Machine Learning Guide
1.0.0
Nota: Você pode converter facilmente este arquivo markdown em PDF no VSCode usando esta útil extensão Markdown PDF.

Estruturas de aprendizado de máquina/aprendizado profundo.
Recursos de aprendizagem para ML
Estruturas, bibliotecas e ferramentas de ML
Algoritmos
Desenvolvimento PyTorch
Desenvolvimento TensorFlow
Desenvolvimento central de ML
Desenvolvimento de aprendizagem profunda
Desenvolvimento de aprendizagem por reforço
Desenvolvimento de Visão Computacional
Desenvolvimento de Processamento de Linguagem Natural (PNL)
Bioinformática
Desenvolvimento CUDA
Desenvolvimento MATLAB
Desenvolvimento C/C++
Desenvolvimento Java
Desenvolvimento Python
Desenvolvimento Scala
Desenvolvimento R
Júlia Desenvolvimento
Voltar ao topo
Machine Learning é um ramo da inteligência artificial (IA) focado na construção de aplicativos usando algoritmos que aprendem com modelos de dados e melhoram sua precisão ao longo do tempo, sem a necessidade de programação.

Voltar ao topo
Práticas recomendadas de processamento de linguagem natural (PNL) da Microsoft
O livro de receitas de direção autônoma da Microsoft
Azure Machine Learning – ML como serviço | Microsoft Azure
Como executar Jupyter Notebooks em seu espaço de trabalho do Azure Machine Learning
Aprendizado de Máquina e Inteligência Artificial | Amazon Web Services
Agendamento de notebooks Jupyter em instâncias efêmeras do Amazon SageMaker
IA e aprendizado de máquina | Google Nuvem
Usando notebooks Jupyter com Apache Spark no Google Cloud
Aprendizado de máquina | Desenvolvedor Apple
Inteligência Artificial e Piloto Automático | Tesla
Ferramentas Meta AI | Facebook
Tutoriais PyTorch
Tutoriais do TensorFlow
Laboratório Jupyter
Difusão estável com Core ML em Apple Silicon
Voltar ao topo
Aprendizado de máquina pela Universidade de Stanford por Andrew Ng | Curso
Treinamento e certificação da AWS para cursos de aprendizado de máquina (ML)
Programa de bolsas de aprendizado de máquina para Microsoft Azure | Udacidade
Certificado pela Microsoft: Azure Data Scientist Associate
Certificado pela Microsoft: Engenheiro Associado de IA do Azure
Treinamento e implantação do Azure Machine Learning
Aprendendo aprendizado de máquina e inteligência artificial com o treinamento do Google Cloud
Curso intensivo de aprendizado de máquina para Google Cloud
Cursos de aprendizado de máquina on-line | Udemy
Cursos de aprendizado de máquina on-line | Curso
Aprenda aprendizado de máquina com cursos e aulas online | edX
Voltar ao topo
Introdução ao aprendizado de máquina (PDF)
Inteligência Artificial: Uma Abordagem Moderna por Stuart J. Russel e Peter Norvig
Aprendizado profundo por Ian Goodfellow, Yoshoua Bengio e Aaron Courville
O livro de aprendizado de máquina de cem páginas, de Andriy Burkov
Aprendizado de máquina por Tom M. Mitchell
Programando Inteligência Coletiva: Construindo Aplicativos Smart Web 2.0 por Toby Segaran
Aprendizado de máquina: uma perspectiva algorítmica, segunda edição
Reconhecimento de padrões e aprendizado de máquina por Christopher M. Bishop
Processamento de linguagem natural com Python por Steven Bird, Ewan Klein e Edward Loper
Aprendizado de máquina Python: uma abordagem técnica de aprendizado de máquina para iniciantes, por Leonard Eddison
Raciocínio bayesiano e aprendizado de máquina por David Barber
Aprendizado de máquina para iniciantes: uma introdução em inglês simples, por Oliver Theobald
Aprendizado de máquina em ação por Ben Wilson
Aprendizado de máquina prático com Scikit-Learn, Keras e TensorFlow: conceitos, ferramentas e técnicas para construir sistemas inteligentes por Aurélien Géron
Introdução ao aprendizado de máquina com Python: um guia para cientistas de dados por Andreas C. Müller e Sarah Guido
Aprendizado de máquina para hackers: estudos de caso e algoritmos para você começar, por Drew Conway e John Myles White
Os elementos da aprendizagem estatística: mineração de dados, inferência e previsão por Trevor Hastie, Robert Tibshirani e Jerome Friedman
Padrões distribuídos de aprendizado de máquina - livro (livre para leitura online) + código
Aprendizado de máquina do mundo real [capítulos gratuitos]
Uma introdução à aprendizagem estatística - Livro + Código R
Elementos de Aprendizagem Estatística - Livro
Think Bayes - Livro + Código Python
Mineração de conjuntos de dados massivos
Um primeiro encontro com aprendizado de máquina
Introdução ao aprendizado de máquina - Alex Smola e SVN Vishwanathan
Uma teoria probabilística de reconhecimento de padrões
Introdução à recuperação de informações
Previsão: princípios e prática
Introdução ao aprendizado de máquina - Amnon Shashua
Aprendizagem por Reforço
Aprendizado de máquina
Uma busca pela IA
Programação R para Ciência de Dados
Mineração de dados - ferramentas e técnicas práticas de aprendizado de máquina
Aprendizado de máquina com TensorFlow
Sistemas de aprendizado de máquina
Fundamentos do aprendizado de máquina - Mehryar Mohri, Afshin Rostamizadeh e Ameet Talwalkar
Pesquisa baseada em IA - Trey Grainger, Doug Turnbull, Max Irwin -
Métodos Ensemble para Aprendizado de Máquina - Gautam Kunapuli
Engenharia de aprendizado de máquina em ação - Ben Wilson
Aprendizado de máquina que preserva a privacidade - J. Morris Chang, Di Zhuang, G. Dumindu Samaraweera
Aprendizado de máquina automatizado em ação - Qingquan Song, Haifeng Jin e Xia Hu
Padrões Distribuídos de Aprendizado de Máquina - Yuan Tang
Gerenciando projetos de aprendizado de máquina: do design à implantação - Simon Thompson
Aprendizado de máquina causal - Robert Ness
Otimização Bayesiana em Ação - Quan Nguyen
Algoritmos de aprendizado de máquina em profundidade) - Vadim Smolyakov
Algoritmos de Otimização - Alaa Khamis
Aumento prático de gradiente por Guillaume Saupin
Voltar ao topo
Voltar ao topo
TensorFlow é uma plataforma de código aberto ponta a ponta para aprendizado de máquina. Possui um ecossistema abrangente e flexível de ferramentas, bibliotecas e recursos da comunidade que permite aos pesquisadores impulsionar o que há de mais moderno em ML e aos desenvolvedores criar e implantar facilmente aplicativos baseados em ML.
Keras é uma API de redes neurais de alto nível, escrita em Python e capaz de ser executada em TensorFlow, CNTK ou Theano. Foi desenvolvida com foco em permitir experimentação rápida. Ele é capaz de ser executado em TensorFlow, Microsoft Cognitive Toolkit, R, Theano ou PlaidML.
PyTorch é uma biblioteca para aprendizado profundo em dados de entrada irregulares, como gráficos, nuvens de pontos e variedades. Desenvolvido principalmente pelo laboratório de pesquisa de IA do Facebook.
O Amazon SageMaker é um serviço totalmente gerenciado que oferece a todos os desenvolvedores e cientistas de dados a capacidade de criar, treinar e implantar modelos de machine learning (ML) rapidamente. O SageMaker elimina o trabalho pesado de cada etapa do processo de aprendizado de máquina para facilitar o desenvolvimento de modelos de alta qualidade.
Azure Databricks é um serviço de análise de big data baseado em Apache Spark, rápido e colaborativo, projetado para ciência e engenharia de dados. O Azure Databricks configura seu ambiente Apache Spark em minutos, dimensiona automaticamente e colabora em projetos compartilhados em um espaço de trabalho interativo. O Azure Databricks dá suporte a Python, Scala, R, Java e SQL, bem como estruturas e bibliotecas de ciência de dados, incluindo TensorFlow, PyTorch e scikit-learn.
