EasyEdit
1.0.0

Uma estrutura de edição de conhecimento fácil de usar para modelos de linguagem grandes.
Instalação • QuickStart • Doc • Paper • Demo • Benchmark • Contribuidores • Slides • Vídeo • Apresentado por AK
23/10/2024, o EasyEdit integra métodos de decodificação restritos desde a edição direcionada para mitigar alucinações em LLM e MLLM, com informações detalhadas disponíveis em DoLa e DeCo.
26/09/2024, ?? nosso artigo "WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models" foi aceito pelo NeurIPS 2024 .
20/09/2024, ?? nossos artigos: "Mecanismos de conhecimento em modelos de linguagem grande: uma pesquisa e perspectiva" e "Editando conhecimento conceitual para modelos de linguagem grande" foram aceitos pelo EMNLP 2024 Findings .
29/07/2024, o EasyEdit adicionou um novo algoritmo de edição de modelo EMMET, que generaliza ROME para a configuração em lote. Basicamente, isso permite fazer edições em lote usando a função de perda ROME.
Em 23/07/2024, lançamos um novo artigo: "Mecanismos de conhecimento em grandes modelos de linguagem: uma pesquisa e perspectiva", que analisa como o conhecimento é adquirido, utilizado e evolui em grandes modelos de linguagem. Esta pesquisa pode fornecer os mecanismos fundamentais para manipular (editar) o conhecimento de forma precisa e eficiente em LLMs.
04/06/2024, ?? O EasyEdit Paper foi aceito pelo ACL 2024 System Demonstration Track.
Em 03/06/2024, lançamos um artigo intitulado "WISE: Repensando a memória do conhecimento para a edição de modelos ao longo da vida de modelos de linguagem grande" , juntamente com a introdução de uma nova tarefa de edição: Edição contínua de conhecimento e o método de edição ao longo da vida correspondente chamado WISE.
24/04/2024, EasyEdit anunciou suporte para o método ROME para Llama3-8B . Os usuários são aconselhados a atualizar seu pacote de transformadores para a versão 4.40.0.
29/03/2024, EasyEdit introduziu suporte de reversão para GRACE . Para uma introdução detalhada, consulte a documentação do EasyEdit. As atualizações futuras incluirão gradualmente suporte à reversão para outros métodos.
