llm data annotation
1.0.0
Esta estrutura combina a experiência humana com a eficiência de Large Language Models (LLMs), como o GPT-3.5 da OpenAI, para simplificar a anotação de conjuntos de dados e a melhoria do modelo. A abordagem iterativa garante a melhoria contínua da qualidade dos dados e, consequentemente, o desempenho dos modelos ajustados a partir desses dados. Isso não apenas economiza tempo, mas também permite a criação de LLMs personalizados que utilizam anotadores humanos e precisão baseada em LLM.
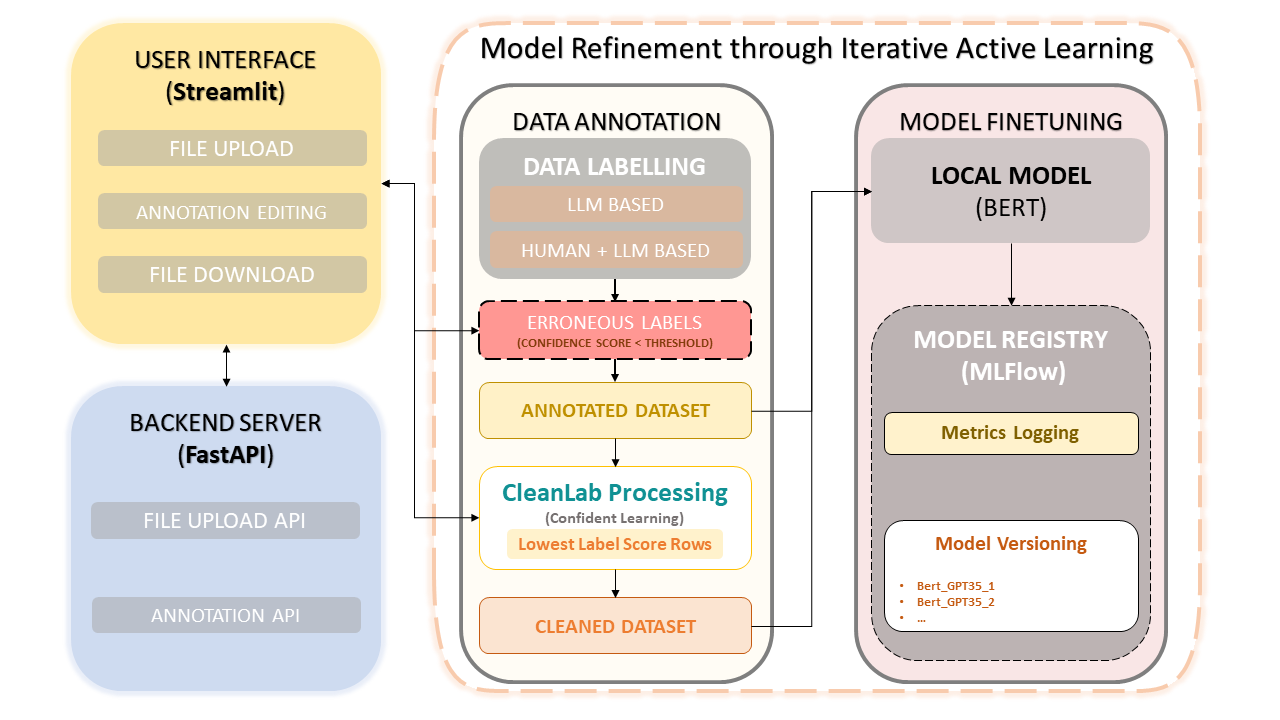
Upload e anotação de conjunto de dados
Correções manuais de anotação
CleanLab: Abordagem de Aprendizagem Confiante
Versionamento e salvamento de dados
Treinamento de modelo
pip install -r requirements.txtInicie o back-end FastAPI :
uvicorn app:app --reloadExecute o aplicativo Streamlit :
streamlit run frontend.pyInicie a IU do MLflow : para visualizar modelos, métricas e modelos registrados, você pode acessar a IU do MLflow com o seguinte comando:
mlflow uiAcesse os links fornecidos em seu navegador :
http://127.0.0.1:5000 .Siga as instruções na tela para fazer upload, anotar, corrigir e treinar seu conjunto de dados.
A aprendizagem confiante emergiu como uma técnica inovadora na aprendizagem supervisionada e na supervisão fraca. O objetivo é caracterizar o ruído do rótulo, encontrar erros de rótulo e aprender de forma eficiente com rótulos ruidosos. Ao eliminar dados ruidosos e classificar exemplos para treinar com confiança, este método garante um conjunto de dados limpo e confiável, melhorando o desempenho geral do modelo.
Este projeto é de código aberto sob a licença MIT.