Microsoft Cognitive Toolkit (CNTK) é um kit de ferramentas de código aberto para aprendizado profundo distribuído de nível comercial. Ele descreve redes neurais como uma série de etapas computacionais por meio de um gráfico direcionado. O CNTK permite ao usuário realizar e combinar facilmente tipos de modelos populares, como DNNs feed-forward, redes neurais convolucionais (CNNs) e redes neurais recorrentes (RNNs/LSTMs). CNTK implementa aprendizado de descida gradiente estocástica (SGD, retropropagação de erro) com diferenciação automática e paralelização em várias GPUs e servidores.
Apple CoreML é uma estrutura que ajuda a integrar modelos de aprendizado de máquina ao seu aplicativo. Core ML fornece uma representação unificada para todos os modelos. Seu aplicativo usa APIs Core ML e dados do usuário para fazer previsões e treinar ou ajustar modelos, tudo no dispositivo do usuário. Um modelo é o resultado da aplicação de um algoritmo de aprendizado de máquina a um conjunto de dados de treinamento. Você usa um modelo para fazer previsões com base em novos dados de entrada.
Apache OpenNLP é uma biblioteca de código aberto para um kit de ferramentas baseado em aprendizado de máquina usado no processamento de texto em linguagem natural. Ele apresenta uma API para casos de uso como reconhecimento de entidade nomeada, detecção de frases, marcação POS (parte da fala), extração de recurso de tokenização, fragmentação, análise e resolução de coreferência.
Apache Airflow é uma plataforma de gerenciamento de fluxo de trabalho de código aberto criada pela comunidade para criar, agendar e monitorar fluxos de trabalho de forma programática. Instalar. Princípios. Escalável. O Airflow possui uma arquitetura modular e usa uma fila de mensagens para orquestrar um número arbitrário de trabalhadores. O Airflow está pronto para ser dimensionado até o infinito.
Open Neural Network Exchange (ONNX) é um ecossistema aberto que capacita os desenvolvedores de IA a escolher as ferramentas certas à medida que seu projeto evolui. ONNX fornece um formato de código aberto para modelos de IA, tanto de aprendizagem profunda quanto de ML tradicional. Ele define um modelo gráfico de computação extensível, bem como definições de operadores integrados e tipos de dados padrão.
Apache MXNet é uma estrutura de aprendizado profundo projetada para eficiência e flexibilidade. Ele permite combinar programação simbólica e imperativa para maximizar a eficiência e a produtividade. Em sua essência, o MXNet contém um agendador de dependência dinâmica que paraleliza automaticamente operações simbólicas e imperativas em tempo real. Além disso, uma camada de otimização de gráfico torna a execução simbólica rápida e eficiente em termos de memória. MXNet é portátil e leve, podendo ser dimensionado de forma eficaz para várias GPUs e várias máquinas. Suporte para Python, R, Julia, Scala, Go, Javascript e muito mais.
AutoGluon é um kit de ferramentas para aprendizado profundo que automatiza tarefas de aprendizado de máquina, permitindo que você obtenha facilmente um forte desempenho preditivo em seus aplicativos. Com apenas algumas linhas de código, você pode treinar e implantar modelos de aprendizado profundo de alta precisão em dados tabulares, de imagem e de texto.
Anaconda é uma plataforma de ciência de dados muito popular para aprendizado de máquina e aprendizado profundo que permite aos usuários desenvolver modelos, treiná-los e implantá-los.
PlaidML é um compilador tensor avançado e portátil para permitir aprendizado profundo em laptops, dispositivos incorporados ou outros dispositivos onde o hardware de computação disponível não é bem suportado ou a pilha de software disponível contém restrições de licença desagradáveis.
OpenCV é uma biblioteca altamente otimizada com foco em aplicações de visão computacional em tempo real. As interfaces C++, Python e Java suportam Linux, MacOS, Windows, iOS e Android.
Scikit-Learn é um módulo Python para aprendizado de máquina desenvolvido com base em SciPy, NumPy e matplotlib, tornando mais fácil a aplicação de implementações robustas e simples de muitos algoritmos populares de aprendizado de máquina.
Weka é um software de aprendizado de máquina de código aberto que pode ser acessado por meio de uma interface gráfica de usuário, aplicativos de terminal padrão ou API Java. É amplamente utilizado para ensino, pesquisa e aplicações industriais, contém uma infinidade de ferramentas integradas para tarefas padrão de aprendizado de máquina e, além disso, oferece acesso transparente a caixas de ferramentas conhecidas, como scikit-learn, R e Deeplearning4j.
Caffe é uma estrutura de aprendizagem profunda feita com expressão, velocidade e modularidade em mente. Ele é desenvolvido pela Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) e colaboradores da comunidade.
Theano é uma biblioteca Python que permite definir, otimizar e avaliar expressões matemáticas envolvendo matrizes multidimensionais de forma eficiente, incluindo forte integração com NumPy.
nGraph é uma biblioteca C++ de código aberto, compilador e tempo de execução para Deep Learning. O nGraph Compiler visa acelerar o desenvolvimento de cargas de trabalho de IA usando qualquer estrutura de aprendizado profundo e implantando em uma variedade de alvos de hardware. Ele fornece liberdade, desempenho e facilidade de uso para desenvolvedores de IA.
NVIDIA cuDNN é uma biblioteca de primitivas aceleradas por GPU para redes neurais profundas. cuDNN fornece implementações altamente ajustadas para rotinas padrão, como convolução direta e reversa, pooling, normalização e camadas de ativação. cuDNN acelera estruturas de aprendizagem profunda amplamente utilizadas, incluindo Caffe2, Chainer, Keras, MATLAB, MxNet, PyTorch e TensorFlow.
Huginn é um sistema auto-hospedado para a construção de agentes que executam tarefas automatizadas para você online. Ele pode ler a web, observar eventos e realizar ações em seu nome. Os Agentes de Huginn criam e consomem eventos, propagando-os ao longo de um gráfico direcionado. Pense nisso como uma versão hackeável do IFTTT ou Zapier em seu próprio servidor.
Netron é um visualizador de modelos de redes neurais, aprendizado profundo e aprendizado de máquina. Suporta ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 e UFF.
Dopamina é uma estrutura de pesquisa para prototipagem rápida de algoritmos de aprendizagem por reforço.
DALI é uma biblioteca acelerada por GPU que contém blocos de construção altamente otimizados e um mecanismo de execução para processamento de dados para acelerar aplicativos de treinamento e inferência de aprendizado profundo.
MindSpore Lite é uma nova estrutura de treinamento/inferência de aprendizagem profunda de código aberto que pode ser usada para cenários móveis, de borda e de nuvem.
Darknet é uma estrutura de rede neural de código aberto escrita em C e CUDA. É rápido, fácil de instalar e suporta computação de CPU e GPU.
PaddlePaddle é uma plataforma de aprendizado profundo fácil de usar, eficiente, flexível e escalonável, originalmente desenvolvida por cientistas e engenheiros do Baidu com o propósito de aplicar aprendizado profundo a muitos produtos do Baidu.
GoogleNotebookLM é uma ferramenta experimental de IA que usa o poder dos modelos de linguagem combinados com seu conteúdo existente para obter insights críticos com mais rapidez. Semelhante a um assistente de pesquisa virtual que pode resumir fatos, explicar ideias complexas e debater novas conexões com base nas fontes selecionadas.
Unilm é um pré-treinamento autosupervisionado em grande escala em tarefas, idiomas e modalidades.
O Semantic Kernel (SK) é um SDK leve que permite a integração de AI Large Language Models (LLMs) com linguagens de programação convencionais. O modelo de programação extensível SK combina funções semânticas de linguagem natural, funções nativas de código tradicional e memória baseada em incorporações, desbloqueando novo potencial e agregando valor às aplicações com IA.
Pandas AI é uma biblioteca Python que integra recursos generativos de inteligência artificial ao Pandas, tornando os dataframes conversacionais.
NCNN é uma estrutura de inferência de rede neural de alto desempenho otimizada para plataforma móvel.