Em 22/03/2024, um novo artigo intitulado "Desintoxicando modelos de linguagem grande por meio da edição de conhecimento" foi lançado, junto com um novo conjunto de dados chamado SafeEdit e um novo método de desintoxicação chamado DINM.
Em 12/03/2024, outro artigo intitulado "Editando conhecimento conceitual para modelos de linguagem grande" foi lançado, apresentando um novo conjunto de dados chamado ConceptEdit.
01/03/2024, EasyEdit adicionou suporte para um novo método chamado FT-M . Este método envolve treinar uma camada MLP específica usando perda de entropia cruzada na resposta alvo e mascarando o texto original . Supera a implementação FT-L em ROMA. Agradecemos ao autor da edição nº 173 por seus conselhos.
27/02/2024, EasyEdit adicionou suporte para um novo método chamado InstructEdit, com detalhes técnicos fornecidos no artigo "InstructEdit: Edição de conhecimento baseada em instruções para modelos de linguagem grande" .
Accelerate .Um estudo abrangente de edição de conhecimento para modelos de linguagem grande [artigo][benchmark][código]
Tutorial IJCAI 2024 Google Drive
Tutorial COLING 2024 Google Drive
Tutorial AAAI 2024 Google Drive
Tutorial AACL 2023 [Google Drive] [Baidu Pan]
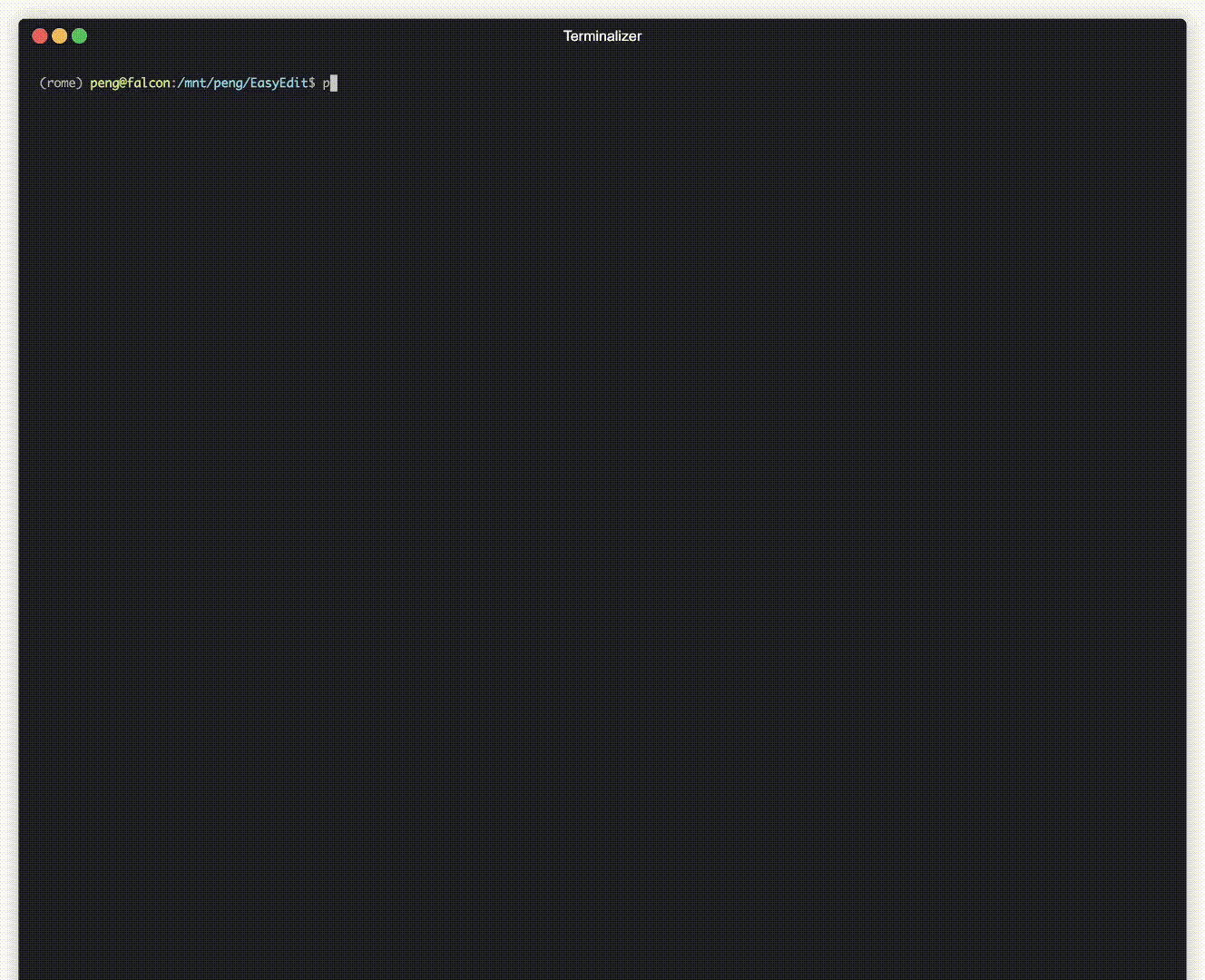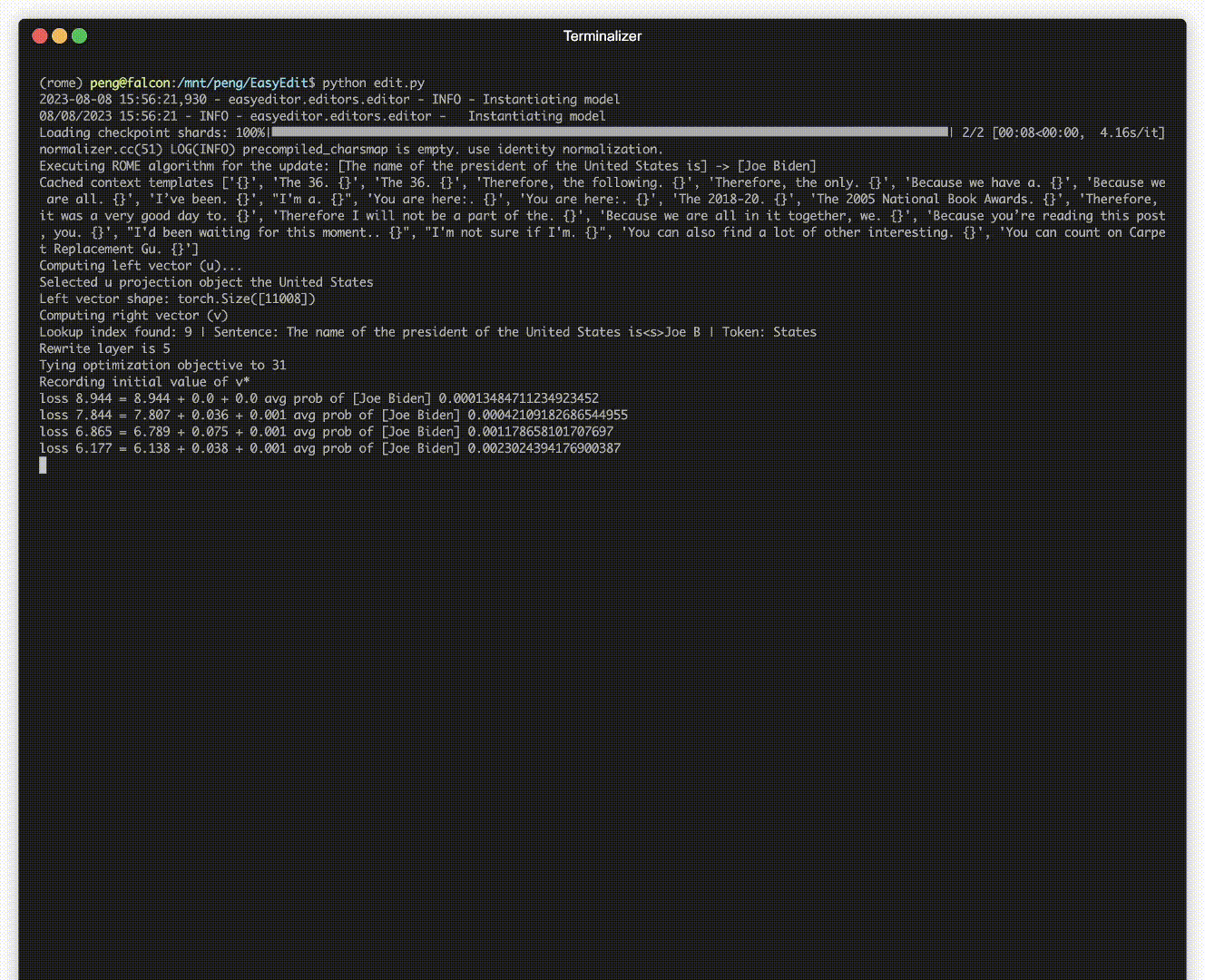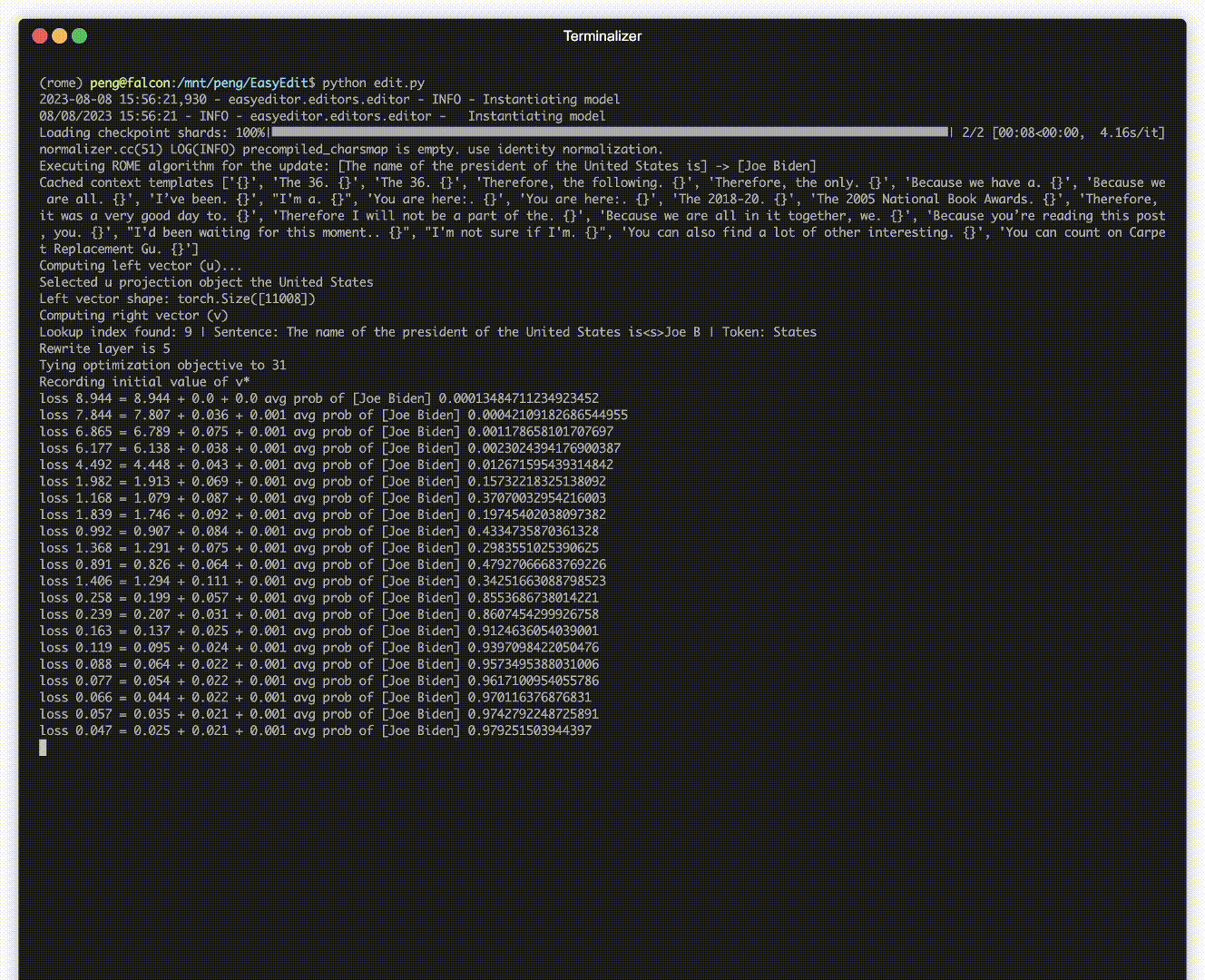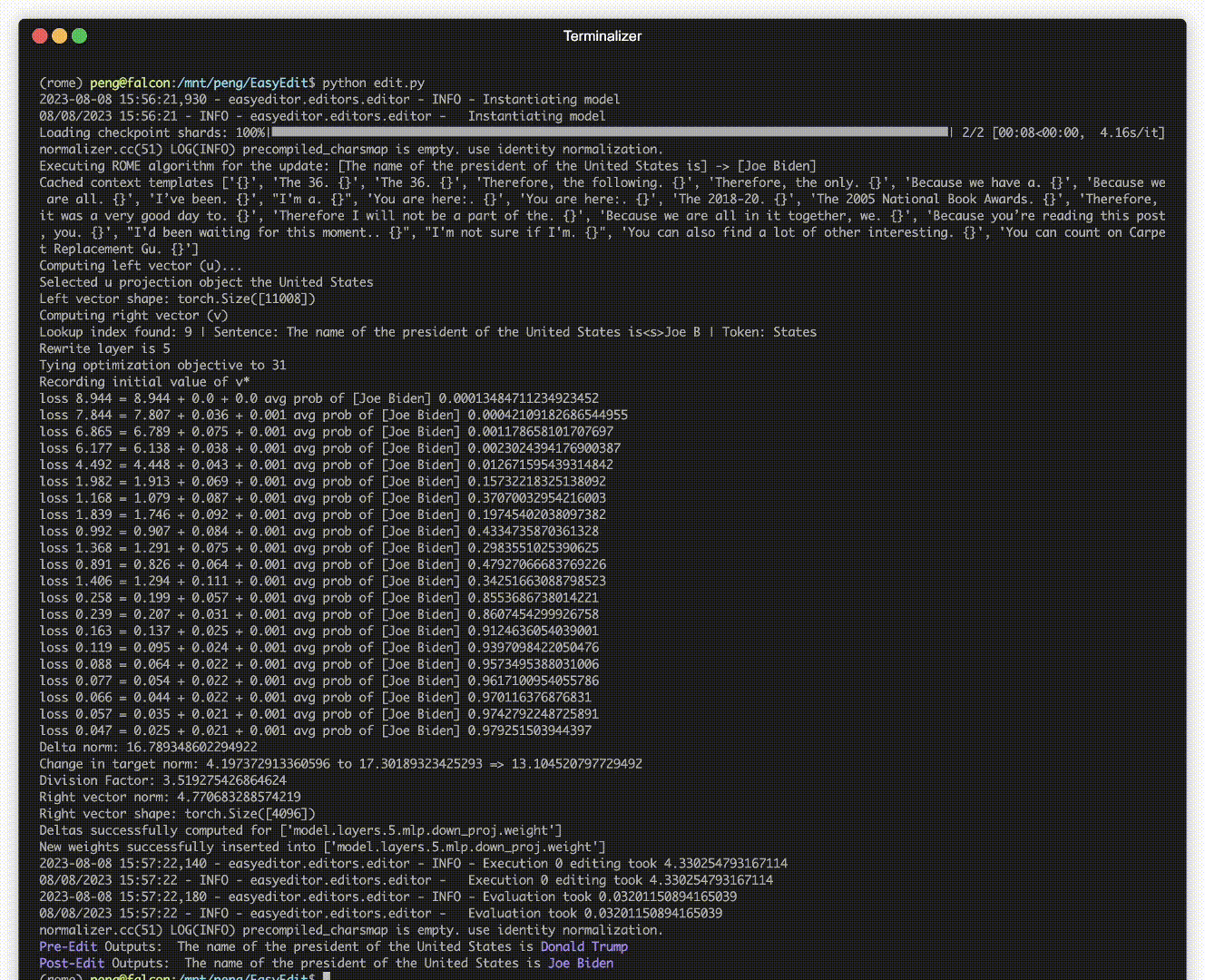
Há uma demonstração de edição. O arquivo GIF é criado pelo Terminalizer.
Fornecemos um prático Jupyter Notebook! Ele permite que você edite o conhecimento de um LLM sobre o presidente dos EUA, mudando de Biden para Trump e até mesmo de volta para Biden. Isso inclui métodos como WISE, AlphaEdit, AdaLoRA e edição baseada em Prompt.
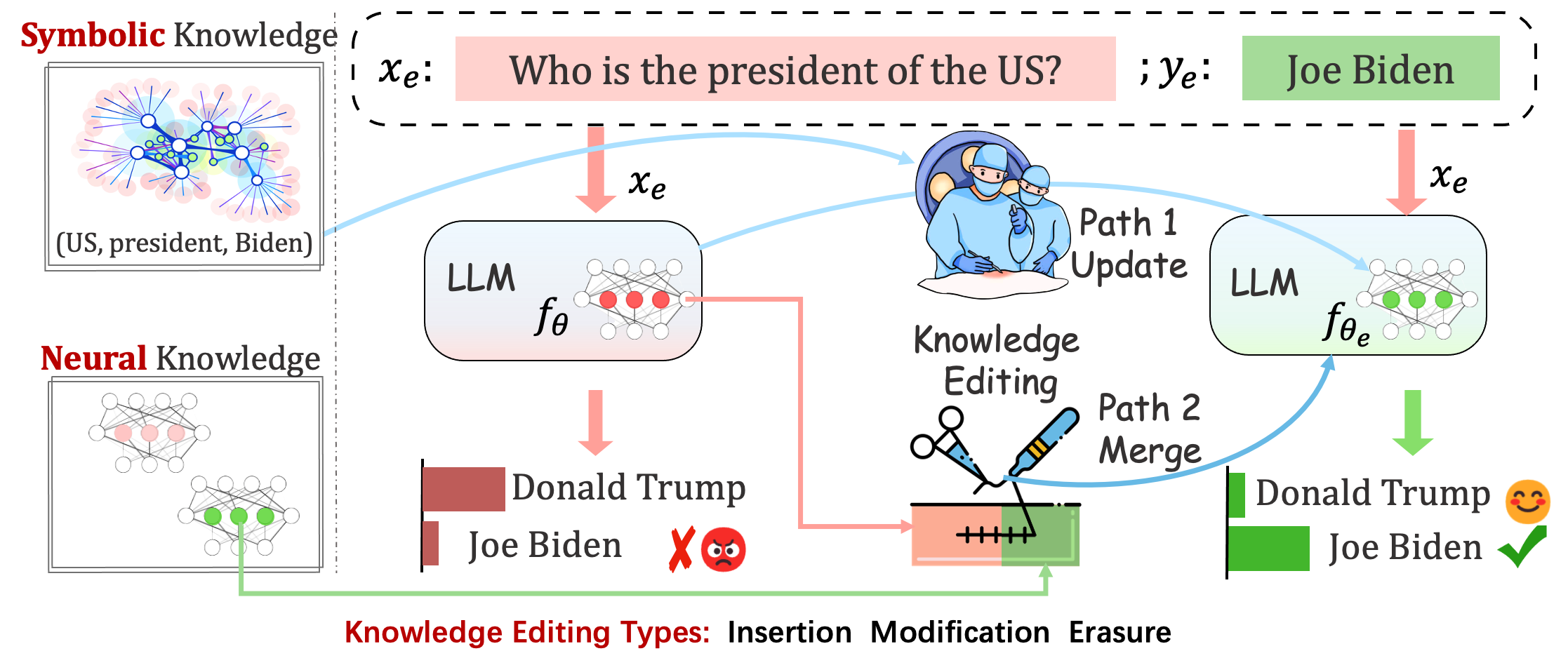
Os modelos implantados ainda podem cometer erros imprevisíveis. Por exemplo, os LLMs notoriamente alucinam , perpetuam preconceitos e decaem factualmente , portanto, deveríamos ser capazes de ajustar comportamentos específicos de modelos pré-treinados.
A edição de conhecimento visa ajustar o modelo base
Avaliando o desempenho do modelo após uma única edição. O modelo recarrega os pesos originais (por exemplo, LoRA descarta os pesos do adaptador) após uma única edição. Você deve definir sequential_edit=False
