual à imagem selecionada (todas as outras configurações são padrão)
- Modifique seus prompts e clique em gerar; Tentei converter a imagem do meu tanque em uma de Marte

- A sugestão positiva foi: uma cena em Marte, espaço sideral, espaço, universo, ((fundo do espaço da galáxia)), estrelas, base lunar, futurista, fundo preto, fundo escuro, estrelas no céu, (noite) areia vermelha, ((estrelas em o plano de fundo)), tanque, bf2042, melhor qualidade, obra-prima, resolução ultra alta, (fotorrealista: 1.4), skin detalhada, iluminação cinematográfica, fotografia cinematográfica altamente detalhada, colorida, moderna, um grupo de soldados no campo de batalha, explosão no campo de batalha em todos os lugares, caças e helicópteros voando no céu, dois tanques no chão, na área deserta, edifícios em chamas e um veículo blindado militar abandonado ao fundo, árvore, floresta, céu
- Pegue uma imagem com pessoas nela e você pode fazer o modelo Canny no Control Model - 0 e o modelo OpenPose no Control Model - 1 para realmente se divertir com isso
- Mais uma vez, assista a este vídeo para realmente se aprofundar no Canny e no OpenPose
Fazendo coisas novas
Tudo isso é muito bom, mas às vezes você precisa de modelos melhores ou LoRAs para casos de uso profissionais. Como a maior parte do conteúdo SD se destina literalmente à geração de mulheres ou pornografia, modelos específicos e LoRAs podem precisar ser treinados.
- Navegue por todos os tópicos de interesse aqui
- Treinamento de LoRAs
- Trem LoRA
- Guia de treinamento preguiçoso LoRA
- Um bom guia de treinamento LoRA da CivitAI
- Outro guia de treinamento LoRA
- Informações mais gerais sobre LoRA
- Mesclando modelos
- Misturando modelos
Treinando Novos Modelos
Veja a seção sobre DreamBooth.
Fusão de ponto de verificação
PENDÊNCIA
A guia de fusão de pontos de verificação na WebUI permite combinar dois modelos, como misturar dois molhos em uma panela, onde a saída é um novo molho que é uma combinação de ambos.
Treinamento de LoRAs
PENDÊNCIA
Treinar um LoRA não é necessariamente difícil, é apenas uma questão de reunir dados suficientes.
Configuração do Google Colab
Este é um passo importante se você tiver que trabalhar fora do equipamento. O Google Colab Pro custa 10 dólares por mês e oferece 89 GB de RAM e acesso a boas GPUs, para que você possa tecnicamente executar prompts em seu telefone e fazer com que funcionem para você em um servidor em Timbuktu. Se você não se importa com um custo extra, o Google Colab Pro + custa 50 dólares por mês e é ainda melhor.
- Vá para este SD Colab pré-construído
- Você pode cloná-lo no seu GDrive ou simplesmente usá-lo como está, para que esteja sempre o mais atualizado no Github
- Execute os primeiros 4 blocos de código (demora um pouco)
- Ignore o bloco de código ControlNet
- Execute 'Start Stable-Diffusion' (demora um pouco)
- Coloque nome de usuário/senha se quiser (provavelmente uma boa ideia já que o Gradio é público)
- Clique no link Gradio ('executando em URL público')
- Use a WebUI normalmente
- Envie o link para o seu telefone e você poderá gerar imagens em qualquer lugar
- Para adicionar novos modelos e LoRAs, você deve ter novas pastas em seu Google Drive:
gdrive/MyDrive/sd/stable-diffusion-webui , e a partir desta pasta base você pode usar a mesma estrutura de pastas que está fazendo no local UI da Web- Faça a instalação da extensão LoRA como anteriormente e a estrutura de pastas será preenchida automaticamente como na área de trabalho
- Agora, toda vez que você quiser usá-lo, basta executar o bloco de código 'Start Stable-Diffusion' (nenhuma das outras coisas), obter um link gradio e pronto
O Google Colab é sempre gratuito e você pode usá-lo para sempre, mas pode ser um pouco lento. Atualizar para o Colab Pro por US$ 10/mês oferece mais poder. Mas o Colab Pro+ por US$ 50/mês é onde realmente está a diversão. Pro+ permite executar seu código por 24 horas, mesmo depois de fechar a guia.
TODO Recebo um erro estranho que interrompe minha assinatura Pro quando defino meu tempo de execução -> configurações de notebook do tipo tempo de execução para classe GPU Premium e alta RAM. É porque o xFormers não foi desenvolvido com suporte CUDA. Isso poderia ser resolvido usando TPUs ou desativando xFormers, mas não tenho paciência para isso no momento. Experimente os problemas do Colab.
Meio da jornada
MJ é muito bom para artistas. Não é NEM tão extensível ou poderoso quanto o SD na WebUI (NSFW é impossível), mas você pode gerar algumas coisas incríveis. Você pode usá-lo gratuitamente no MJ Discord (inscreva-se no site deles) por algumas solicitações ou pagar US$ 8/mês pelo plano básico, após o que você pode usá-lo em seu próprio servidor privado. Todos os comandos do Discord podem ser encontrados aqui e aqui. A estrutura do prompt para MJ é:
/imagine <optional image prompt> <prompt> --parameters
Parâmetros MJ
Estes são para MJ V4, basicamente os mesmos para MJ 5. Todos os modelos são descritos aqui.