MNN é uma estrutura de aprendizado profundo extremamente rápida e leve, testada em batalha por casos de uso críticos para os negócios no Alibaba.
MediaPipe é otimizado para desempenho ponta a ponta em uma ampla variedade de plataformas. Veja demonstrações Saiba mais ML complexo no dispositivo, simplificado Abstraímos as complexidades de tornar o ML no dispositivo personalizável, pronto para produção e acessível em todas as plataformas.
MegEngine é uma estrutura de aprendizado profundo rápida, escalonável e fácil de usar com três recursos principais: Estrutura unificada para treinamento e inferência.
ML.NET é uma biblioteca de aprendizado de máquina projetada como uma plataforma extensível para que você possa consumir outras estruturas populares de ML (TensorFlow, ONNX, Infer.NET e mais) e ter acesso a ainda mais cenários de aprendizado de máquina, como classificação de imagens, detecção de objetos e muito mais.
Ludwig é uma estrutura declarativa de aprendizado de máquina que facilita a definição de pipelines de aprendizado de máquina usando um sistema de configuração simples e flexível baseado em dados.
MMdnn é uma ferramenta abrangente e de estrutura cruzada para converter, visualizar e diagnosticar modelos de aprendizagem profunda (DL). O “MM” significa gerenciamento de modelo e “dnn” é o acrônimo de rede neural profunda. Converta modelos entre Caffe, Keras, MXNet, Tensorflow, CNTK, PyTorch Onnx e CoreML.
Horovod é uma estrutura de treinamento de aprendizagem profunda distribuída para TensorFlow, Keras, PyTorch e Apache MXNet.
Vaex é uma biblioteca Python de alto desempenho para DataFrames out-of-core preguiçosos (semelhantes ao Pandas), para visualizar e explorar grandes conjuntos de dados tabulares.
GluonTS é um pacote Python para modelagem probabilística de séries temporais, com foco em modelos baseados em aprendizagem profunda, baseados em PyTorch e MXNet.
MindsDB é um servidor ML-SQL que permite fluxos de trabalho de aprendizado de máquina para os bancos de dados e data warehouses mais poderosos usando SQL.
Jupyter Notebook é um aplicativo da web de código aberto que permite criar e compartilhar documentos que contêm código ativo, equações, visualizações e texto narrativo. O Jupyter é amplamente utilizado em setores que realizam limpeza e transformação de dados, simulação numérica, modelagem estatística, visualização de dados, ciência de dados e aprendizado de máquina.
Apache Spark é um mecanismo analítico unificado para processamento de dados em grande escala. Ele fornece APIs de alto nível em Scala, Java, Python e R e um mecanismo otimizado que oferece suporte a gráficos de computação geral para análise de dados. Ele também oferece suporte a um rico conjunto de ferramentas de nível superior, incluindo Spark SQL para SQL e DataFrames, MLlib para aprendizado de máquina, GraphX para processamento de gráficos e Streaming Estruturado para processamento de stream.
O Apache Spark Connector para SQL Server e Azure SQL é um conector de alto desempenho que permite usar dados transacionais em análises de big data e persistir resultados para consultas ad hoc ou relatórios. O conector permite que você use qualquer banco de dados SQL, local ou na nuvem, como fonte de dados de entrada ou coletor de dados de saída para trabalhos do Spark.
Apache PredictionIO é uma estrutura de aprendizado de máquina de código aberto para desenvolvedores, cientistas de dados e usuários finais. Ele oferece suporte à coleta de eventos, implantação de algoritmos, avaliação e consulta de resultados preditivos por meio de APIs REST. É baseado em serviços escalonáveis de código aberto como Hadoop, HBase (e outros bancos de dados), Elasticsearch, Spark e implementa o que é chamado de arquitetura Lambda.
Cluster Manager for Apache Kafka (CMAK) é uma ferramenta para gerenciar clusters Apache Kafka.
BigDL é uma biblioteca distribuída de aprendizado profundo para Apache Spark. Com o BigDL, os usuários podem escrever seus aplicativos de aprendizagem profunda como programas Spark padrão, que podem ser executados diretamente em clusters Spark ou Hadoop existentes.
Eclipse Deeplearning4J (DL4J) é um conjunto de projetos destinados a suportar todas as necessidades de um aplicativo de aprendizado profundo baseado em JVM (Scala, Kotlin, Clojure e Groovy). Isso significa começar com os dados brutos, carregá-los e pré-processá-los de qualquer lugar e formato para construir e ajustar uma ampla variedade de redes de aprendizagem profunda simples e complexas.
Tensorman é um utilitário para fácil gerenciamento de contêineres Tensorflow desenvolvido pela System76. Tensorman permite que o Tensorflow opere em um ambiente isolado que está contido no resto do sistema. Este ambiente virtual pode operar independentemente do sistema base, permitindo usar qualquer versão do Tensorflow em qualquer versão de uma distribuição Linux que suporte o tempo de execução do Docker.
Numba é um compilador de otimização de código aberto compatível com NumPy para Python, patrocinado pela Anaconda, Inc. Ele usa o projeto do compilador LLVM para gerar código de máquina a partir da sintaxe Python. Numba pode compilar um grande subconjunto de Python com foco numérico, incluindo muitas funções NumPy. Além disso, Numba tem suporte para paralelização automática de loops, geração de código acelerado por GPU e criação de ufuncs e retornos de chamada C.
Chainer é uma estrutura de aprendizado profundo baseada em Python que visa flexibilidade. Ele fornece APIs de diferenciação automática baseadas na abordagem definida por execução (gráficos computacionais dinâmicos), bem como APIs de alto nível orientadas a objetos para construir e treinar redes neurais. Ele também oferece suporte a CUDA/cuDNN usando CuPy para treinamento e inferência de alto desempenho.
XGBoost é uma biblioteca otimizada de aumento de gradiente distribuída, projetada para ser altamente eficiente, flexível e portátil. Ele implementa algoritmos de aprendizado de máquina na estrutura Gradient Boosting. XGBoost fornece um aumento de árvore paralela (também conhecido como GBDT, GBM) que resolve muitos problemas de ciência de dados de forma rápida e precisa. Ele oferece suporte ao treinamento distribuído em várias máquinas, incluindo clusters AWS, GCE, Azure e Yarn. Além disso, pode ser integrado com Flink, Spark e outros sistemas de fluxo de dados em nuvem.
cuML é um conjunto de bibliotecas que implementam algoritmos de aprendizado de máquina e funções matemáticas primitivas que compartilham APIs compatíveis com outros projetos RAPIDS. cuML permite que cientistas de dados, pesquisadores e engenheiros de software executem tarefas tabulares tradicionais de ML em GPUs sem entrar nos detalhes da programação CUDA. Na maioria dos casos, a API Python do cuML corresponde à API do scikit-learn.
Emu é uma biblioteca GPGPU para Rust com foco em portabilidade, modularidade e desempenho. É uma abstração específica de computação no estilo CUDA sobre WebGPU, fornecendo funcionalidade específica para fazer com que o WebGPU pareça mais com CUDA.
Scalene é um criador de perfil de CPU, GPU e memória de alto desempenho para Python que faz uma série de coisas que outros criadores de perfil Python não fazem e não podem fazer. Ele executa ordens de magnitude mais rápido do que muitos outros criadores de perfil, ao mesmo tempo que fornece informações muito mais detalhadas.
MLpack é uma biblioteca de aprendizado de máquina C++ rápida e flexível, escrita em C++ e construída na biblioteca de álgebra linear Armadillo, na pequena biblioteca de otimização numérica e em partes do Boost.
Netron é um visualizador de modelos de redes neurais, aprendizado profundo e aprendizado de máquina. Suporta ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 e UFF.
Lightning é uma ferramenta que cria e treina modelos PyTorch e os conecta ao ciclo de vida de ML usando modelos de aplicativos Lightning, sem lidar com infraestrutura DIY, gerenciamento de custos, escalonamento, etc.
OpenNN é uma biblioteca de redes neurais de código aberto para aprendizado de máquina. Ele contém algoritmos e utilitários sofisticados para lidar com muitas soluções de inteligência artificial.