Isso requer edição sequencial e a avaliação é realizada após todas as atualizações de conhecimento terem sido aplicadas:
Faz ajustes de parâmetros para sequential_edit=True : README (para mais detalhes).
Sem influenciar o comportamento do modelo em amostras não relacionadas, o objetivo final é criar um modelo editado
Tarefa de edição para legenda de imagens e resposta visual a perguntas . LEIA-ME
A tarefa proposta assume a tentativa preliminar de editar as personalidades dos LLMs, editando suas opiniões sobre temas específicos, visto que as opiniões de um indivíduo podem refletir aspectos de seus traços de personalidade. Baseamo-nos na teoria BIG FIVE estabelecida como base para construir nosso conjunto de dados e avaliar as expressões de personalidade dos LLMs. LEIA-ME
Avaliação
Baseado em logits
Baseado em geração
Para avaliar Acc e TPEI , você pode baixar o classificador treinado aqui.
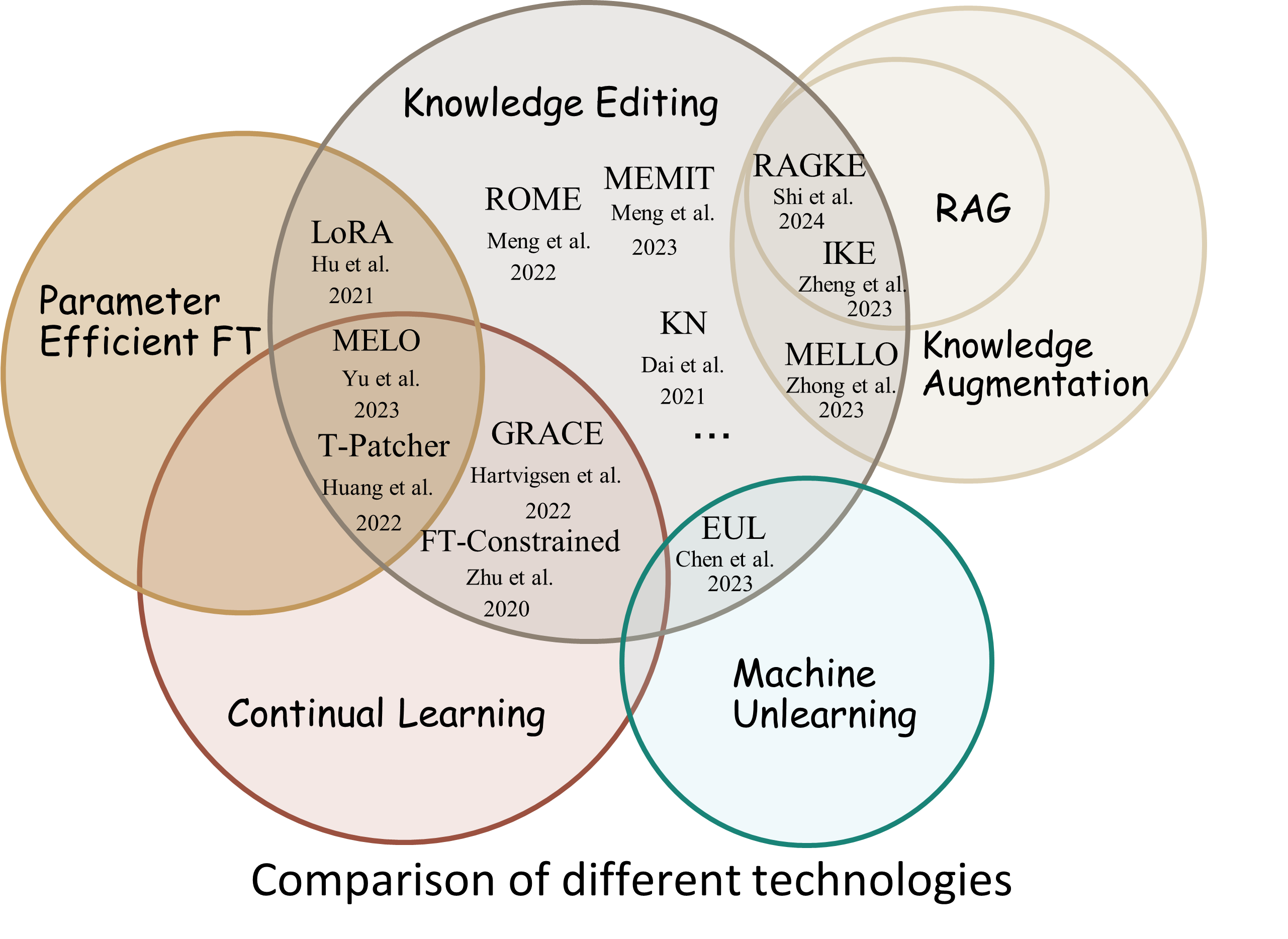
O processo de edição de conhecimento geralmente impacta as previsões para um amplo conjunto de entradas que estão intimamente associadas ao exemplo de edição, denominado escopo de edição .
