thumb
1.0.0
Uma biblioteca simples de testes rápidos para LLMs.
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])Cada prompt é executado 10 vezes de forma assíncrona por padrão, o que é cerca de 9x mais rápido do que executá-los sequencialmente. Nos Jupyter Notebooks, uma interface de usuário simples é exibida para respostas de classificação cega (você não vê qual prompt gerou a resposta).
Depois que todas as respostas forem avaliadas, as seguintes estatísticas de desempenho serão calculadas, divididas por modelo de prompt:
avg_score quantidade de feedback positivo como uma porcentagem de todas as execuçõesavg_tokens : quantos tokens foram usados no prompt e na respostaavg_cost : uma estimativa de quanto custou em média a execução do prompt Um relatório simples é exibido no notebook e os dados completos são salvos em um arquivo CSV thumb/ThumbTest-{TestID}.csv .

Os casos de teste ocorrem quando você deseja testar um modelo de prompt com diferentes variáveis de entrada. Por exemplo, se desejar testar um modelo de prompt que inclua uma variável para o nome de um comediante, você poderá configurar casos de teste para diferentes comediantes.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Cada caso de teste será executado em cada modelo de prompt, portanto, neste exemplo, você obterá 6 combinações (3 casos de teste x 2 modelos de prompt), cada uma executada 10 vezes (60 chamadas no total para OpenAI). Cada caso de teste deve incluir um valor para cada variável no modelo de prompt.
Os prompts podem ter diversas variáveis em cada caso de teste. Por exemplo, se desejar testar um modelo de prompt que inclua uma variável para o nome de um comediante e um tópico de piada, você poderá configurar casos de teste para diferentes comediantes e tópicos.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Cada caso é testado em cada prompt, a fim de obter uma comparação justa do desempenho de cada prompt com os mesmos dados de entrada. Com 4 casos de teste e 2 prompts, você obterá 8 combinações (4 casos de teste x 2 modelos de prompt), cada uma executada 10 vezes (80 chamadas no total para OpenAI).
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])Isso executará cada prompt em cada modelo, a fim de obter uma comparação justa do desempenho de cada prompt com os mesmos dados de entrada. Com 2 prompts e 2 modelos, você obterá 4 combinações (2 prompts x 2 modelos), cada uma executada 10 vezes (40 chamadas no total para OpenAI).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases ) Os prompts podem ser uma string ou uma matriz de strings. Se o prompt for uma matriz, a primeira string será usada como uma mensagem do sistema e o restante dos prompts alternará entre mensagens Humanas e Assistentes ( [system, human, ai, human, ai, ...] ). Isso é útil para testar prompts que incluem uma mensagem do sistema ou que usam pré-aquecimento (inserção de mensagens anteriores no chat para orientar a IA em direção ao comportamento desejado).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
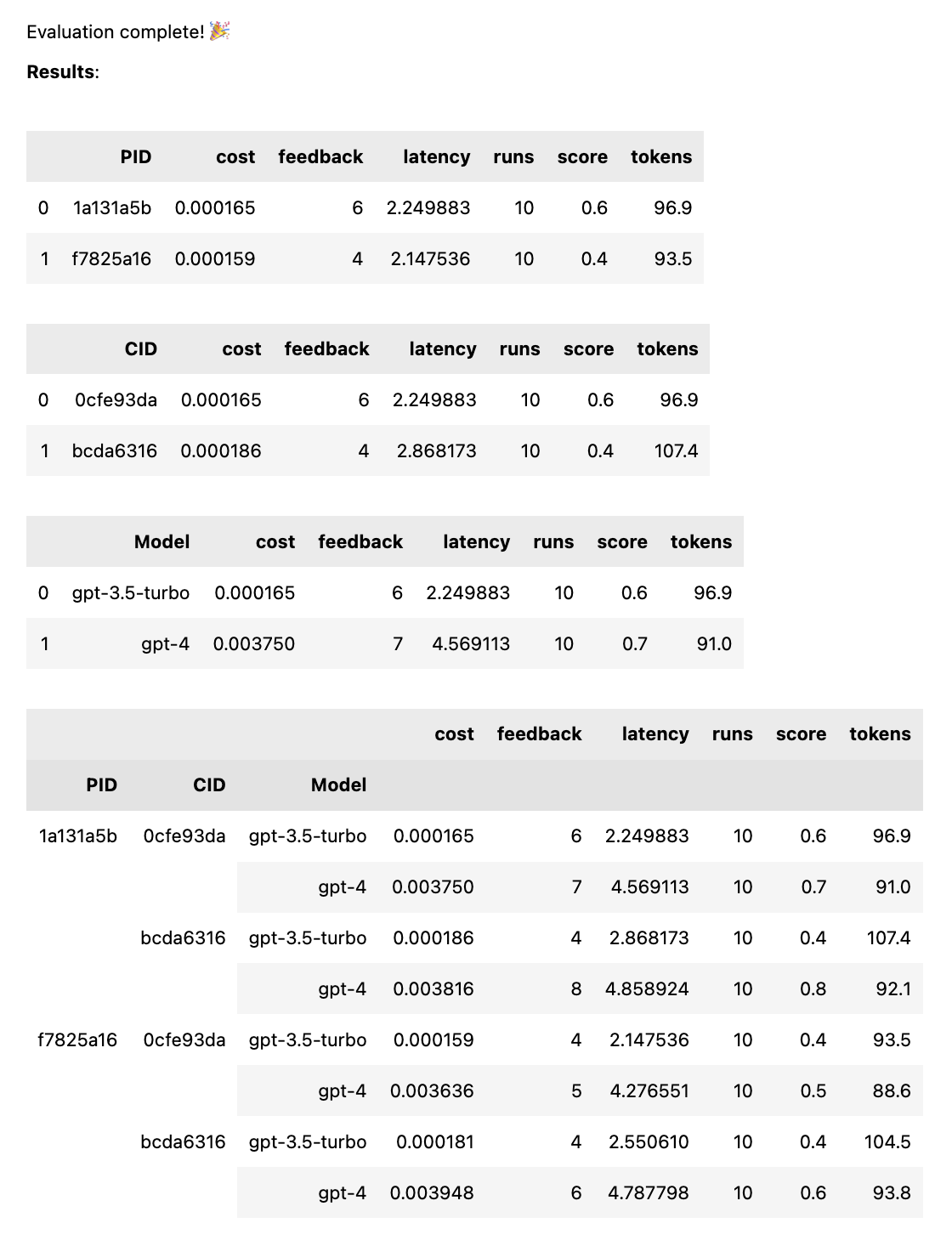