H20 é uma plataforma AI Cloud que resolve problemas de negócios complexos e acelera a descoberta de novas ideias com resultados que você pode compreender e confiar.
Gensim é uma biblioteca Python para modelagem de tópicos, indexação de documentos e recuperação de similaridade com grandes corpora. O público-alvo é a comunidade de processamento de linguagem natural (PNL) e recuperação de informação (RI).
llama.cpp é um modelo LLaMA do Port of Facebook em C/C++.
hmmlearn é um conjunto de algoritmos para aprendizagem não supervisionada e inferência de modelos ocultos de Markov.
Nextjournal é um caderno para pesquisas reproduzíveis. Ele executa qualquer coisa que você possa colocar em um contêiner Docker. Melhore seu fluxo de trabalho com notebooks poliglotas, controle de versão automático e colaboração em tempo real. Economize tempo e dinheiro com provisionamento sob demanda, incluindo suporte a GPU.
IPython fornece uma arquitetura rica para computação interativa com:
Veles é uma plataforma distribuída para desenvolvimento rápido de aplicativos de aprendizado profundo atualmente desenvolvida pela Samsung.
DyNet é uma biblioteca de redes neurais desenvolvida pela Carnegie Mellon University e muitas outras. Ele é escrito em C++ (com ligações em Python) e foi projetado para ser eficiente quando executado em CPU ou GPU e para funcionar bem com redes que possuem estruturas dinâmicas que mudam para cada instância de treinamento. Esses tipos de redes são particularmente importantes em tarefas de processamento de linguagem natural, e DyNet tem sido usado para construir sistemas de última geração para análise sintática, tradução automática, inflexão morfológica e muitas outras áreas de aplicação.
Ray é uma estrutura unificada para dimensionar aplicativos de IA e Python. Ele consiste em um tempo de execução distribuído principal e um kit de ferramentas de bibliotecas (Ray AIR) para acelerar cargas de trabalho de ML.
sussurro.cpp é uma inferência de alto desempenho do modelo de reconhecimento automático de fala (ASR) Whisper da OpenAI.
ChatGPT Plus é um plano de assinatura piloto ( US$ 20/mês ) para ChatGPT, uma IA de conversação que pode conversar com você, responder perguntas de acompanhamento e desafiar suposições incorretas.
Auto-GPT é um “agente de IA” que, dado um objetivo em linguagem natural, pode tentar alcançá-lo dividindo-o em subtarefas e usando a internet e outras ferramentas em um loop automático. Ele usa APIs GPT-4 ou GPT-3.5 da OpenAI e está entre os primeiros exemplos de aplicação que usa GPT-4 para realizar tarefas autônomas.
Chatbot UI de mckaywrigley é um kit de chatbot avançado para modelos de chat da OpenAI construído sobre Chatbot UI Lite usando Next.js, TypeScript e Tailwind CSS. Esta versão da UI do ChatBot oferece suporte aos modelos GPT-3.5 e GPT-4. As conversas são armazenadas localmente no seu navegador. Você pode exportar e importar conversas para se proteger contra perda de dados. Veja uma demonstração.
Chatbot UI Lite de mckaywrigley é um kit inicial de chatbot simples para o modelo de bate-papo da OpenAI usando Next.js, TypeScript e Tailwind CSS. Veja uma demonstração.
MiniGPT-4 é um aprimoramento da compreensão da linguagem visual com modelos avançados de linguagem grande.
GPT4All é um ecossistema de chatbots de código aberto treinados em uma enorme coleção de dados de assistentes limpos, incluindo código, histórias e diálogos baseados em LLaMa.
GPT4All UI é um aplicativo da web Flask que fornece uma UI de bate-papo para interagir com o chatbot GPT4All.
Alpaca.cpp é um modelo rápido do tipo ChatGPT localizado localmente no seu dispositivo. Ele combina o modelo básico LLaMA com uma reprodução aberta do Stanford Alpaca, um ajuste fino do modelo básico para obedecer às instruções (semelhante ao RLHF usado para treinar ChatGPT) e um conjunto de modificações no llama.cpp para adicionar uma interface de chat.
llama.cpp é um modelo LLaMA do Port of Facebook em C/C++.
OpenPlayground é um playground para executar modelos do tipo ChatGPT localmente em seu dispositivo.
Vicuna é um chatbot de código aberto treinado pelo ajuste fino do LLaMA. Aparentemente, atinge mais de 90% de qualidade de chatgpt e custa US$ 300 para treinar.
Yeagar ai é um criador de agente Langchain projetado para ajudá-lo a construir, prototipar e implantar agentes com tecnologia de IA com facilidade.
Vicuna é criada ajustando um modelo base LLaMA usando aproximadamente 70 mil conversas compartilhadas por usuários coletadas de ShareGPT.com com APIs públicas. Para garantir a qualidade dos dados, ele converte o HTML novamente em markdown e filtra algumas amostras inadequadas ou de baixa qualidade.
ShareGPT é um lugar para compartilhar suas conversas mais loucas do ChatGPT com um clique. Com 198.404 conversas compartilhadas até o momento.
FastChat é uma plataforma aberta para treinar, servir e avaliar chatbots baseados em grandes modelos de linguagem.
Haystack é uma estrutura de PNL de código aberto para interagir com seus dados usando modelos Transformer e LLMs (GPT-4, ChatGPT e similares). Ele oferece ferramentas prontas para produção para criar rapidamente tomadas de decisões complexas, respostas a perguntas, pesquisa semântica, aplicativos de geração de texto e muito mais.
StableLM (Stability AI Language Models) é uma série de modelos de linguagem StableLM e será continuamente atualizado com novos pontos de verificação.
Dolly do Databricks é um modelo de linguagem grande que segue instruções, treinado na plataforma de aprendizado de máquina Databricks e licenciado para uso comercial.
GPTCach é uma biblioteca para criação de cache semântico para consultas LLM.
AlaC é um gerador de infraestrutura como código de inteligência artificial.
Adrenaline é uma ferramenta que permite conversar com sua base de código. É alimentado por análise estática, pesquisa vetorial e grandes modelos de linguagem.
OpenAssistant é um assistente baseado em chat que entende tarefas, pode interagir com sistemas de terceiros e recuperar informações dinamicamente para fazer isso.
DoctorGPT é um binário leve e independente que monitora os logs do seu aplicativo em busca de problemas e os diagnostica.
HttpGPT é um plugin Unreal Engine 5 que facilita a integração com serviços baseados em GPT da OpenAI (ChatGPT e DALL-E) por meio de solicitações REST assíncronas, facilitando a comunicação dos desenvolvedores com esses serviços. Também inclui Ferramentas de Editor para integrar a geração de imagens Chat GPT e DALL-E diretamente no Engine.
PaLM 2 é um grande modelo de linguagem de próxima geração que se baseia no legado de pesquisas inovadoras do Google em aprendizado de máquina e IA responsável. Inclui tarefas avançadas de raciocínio, incluindo código e matemática, classificação e resposta a perguntas, tradução e proficiência multilíngue e geração de linguagem natural melhor do que nossos LLMs de última geração anteriores.
Med-PaLM é um modelo de linguagem grande (LLM) projetado para fornecer respostas de alta qualidade a questões médicas. Ele aproveita o poder dos grandes modelos de linguagem do Google, que alinhamos ao domínio médico com um conjunto de demonstrações de especialistas médicos cuidadosamente selecionadas.
Sec-PaLM é um grande modelo de linguagem (LLMs), que acelera a capacidade de ajudar as pessoas responsáveis por manter suas organizações seguras. Estes novos modelos não só proporcionam às pessoas uma forma mais natural e criativa de compreender e gerir a segurança.
Voltar ao topo
Voltar ao topo
Voltar ao topo
Localai é uma API local-hospedada, orientada à comunidade, com a comunidade. Substituição de drop-in para o OpenAi Running LLMS em hardware de nível de consumo, sem necessidade de GPU. É uma API executar modelos compatíveis com GGML: llama, GPT4all, RWKV, Whisper, Vicuna, Koala, Gpt4all-J, Cerebras, Falcon, Dolly, Starcoder e muitos outros.
LLAMA.CPP é um porto do modelo de llama do Facebook em C/C ++.