Uma edição bem-sucedida deve ajustar o comportamento do modelo dentro do escopo de edição, mantendo entradas não relacionadas:
Reliability : a taxa de sucesso de edição com um determinado descritor de ediçãoGeneralization : a taxa de sucesso da edição dentro do escopo da ediçãoLocality : se a saída do modelo muda após a edição de entradas não relacionadasPortability : a taxa de sucesso de edição para raciocínio/aplicação (um salto, sinônimo, generalização lógica)Efficiency : consumo de tempo e memória EasyEdit é um pacote Python para edição de Large Language Models (LLM) como GPT-J , Llama , GPT-NEO , GPT2 , T5 (suporta modelos de 1B a 65B ), cujo objetivo é alterar o comportamento dos LLMs de forma eficiente dentro de um domínio específico sem impactar negativamente o desempenho de outras entradas. Ele foi projetado para ser fácil de usar e estender.
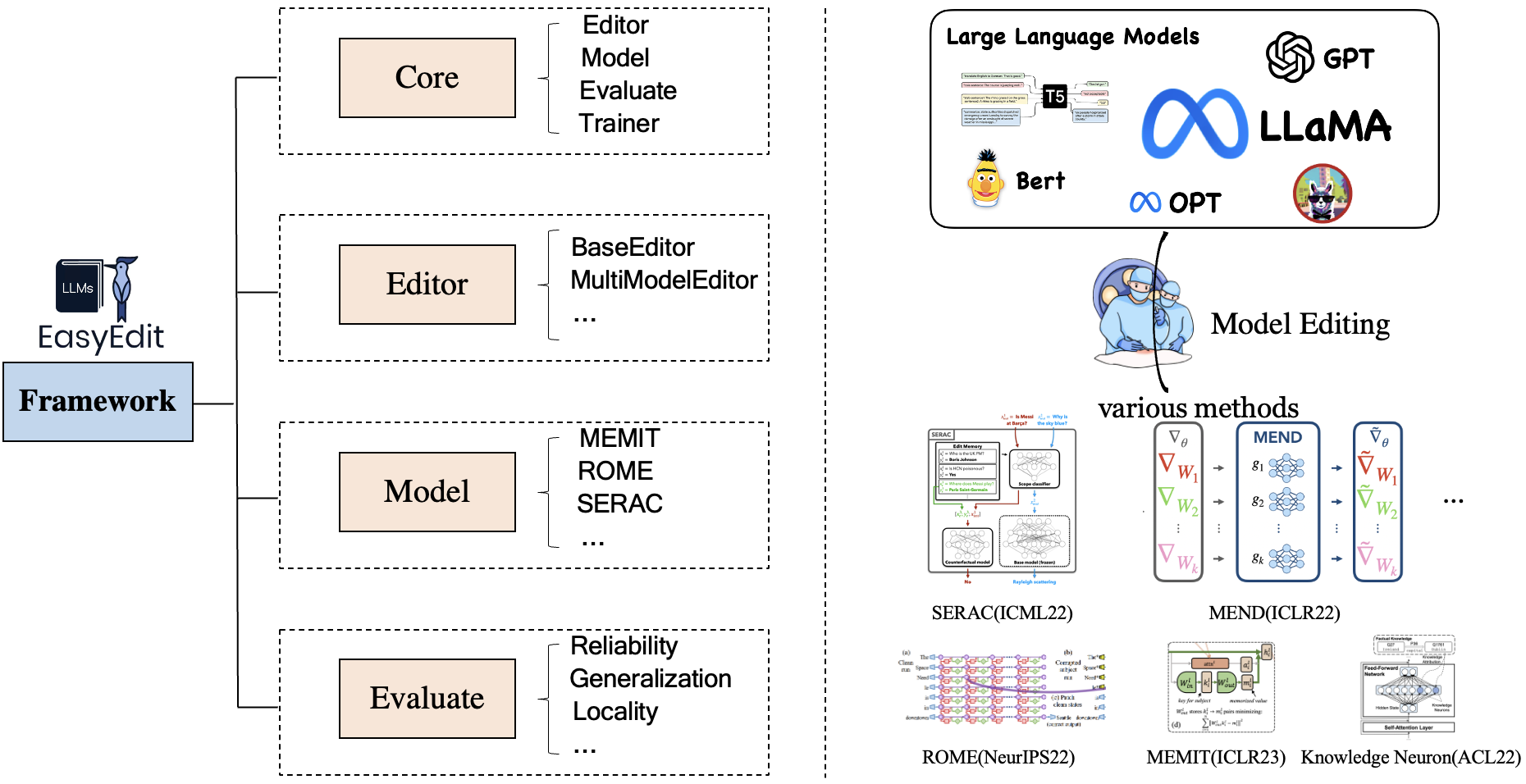
EasyEdit contém uma estrutura unificada para Editor , Method e Evaluate , representando respectivamente o cenário de edição, técnica de edição e método de avaliação.