test = thumb . test ([ prompt_a , prompt_b ], cases )Quando o teste for concluído, você receberá um relatório de avaliação completo, dividido por PID, CID e modelo, bem como um relatório geral dividido por todas as combinações. Se você testar apenas um modelo ou um caso, essas falhas serão eliminadas. O relatório mostra uma chave na parte inferior para ver qual ID corresponde a qual prompt ou caso.
A função thumb.test usa os seguintes parâmetros:
None )10 )gpt-3.5-turbo ])True ) Se você tiver 10 execuções de teste com 2 modelos de prompt e 3 casos de teste, serão 10 x 2 x 3 = 60 chamadas para OpenAI. Tenha cuidado: especialmente com o GPT-4 os custos podem aumentar rapidamente!
O rastreamento Langchain para LangSmith é ativado automaticamente se LANGCHAIN_API_KEY for definido como uma variável de ambiente (opcional).
a função .test() retorna um objeto ThumbTest . Você pode adicionar mais prompts ou casos ao teste ou executá-lo mais vezes. Você também pode gerar, avaliar e exportar os dados de teste a qualquer momento.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Cada modelo de prompt obtém os mesmos dados de entrada de cada caso de teste, mas o prompt não precisa usar todas as variáveis do caso de teste. Como no exemplo acima, o prompt tell me a knock knock joke não usa a variável subject , mas ainda é gerado uma vez (sem variáveis) para cada caso de teste.
Os dados de teste são armazenados em cache em um arquivo JSON local thumb/.cache/{TestID}.json depois que cada conjunto de execuções é gerado para uma combinação de prompt e caso. Se o seu teste for interrompido ou você quiser adicioná-lo, você pode usar a função thumb.load para carregar os dados de teste do cache.
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Cada execução para cada combinação de prompt e caso é armazenada no objeto (e no cache) e, portanto, chamar test.generate() novamente não gerará nenhuma nova resposta se mais prompts, casos ou execuções não forem adicionados. Da mesma forma, chamar test.evaluate() novamente não reavaliará as respostas que você já avaliou e simplesmente exibirá novamente os resultados se o teste terminar.
A diferença entre as pessoas que apenas brincam com o ChatGPT e aquelas que usam IA na produção é a avaliação. Os LLMs respondem de forma não determinística e, por isso, é importante testar como são os resultados quando ampliados em uma ampla variedade de cenários. Sem uma estrutura de avaliação, você fica adivinhando cegamente o que está funcionando em seus prompts (ou não).
Engenheiros sérios e imediatos estão testando e aprendendo quais entradas levam a resultados úteis ou desejados, de maneira confiável e em escala. Esse processo é chamado de otimização imediata e tem a seguinte aparência:
O teste do polegar preenche a lacuna entre os mecanismos de avaliação profissional em grande escala e a solicitação cega por tentativa e erro. Se você estiver fazendo a transição de um prompt para um ambiente de produção, usar thumb para testar seu prompt pode ajudá-lo a detectar casos extremos e obter feedback antecipado do usuário ou da equipe sobre os resultados.
Essas pessoas estão construindo thumb para se divertir em seu tempo livre. ?
martelo-mt |