Ollama é uma ferramenta para subir e correr com o LLAMA 2 e outros grandes modelos de idiomas localmente.
Localai é uma API local-hospedada, orientada à comunidade, com a comunidade. Substituição de drop-in para o OpenAi Running LLMS em hardware de nível de consumo, sem necessidade de GPU. É uma API executar modelos compatíveis com GGML: llama, GPT4all, RWKV, Whisper, Vicuna, Koala, Gpt4all-J, Cerebras, Falcon, Dolly, Starcoder e muitos outros.
Serge é uma interface da web para conversar com o Alpaca através do llama.cpp. Totalmente auto-hospedado e dockerizado, com uma API fácil de usar.
O Openllm é uma plataforma aberta para operar grandes modelos de idiomas (LLMS) na produção. Tune, sirva, implante e monitore qualquer LLMS com facilidade.
O LLAMA-GPT é um chatbot auto-hospedado, offline e parecido com chatgpt. Alimentado pela LLAMA 2. 100% privado, sem dados deixando seu dispositivo.
O LLAMA2 Webui é uma ferramenta para executar qualquer LLAMA 2 localmente com a interface do graduação na GPU ou CPU de qualquer lugar (Linux/Windows/Mac). Use llama2-wrapper como back-end local do LLAMA2 para agentes/aplicativos generativos.
LLAMA2.C é uma ferramenta para treinar a arquitetura LLAMA 2 LLM em Pytorch, então a infere com um arquivo C simples de 700 linhas (run.c).
Alpaca.cpp é um modelo rápido do tipo ChatGPT localmente no seu dispositivo. Ele combina o modelo da Fundação LLAMA com uma reprodução aberta de Stanford Alpaca, um ajuste fino do modelo básico para obedecer às instruções (semelhante ao RLHF usado para treinar ChatGPT) e um conjunto de modificações no llama.cpp para adicionar uma interface de bate-papo.
O GPT4all é um ecossistema de chatbots de código aberto treinados em uma enorme coleção de dados de assistente limpo, incluindo código, histórias e diálogos baseados em lhama.
Minigpt-4 é um entendimento aprimorado da linguagem da visão com modelos avançados de linguagem grande
O Lollms Webui é o hub para os modelos LLM (Modelo de Linguagem Grande). O objetivo é fornecer uma interface amigável para acessar e utilizar vários modelos LLM para uma ampla gama de tarefas. Se você precisa de ajuda para escrever, codificar, organizar dados, gerar imagens ou buscar respostas para suas perguntas.
O LM Studio é uma ferramenta para descobrir, baixar e executar o LLMS local.
A UI da Web Gradio é uma ferramenta para grandes modelos de idiomas. Suporta Transformers, GPTQ, LLAMA.CPP (GGML/GGUF), LLAMA.
O OpenPlayground é um jogo de reprodução para executar modelos semelhantes a ChatGPT localmente no seu dispositivo.
Vicuna é um chatbot de código aberto treinado pela Fine Tuning Llama. Aparentemente, atinge mais de 90% de qualidade do ChatGPT e custa US $ 300 para treinar.
O Yeagar AI é um criador de agentes da Langchain, projetado para ajudá-lo a construir, prototipo e implantar agentes movidos a IA com facilidade.
O KoboldCPP é um software de geração de texto AI fácil de usar para os modelos GGML. É um único autônomo distribuível de concordo, que construi llama.cpp, e adiciona um endpoint versátil da API da Kobold, suporte adicional de formato, compatibilidade com versões anteriores, bem como uma interface de usuário sofisticada com histórias persistentes, ferramentas de edição, salvar formatos, memória, mundo Informações, nota do autor, personagens e cenários.
Voltar ao topo
A lógica difusa é uma abordagem heurística que permite um processamento mais avançado de árvores de decisão e melhor integração com a programação baseada em regras.
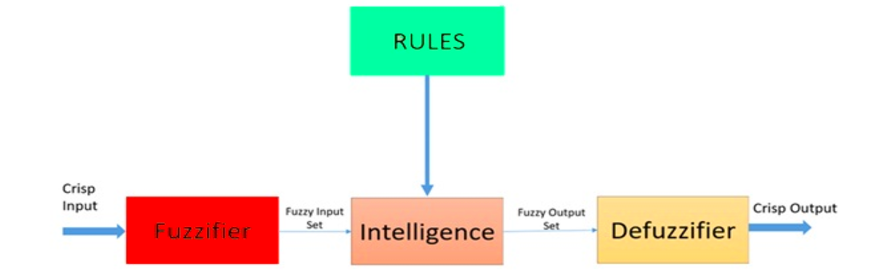
Arquitetura de um sistema lógico difuso. Fonte: ResearchGate
A Máquina Vector de Suporte (SVM) é um modelo de aprendizado de máquina supervisionado que usa algoritmos de classificação para problemas de classificação de dois grupos.

Máquina vetorial de suporte (SVM). Fonte: OpenClipart
As redes neurais são um subconjunto de aprendizado de máquina e estão no coração dos algoritmos de aprendizado profundo. O nome/estrutura é inspirado no cérebro humano que copia o processo que os neurônios/nós biológicos sinalizam um ao outro.
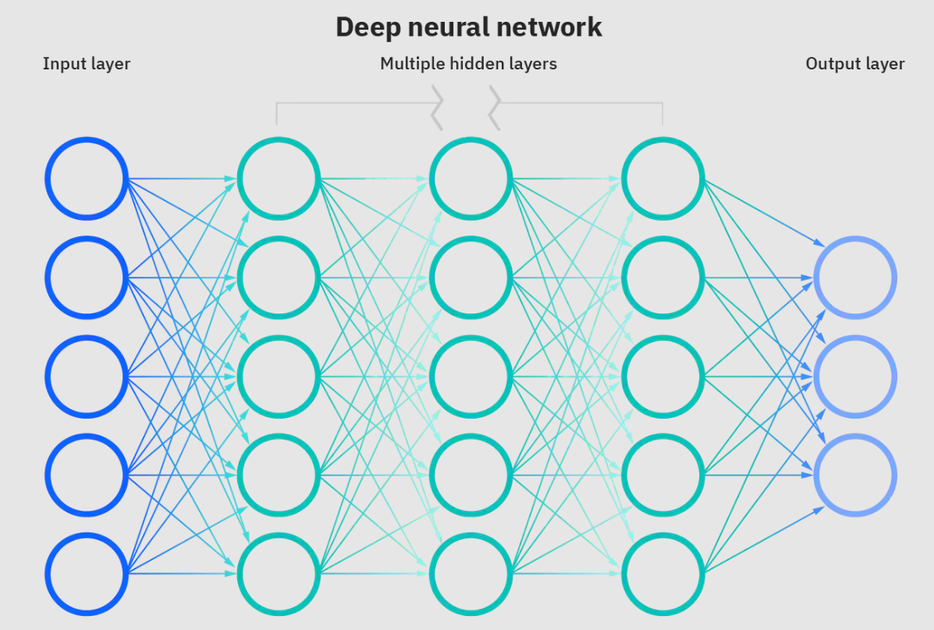
Rede neural profunda. Fonte: IBM
As redes neurais convolucionais (R-CNN) são um algoritmo de detecção de objetos que primeiro segmenta a imagem para encontrar possíveis caixas delimitadoras relevantes e depois executar o algoritmo de detecção para encontrar os objetos mais prováveis nessas caixas delimitadoras.
Redes neurais convolucionais. Fonte: CS231N
Redes neurais recorrentes (RNNs) é um tipo de rede neural artificial que usa dados seqüenciais ou dados de séries temporais.