Cada cenário de Edição de Conhecimento é composto por três componentes:
Editor : como BaseEditor (Editor de Conhecimento Factual e Geração ) para LM, MultiModalEditor ( Conhecimento MultiModal ).Method : a técnica específica de edição de conhecimento utilizada (como ROME , MEND , ..).Evaluate : Métricas para avaliar o desempenho da edição de conhecimento.Reliability , Generalization , Locality , PortabilityAs técnicas atuais de edição de conhecimento suportadas são as seguintes:
Nota 1: Devido à compatibilidade limitada deste kit de ferramentas, alguns métodos de edição de conhecimento, incluindo T-Patcher, KE, CaliNet, não são suportados.
Nota 2: Da mesma forma, o método MALMEN é apenas parcialmente apoiado pelas mesmas razões e continuará a ser melhorado.
Você pode escolher diferentes métodos de edição de acordo com suas necessidades específicas.
| Método | T5 | GPT-2 | GPT-J | GPT-NEO | Lhama | Baichuan | Bate-papoGLM | EstagiárioLM | Qwen | Mistral |
|---|---|---|---|---|---|---|---|---|---|---|
| TF | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| AdaLoRA | ✅ | ✅ | ||||||||
| SERAC | ✅ | ✅ | ✅ | ✅ | ||||||
| IKE | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| MENDAR | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| KN | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| ROMA | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| r-ROMA | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| MEMIT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| EMMET | ✅ | ✅ | ✅ | |||||||
| GRAÇA | ✅ | ✅ | ✅ | |||||||
| MELO | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| Instruir | ✅ | ✅ | ||||||||
| DINM | ✅ | ✅ | ✅ | |||||||
| SÁBIO | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| Alfa | ✅ | ✅ | ✅ |
❗️❗️ Se você pretende usar Mistral, atualize a biblioteca
transformerspara a versão 4.34.0 manualmente. Você pode usar o seguinte código:pip install transformers==4.34.0.
| Trabalhar | Descrição | Caminho |
|---|---|---|
| Instruir | InstructEdit: edição de conhecimento baseada em instruções para modelos de linguagem grande | Início rápido |
| DINM | Desintoxicando grandes modelos de linguagem por meio da edição de conhecimento | Início rápido |
| SÁBIO | WISE: Repensando a memória do conhecimento para a edição vitalícia de modelos de grandes linguagens | Início rápido |
| Conceito | Editando Conhecimento Conceitual para Grandes Modelos de Linguagem | Início rápido |
| MM | Podemos editar modelos multimodais de grandes linguagens? | Início rápido |
| Personalidade | Editando Personalidade para Modelos de Linguagem Grande | Início rápido |
| INCITAR | Métodos de edição de conhecimento baseados em PROMPT | Início rápido |
Referência: KnowEdit [Hugging Face][WiseModel][ModelScope]
❗️❗️ Deve-se observar que KnowEdit é construído reorganizando e estendendo conjuntos de dados existentes, incluindo WikiBio , ZsRE , WikiData Counterfact , WikiData Recent , convsent , Sanitation para fazer uma avaliação abrangente para edição de conhecimento. Agradecimentos especiais aos construtores e mantenedores desses conjuntos de dados.
Observe que Counterfact e WikiData Counterfact não são o mesmo conjunto de dados.
| Tarefa | Inserção de Conhecimento | Modificação do Conhecimento | Apagamento de Conhecimento | |||
|---|---|---|---|---|---|---|
| Conjuntos de dados | Wiki recente | ZsRE | WikiBio | Contrafato do WikiData | Consentimento | Saneamento |
| Tipo | Fato | Resposta a perguntas | Alucinação | Contrafato | Sentimento | Informações indesejadas |
| # Trem | 570 | 10.000 | 592 | 1.455 | 14.390 | 80 |
| # Teste | 1.266 | 1301 | 1.392 | 885 | 800 | 80 |
Fornecemos scripts detalhados para o usuário usar facilmente o KnowEdit, consulte exemplos.