- --ar 1.2-2.1: proporção de aspecto, o padrão é 1:1
- --chaos 0-100: variação em, o padrão é 0
- --sem plantas: remove plantas
- --q 0,0-2,0: tempo de qualidade de renderização, o padrão é 1
- --semente: a semente
- --stop 10-100: interrompe o trabalho no meio para gerar uma imagem mais desfocada
- --style 4a/4b/4c: estilo de MJ 4'
- --stylize 0-1000: quão fortemente a estética de MJ é livre, o padrão é 100
- --uplight: use um upscaler "leve", a imagem é menos detalhada
- --upbeta: use um upscaler beta, mais próximo da imagem original
- --upanime: upscaler para imagens de anime
- --niji: modelo alternativo para imagens de anime
- --hd: use um modelo anterior que produz imagens maiores, bom para resumos e paisagens
- --test: use o modelo de teste especial MJ
- --Testp: Use o modelo de teste focado na fotografia de MJ especial
- -Tile: apenas para MJ 5, gera uma imagem repetida
- Verificador de imagem Tilable
- --v 1/2/3/4/5: qual versão MJ usar (5 é o melhor)
MJ Prompts avançados
- Você pode injetar uma imagem (ou imagens) no início de um aviso para influenciar seu estilo e cores. Veja este doc. Carregue uma imagem no seu servidor Discord e clique com o botão direito do mouse para obter o link.
- A remixagem permite fazer variações de uma imagem, alterando modelos, assuntos ou médios. Veja este doc.
- Multi Prots Permite MJ considerar dois ou mais conceitos separados individualmente. MJ Versões 1-4 e Niji Somente. Por exemplo, "cachorro -quente" fará imagens da comida, "Hot :: Dog" fará imagens de um canino quente. Você também pode adicionar pesos aos avisos; Por exemplo, "Hot :: 2 Dog" fará imagens de cães pegando fogo. MJ 1/2/3 aceita pesos inteiros, o MJ 4 pode aceitar decimais. Veja este doc.
- A mistura permite fazer upload de 2-5 imagens para mesclá-las em uma nova imagem. O comando /Blend é descrito aqui.
Dreamstudio
PENDÊNCIA
O DreamStudio (não Dreambooth) é a plataforma principal da empresa de IA de estabilidade. O site deles é uma plataforma, o Dreambooth Studio, do qual você pode gerar imagens. Ele meio que repousa entre o Midjourney e o Webui em termos de funcionalidade aberta. O Dreambooth Studio parece ter sido construído no topo da plataforma Invoke.ai, que você pode instalar e executar localmente como o Webui.
Horda estável
PENDÊNCIA
A Horda estável é um esforço da comunidade para libertar a difusão estável para todos. Funciona essencialmente como torrenting ou hash de bitcoin, onde todos contribuem com parte de seu poder de GPU para gerar conteúdo de SD. O aplicativo Horde pode ser acessado aqui.
Dreambooth
PENDÊNCIA
O Dreambooth (não o DreamStudio) foi a implementação do Google de uma técnica de ajuste fino do modelo de difusão estável. Em resumo: você pode usá -lo para treinar modelos com suas próprias fotos. Você pode usá -lo diretamente daqui ou aqui. É mais complexo do que apenas baixar modelos e clicar no webui, pois você está trabalhando para realmente treinar e serializar um novo modelo. Alguns vídeos resumem como fazer isso:
- Tutorial fácil do Dreambooth
- Treinamento de 10 minutos de Dreambooth
- Extensão Webui Dreambooth
E alguns bons guias:
- Reddit Advanced Dreambooth Conselho
- Simples Dreambooth
- Dreambooth Dump (muitas informações, role através de links)
Um colab do Google para Dreambooth:
- THELASTBEN DREAMBOOTH TREINAMENTO COLAB (o mesmo autor que o SD Colab descrito no Google Colab Setup)
Há também um treinador de modelo chamado EveryDream. Uma comparação completa entre Dreambooth e EveryDream pode ser encontrada aqui.
Difusão de vídeo
PENDÊNCIA
É possível a partir de março de 2023 usar difusão estável para gerar vídeos. Atualmente (abril de 2023), a funcionalidade é bastante simplista, pois os vídeos são gerados a partir de imagens semelhantes, quadro a quadro, dando a vídeos uma espécie de visual "flipbook". Existem duas extensões principais para o webui que você pode usar:
- Animador - mais fácil
- DeForum - mais funcionalidade
Ferro-velho
Coisas que eu não conheço muito, mas preciso olhar para
Há um processo que você pode seguir para obter bons resultados repetidamente ... isso será refinado ao longo do tempo.
- PENDÊNCIA
- Highres Fix, aqui
- Upscaling, por toda parte, mas aqui principalmente
Integração ChatGpt?
pintura externa
Dall-e 2
DeForum https://deforum.github.io/