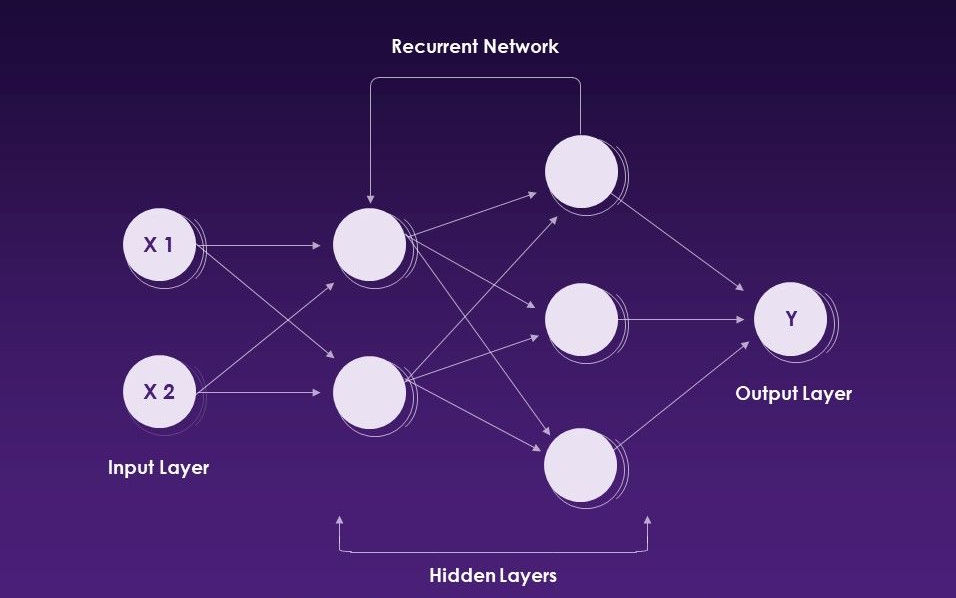
Redes neurais recorrentes. Fonte: slideteam
As perceptrons multicamadas (MLPs) são redes neurais de várias camadas compostas por múltiplas camadas de perceptrons com uma ativação limiar.
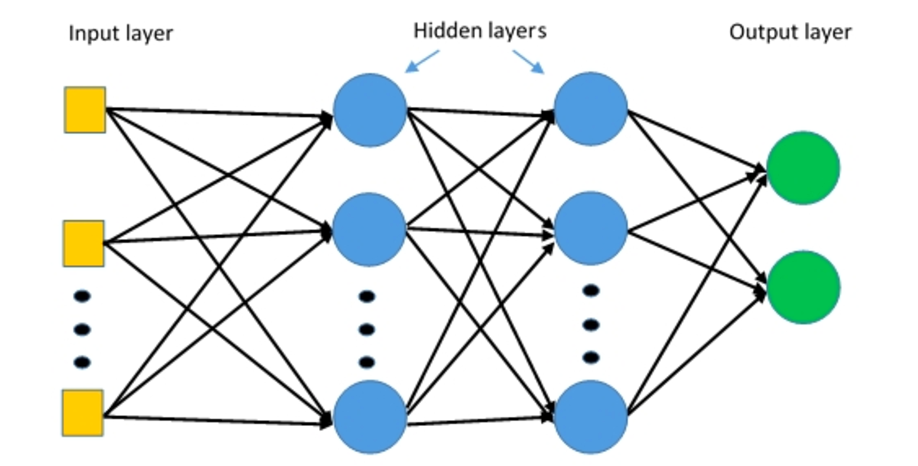
Perceptrons multicamadas. Fonte: Deepai
A floresta aleatória é um algoritmo de aprendizado de máquina comumente usado, que combina a produção de várias árvores de decisão para atingir um único resultado. Uma árvore de decisão em uma floresta não pode ser podada para amostragem e, portanto, a seleção de previsão. Sua facilidade de uso e flexibilidade alimentaram sua adoção, pois lida com problemas de classificação e regressão.
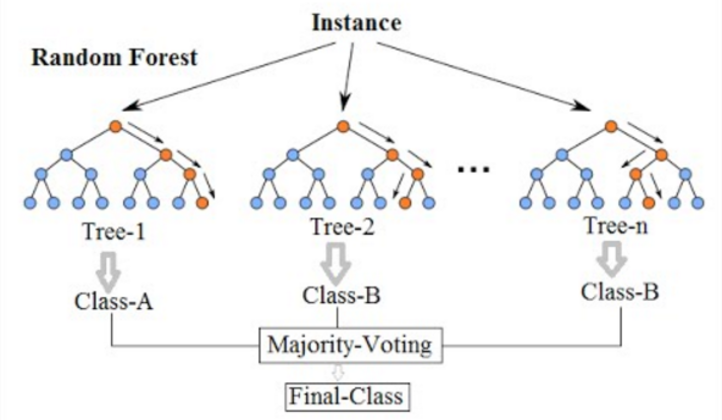
Floresta aleatória. Fonte: wikimedia
As árvores de decisão são modelos estruturados de árvores para classificação e regressão.
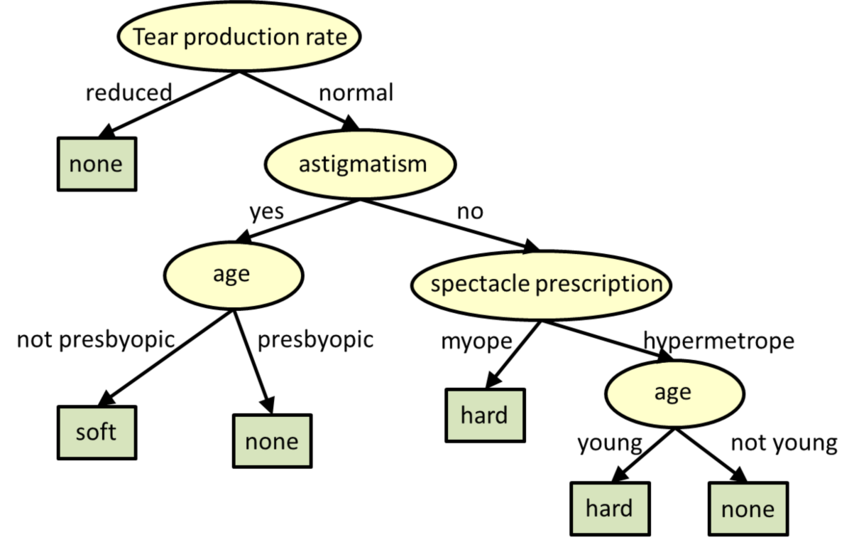
** Árvores de decisão. Fonte: CMU
A ingênua Bayes é um algoritmo de aprendizado de máquina que é usado problemas de calssificação resolvidos. É baseado na aplicação do teorema de Bayes com fortes suposições de independência entre os recursos.

Teorema de Bayes. Fonte: Mathisfun
Voltar ao topo

O Pytorch é uma estrutura de aprendizado profundo de código aberto que acelera o caminho da pesquisa para a produção, usada para aplicações como visão computacional e processamento de linguagem natural. O Pytorch é desenvolvido pelo AI Research Lab do Facebook.
Introdução com Pytorch
Documentação de Pytorch
Fórum de discussão de Pytorch
Principais cursos de Pytorch online | Curso
Principais cursos de Pytorch online | Udemy
Aprenda Pytorch com cursos e aulas on -line | edX
Fundamentos de Pytorch - Aprenda | Microsoft Docs
Introdução ao aprendizado profundo com Pytorch | Udacidade
Desenvolvimento Pytorch no Código do Visual Studio
Pytorch no Azure - Aprendizagem profunda com Pytorch | Microsoft Azure
Pytorch - Azure Databricks | Microsoft Docs
Aprendizagem profunda com Pytorch | Amazon Web Services (AWS)
Introdução com Pytorch no Google Cloud
O Pytorch Mobile é um fluxo de trabalho de ML de ponta a ponta, do treinamento à implantação para dispositivos móveis iOS e Android.
O TorchScript é uma maneira de criar modelos serializáveis e otimizáveis a partir do código Pytorch. Isso permite que qualquer programa de Torchscript seja salvo de um processo python e carregado em um processo em que não há dependência do Python.
A TorchServe é uma ferramenta flexível e fácil de usar para servir modelos Pytorch.
Keras é uma API de redes neurais de alto nível, escrita em Python e capaz de correr em cima do Tensorflow, CNTK ou Theano. Foi desenvolvido com foco em permitir a experimentação rápida. É capaz de executar em cima do TensorFlow, Microsoft Cognitive Toolkit, R, Theano ou PlaidML.
O OnNX Runtime é um acelerador de inferência e treinamento de alto desempenho e alto desempenho. Ele suporta modelos de estruturas de aprendizado profundo, como Pytorch e Tensorflow/Keras, bem como bibliotecas clássicas de aprendizado de máquina, como Scikit-Learn, LightGBM, XGBoost, etc.
A Kornia é uma biblioteca de visão computacional diferenciável que consiste em um conjunto de rotinas e módulos diferenciáveis para resolver problemas genéricos de CV (Visão Computador).
O Pytorch-NLP é uma biblioteca para processamento de linguagem natural (PNL) em Python. Ele foi construído com as pesquisas mais recentes em mente e foi projetado desde o primeiro dia para apoiar prototipagem rápida. O Pytorch-NLP vem com incorporações pré-treinadas, amostradores, carregadores de dados, métricas, módulos de rede neural e codificadores de texto.
A Ignite é uma biblioteca de alto nível para ajudar no treinamento e na avaliação de redes neurais em Pytorch de maneira flexível e transparente.
O Hummingbird é uma biblioteca para compilar modelos tradicionais de ML treinados em cálculos tensores. Ele permite que os usuários aproveitem perfeitamente as estruturas de redes neurais (como o Pytorch) para acelerar os modelos tradicionais de ML.
A Deep Graph Library (DGL) é um pacote Python criado para facilitar a implementação da família de modelos de rede neural gráfica, em cima de Pytorch e outras estruturas.
Tensorly é uma API de alto nível para métodos tensores e redes neurais tensorizadas profundas no Python, que visa simplificar o aprendizado tensorado.
O GPytorch é uma biblioteca de processos gaussianos implementada usando o Pytorch, projetado para criar modelos de processos gaussianos escaláveis e flexíveis.
Poutyne é uma estrutura do tipo Keras para Pytorch e lida com grande parte do código de explicação de caldeira necessário para treinar redes neurais.
Forte é um kit de ferramentas para a criação de pipelines NLP com componentes composíveis, interfaces de dados convenientes e interação cruzada.
A Torchmetrics é uma métrica de aprendizado de máquina para aplicativos de pytorch distribuídos e distribuídos.
Captum é uma biblioteca extensível de código aberto para interpretabilidade do modelo construída em Pytorch.
O Transformer é um processamento de linguagem natural de última geração para Pytorch, Tensorflow e Jax.
A Hydra é uma estrutura para configurar elegantemente aplicativos complexos.
O Acelerate é uma maneira simples de treinar e usar modelos Pytorch com precisão multi-GPU, TPU, mista.
Ray é uma estrutura rápida e simples para criar e executar aplicativos distribuídos.
Parlai é uma plataforma unificada para compartilhar, treinar e avaliar modelos de diálogo em muitas tarefas.
Pytorchvideo é uma biblioteca de aprendizado profundo para pesquisa em vídeo. Hospeda vários modelos, conjuntos de dados focados em vídeo, pipelines de treinamento e muito mais.
A Opacus é uma biblioteca que permite o treinamento de modelos de Pytorch com privacidade diferencial.
O Pytorch Lightning é uma biblioteca ML do tipo Keras para Pytorch. Ele deixa a lógica de treinamento e validação do núcleo para você e automatiza o restante.
O Pytorch Geométrico Temporal é uma biblioteca de extensão temporal (dinâmica) para a geométrica de Pytorch.
A Pytorch Geométrica é uma biblioteca para aprendizado profundo sobre dados de entrada irregulares, como gráficos, nuvens de pontos e coletores.
A Raster Vision é uma estrutura de código aberto para aprendizado profundo em imagens de satélite e aérea.
Crypten é uma estrutura para a privacidade que preserva o ML. Seu objetivo é tornar as técnicas de computação seguras acessíveis aos profissionais de ML.
O Optuna é uma estrutura de otimização de hiperparâmetro de código aberto para automatizar a pesquisa de hiperparâmetro.
O Pyro é uma linguagem de programação probabilística universal (PPL) escrita em Python e suportada por Pytorch no back -end.
A Albumentations é uma biblioteca de aumento de imagem rápida e extensível para diferentes tarefas de CV, como classificação, segmentação, detecção de objetos e estimativa de pose.
A Skorch é uma biblioteca de alto nível para Pytorch que fornece compatibilidade completa do Scikit-Learn.
O MMF é uma estrutura modular para pesquisa multimodal de visão e idioma da pesquisa da IA do Facebook (FAIR).
O AdapDDL é uma estrutura de treinamento e programação de aprendizado profundo adaptativo de recursos.
A Polyaxon é uma plataforma para construir, treinar e monitorar aplicativos de aprendizado profundo em larga escala.
TextBrewer é um kit de ferramentas de destilação de conhecimento baseado em Pytorch para processamento de linguagem natural
Advertorch é uma caixa de ferramentas para pesquisa de robustez adversária. Ele contém módulos para gerar exemplos adversários e defender contra ataques.
Nemo é um kit de ferramentas AA para a IA conversacional.
Clinicadl é uma estrutura para a classificação reproduzível da doença de Alzheimer
O estável Baselines3 (SB3) é um conjunto de implementações confiáveis de algoritmos de aprendizado de reforço em Pytorch.
Torchio é um conjunto de ferramentas para ler com eficiência, pré -processamento, amostra, aumentar e escrever imagens médicas em 3D em aplicativos de aprendizado profundo escritos em Pytorch.
Pysyft é uma biblioteca Python para a privacidade criptografada, preservando o aprendizado profundo.
Flair é uma estrutura muito simples para o processamento de linguagem natural de última geração (PNL).
O Glow é um compilador de ML que acelera o desempenho de estruturas de aprendizado profundo em diferentes plataformas de hardware.
O FairScale é uma biblioteca de extensão Pytorch para treinamento de alto desempenho e larga escala em uma ou várias máquinas/nós.
A Monai é uma profunda estrutura de aprendizado que fornece recursos fundamentais otimizados para o domínio para o desenvolvimento de fluxos de trabalho de treinamento em imagem em saúde.
O PFRL é uma biblioteca de aprendizado de reforço profundo que implementa vários algoritmos de reforço profundo de ponta em Python usando Pytorch.
O Einops é uma operações tensoras flexíveis e poderosas para um código legível e confiável.
O Pytorch3D é uma biblioteca de aprendizado profundo que fornece componentes eficientes e reutilizáveis para a pesquisa em visão computacional 3D com a Pytorch.
O Ensemble Pytorch é uma estrutura unificada para Pytorch para melhorar o desempenho e a robustez do seu modelo de aprendizado profundo.
Luzmente é uma estrutura de visão computacional para o aprendizado auto-supervisionado.
HIVER é uma biblioteca que facilita a implementação de algoritmos de meta-aprendizagem baseados em gradiente arbitrariamente e loops de otimização aninhados com pytorch quase vanilla.
Horovod é uma biblioteca de treinamento distribuída para estruturas de aprendizado profundo. A Horovod pretende tornar o DL distribuído rápido e fácil de usar.
Pennylane é uma biblioteca para ML quântico, diferenciação automática e otimização de cálculos híbridos clássicos quânticos.
Detectron2 é a plataforma de próxima geração da Fair para detecção e segmentação de objetos.
O Fastai é uma biblioteca que simplifica as redes neurais rápidas e precisas usando as melhores práticas modernas.
Voltar ao topo

TensorFlow é uma plataforma de código aberto ponta a ponta para aprendizado de máquina. Possui um ecossistema abrangente e flexível de ferramentas, bibliotecas e recursos da comunidade que permite que os pesquisadores pressionem o estado da arte em ML e os desenvolvedores construam facilmente e implantam aplicativos alimentados por ML.
Introdução ao Tensorflow
Tutoriais do TensorFlow
Certificado de desenvolvedor TensorFlow | TensorFlow
Comunidade Tensorflow
Modelos e conjuntos de dados Tensorflow
Cloud Tensorflow
Educação de aprendizado de máquina | TensorFlow
Top Tensorflow Cursos Online | Curso
Top Tensorflow Cursos Online | Udemy
Aprendizagem profunda com tensorflow | Udemy
Aprendizagem profunda com tensorflow | edX
Introdução ao Tensorflow para aprendizado profundo | Udacidade
Introdução ao TensorFlow: Curso de Aprendizado de Máquina | Google Developers
Treinar e implantar um modelo de tensorflow - Azure Machine Learning
Aplique modelos de aprendizado de máquina nas funções do Azure com Python e Tensorflow | Microsoft Azure
Aprendizagem profunda com tensorflow | Amazon Web Services (AWS)
Tensorflow - Amazon EMR | Documentação da AWS
Tensorflow Enterprise | Google Nuvem
O Tensorflow Lite é uma estrutura de aprendizado profundo de código aberto para implantar modelos de aprendizado de máquina em dispositivos móveis e IoT.
Tensorflow.js é uma biblioteca JavaScript que permite desenvolver ou executar modelos ML em JavaScript e usar ML diretamente no lado do cliente do navegador, lado do servidor via node.js, móvel nativo via React Native, desktop nativo via elétron e até no IOT dispositivos via node.js no Raspberry Pi.
O Tensorflow_macos é uma versão otimizada para Mac dos addons TensorFlow e TensorFlow para MacOS 11.0+ acelerado usando a estrutura de computação ML da Apple.
O Google Colaboratory é um ambiente de notebook Jupyter gratuito que não requer configuração e é executado inteiramente na nuvem, permitindo que você execute o código TensorFlow no seu navegador com um único clique.
What-If Tool é uma ferramenta para sondagem sem código de modelos de aprendizado de máquina, útil para compreensão, depuração e justiça de modelos. Disponível em notebooks Tensorboard e Jupyter ou Colab.
O Tensorboard é um conjunto de ferramentas de visualização para entender, depurar e otimizar os programas TensorFlow.
Keras é uma API de redes neurais de alto nível, escrita em Python e capaz de correr em cima do Tensorflow, CNTK ou Theano. Foi desenvolvido com foco em permitir a experimentação rápida. É capaz de executar em cima do TensorFlow, Microsoft Cognitive Toolkit, R, Theano ou PlaidML.
O XLA (álgebra linear acelerada) é um compilador específico do domínio para álgebra linear que otimiza os cálculos do tensorflow. Os resultados são melhorias em velocidade, uso de memória e portabilidade nas plataformas de servidor e móveis.
O ML Perf é um amplo conjunto de benchmark ML para medir o desempenho de estruturas de software ML, aceleradores de hardware ML e plataformas de nuvem ML.
O Tensorflow Playground é um ambiente de desenvolvimento para mexer com uma rede neural no seu navegador.
A TPU Research Cloud (TRC) é um programa permite que os pesquisadores solicitem acesso a um aglomerado de mais de 1.000 TPUs em nuvem, sem nenhum custo, para ajudá -los a acelerar a próxima onda de avanços de pesquisa.
O MLIR é uma nova representação intermediária e estrutura do compilador.
A Lattice é uma biblioteca para soluções de ML flexíveis, controladas e interpretáveis com restrições de forma de senso comum.
O Tensorflow Hub é uma biblioteca para aprendizado de máquina reutilizável. Faça o download e reutilize os modelos treinados mais recentes com uma quantidade mínima de código.
O Tensorflow Cloud é uma biblioteca para conectar seu ambiente local ao Google Cloud.
O TensorFlow Model Optimization Toolkit é um conjunto de ferramentas para otimizar os modelos ML para implantação e execução.
O TensorFlow Recomendres é uma biblioteca para criar modelos de sistema de recomendação.
O TensorFlow Text é uma coleção de classes e operações relacionadas a texto e NLP prontas para uso com o TensorFlow 2.
A Tensorflow Graphics é uma biblioteca de funcionalidades gráficas de computadores que variam de câmeras, luzes e materiais a renderizadores.
O TensorFlow Federated é uma estrutura de código aberto para aprendizado de máquina e outros cálculos em dados descentralizados.
A probabilidade do TensorFlow é uma biblioteca para raciocínio probabilístico e análise estatística.
O Tensor2tensor é uma biblioteca de modelos e conjuntos de dados de aprendizado profundo projetados para tornar o aprendizado profundo mais acessível e acelerar a pesquisa de ML.
A TensorFlow Privacy é uma biblioteca Python que inclui implementações de otimizadores do TensorFlow para treinamento de modelos de aprendizado de máquina com privacidade diferencial.
O Tensorflow Ranking é uma biblioteca para técnicas de aprendizado de rank (LTR) na plataforma Tensorflow.
Os agentes do TensorFlow é uma biblioteca para o aprendizado de reforço no TensorFlow.
O Tensorflow Addons é um repositório de contribuições que se conformam a padrões de API bem estabelecidos, mas implementam novas funcionalidades não disponíveis no Core Tensorflow, mantidas pelos addons SIG. O TensorFlow suporta nativamente um grande número de operadores, camadas, métricas, perdas e otimizadores.
O Tensorflow E/S é um conjunto de dados, streaming e extensões do sistema de arquivos, mantido pelo SIG IO.
O Tensorflow Quantum é uma biblioteca de aprendizado de máquina quântica para prototipagem rápida de modelos ML clássicos quânticos híbridos.
A dopamina é uma estrutura de pesquisa para prototipagem rápida de algoritmos de aprendizado de reforço.
O TRFL é uma biblioteca para os blocos de construção de aprendizado de reforço criados pela DeepMind.
O Mesh Tensorflow é um idioma para o aprendizado profundo distribuído, capaz de especificar uma ampla classe de cálculos de tensores distribuídos.
RaggedEnsors é uma API que facilita o armazenamento e manipula dados com forma não uniforme, incluindo texto (palavras, frases, caracteres) e lotes de comprimento variável.
O UNICODE OPS é uma API que suporta o trabalho com texto Unicode diretamente no TensorFlow.
Magenta é um projeto de pesquisa que explora o papel do aprendizado de máquina no processo de criação de arte e música.
O Nucleus é uma biblioteca de código Python e C ++ projetado para facilitar a leitura, gravação e analisa os dados em formatos de arquivos genômicos comuns como SAM e VCF.
O Sonnet é uma biblioteca da DeepMind para a construção de redes neurais.
O aprendizado estruturado neural é uma estrutura de aprendizado para treinar redes neurais, alavancando sinais estruturados, além de insumos de recursos.
A remediação do modelo é uma biblioteca para ajudar a criar e treinar modelos de maneira a reduzir ou eliminar os danos ao usuário resultantes de vieses de desempenho subjacentes.
Os indicadores de justiça são uma biblioteca que permite o cálculo fácil de métricas de justiça comumente identificadas para classificadores binários e multiclasse.
Decision Forests é um algoritmos de última geração para treinamento, atendimento e interpretação de modelos que usam florestas de decisão para classificação, regressão e classificação.
Voltar ao topo

O Core ML é uma estrutura da Apple para integrar modelos de aprendizado de máquina em aplicativos em execução em dispositivos Apple (incluindo iOS, WatchOS, MacOS e TVOS). O Core ML apresenta um formato de arquivo público (.mlmodel) para um amplo conjunto de métodos ML, incluindo redes neurais profundas (tanto convolucionais quanto recorrentes), conjuntos de árvores com modelos lineares de reforço e generalização. Os modelos neste formato podem ser diretamente integrados aos aplicativos através do Xcode.
Introdução ao Core ML
Integração de um modelo ML Core em seu aplicativo
Modelos principais de ML
Referência da API ML central
Especificação Core ML
Fóruns de desenvolvedores da Apple para ML Core
Top Core ML Cursos Online | Udemy
Top Core ML Cursos Online | Curso
IBM Watson Services para Core ML | IBM
Gere ativos principais ML usando a inspeção visual da IBM Maximo | IBM
O Core ML Tools é um projeto que contém ferramentas de suporte para a conversão, edição e validação do ML do ML.
Criar ML é uma ferramenta que fornece novas maneiras de treinamento de modelos de aprendizado de máquina no seu Mac. Ele tira a complexidade do treinamento modelo enquanto produz modelos poderosos de ML.
Tensorflow_macos é uma versão otimizada para Mac do Tensorfl