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| conjunto de dados | Abraçando o rosto | Modelo Sábio | ModelScope | Descrição |
|---|---|---|---|---|
| CKnow | [Abraçando o rosto] | [Modelo Sábio] | [ModelEscopo] | conjunto de dados para edição do conhecimento chinês |
CKnowEdit é um conjunto de dados em chinês de alta qualidade para edição de conhecimento altamente caracterizado pelo idioma chinês, com todos os dados provenientes de bases de conhecimento chinesas. Ele é meticulosamente projetado para discernir mais profundamente as nuances e desafios inerentes à compreensão da língua chinesa pelos LLMs atuais, fornecendo um recurso robusto para refinar o conhecimento específico do chinês dentro dos LLMs.
As descrições dos campos para os dados no CKnowEdit são as seguintes:
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| conjunto de dados | Google Drive | BaiduNetDisk | Descrição |
|---|---|---|---|
| ZsRE mais | [Google Drive] | [BaiduNetDisk] | Conjunto de dados de resposta a perguntas usando reformulações de perguntas |
| Contrafato mais | [Google Drive] | [BaiduNetDisk] | Conjunto de dados contrafactual usando substituição de entidade |
Fornecemos conjuntos de dados zsre e counterfact para verificar a eficácia da edição de conhecimento. Você pode baixá-los aqui. [Google Drive], [BaiduNetDisk].
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse| conjunto de dados | Google Drive | Conjunto de dados HuggingFace | Descrição |
|---|---|---|---|
| Conceito | [Google Drive] | [Conjunto de dados HuggingFace] | conjunto de dados para edição de conhecimento conceitual |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
Métricas de avaliação específicas do conceito
Instance Change : capturando os meandros dessas mudanças no nível da instânciaConcept Consistency : a semelhança semântica da definição de conceito gerada | conjunto de dados | Google Drive | BaiduNetDisk | Descrição |
|---|---|---|---|
| E-IC | [Google Drive] | [BaiduNetDisk] | conjunto de dados para edição de legendas de imagens |
| E-VQA | [Google Drive] | [BaiduNetDisk] | conjunto de dados para edição de resposta visual a perguntas |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| conjunto de dados | Conjunto de dados HuggingFace | Descrição |
|---|---|---|
| Seguro | [Conjunto de dados HuggingFace] | conjunto de dados para desintoxicar LLMs |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
Desintoxicando Métricas de Avaliação Específicas
Defense Duccess (DS) : a taxa de sucesso de desintoxicação do LLM editado para entrada do adversário (prompt de ataque + pergunta prejudicial), que é usado para modificar o LLM.Defense Generalization (DG) : a taxa de sucesso de desintoxicação do LLM editado para entradas maliciosas fora do domínio.General Performance : os efeitos colaterais para o desempenho de tarefas não relacionadas. | Método | Descrição | GPT-2 | Lhama |
|---|---|---|---|
| IKE | Edição de aprendizagem em contexto (ICL) | [Colab-gpt2] | [Colab-lhama] |
| ROMA | Localize e edite neurônios | [Colab-gpt2] | [Colab-lhama] |
| MEMIT | Localize e edite neurônios | [Colab-gpt2] | [Colab-lhama] |
Nota: use Python 3.9+ para EasyEdit. Para começar, basta instalar o conda e executar:
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txtNossos resultados são todos baseados na configuração padrão
| lhama-2-7B | chatglm2 | gpt-j-6b | gpt-xl | |
|---|---|---|---|---|
| TF | 60 GB | 58 GB | 55 GB | 7GB |
| SERAC | 42 GB | 32 GB | 31 GB | 10 GB |
| IKE | 52 GB | 38 GB | 38 GB | 10 GB |
| MENDAR | 46 GB | 37 GB | 37 GB | 13 GB |
| KN | 42 GB | 39 GB | 40 GB | 12 GB |
| ROMA | 31 GB | 29 GB | 27 GB | 10 GB |
| MEMIT | 33 GB | 31 GB | 31 GB | 11 GB |
| AdaLoRA | 29 GB | 24 GB | 25 GB | 8GB |
| GRAÇA | 27 GB | 23 GB | 6 GB | |
| SÁBIO | 34 GB | 27 GB | 7GB |
Edite modelos de linguagem grandes (LLMs) em torno de 5 segundos
O exemplo a seguir mostra como realizar a edição com EasyEdit. Mais exemplos e tutoriais podem ser encontrados em exemplos
BaseEditoré a classe para edição de conhecimento de modalidade de linguagem. Você pode escolher o método de edição apropriado com base em suas necessidades específicas.
Com a modularidade e flexibilidade do EasyEdit , você pode usá-lo facilmente para editar o modelo.
Passo 1: Defina um PLM como o objeto a ser editado. Escolha o PLM a ser editado. EasyEdit suporta modelos parciais ( T5 , GPTJ , GPT-NEO , LlaMA até agora) recuperáveis no HuggingFace. O diretório do arquivo de configuração correspondente é hparams/YUOR_METHOD/YOUR_MODEL.YAML , como hparams/MEND/gpt2-xl.yaml , defina o model_name correspondente para selecionar o objeto para edição de conhecimento.
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editingEtapa 2: Escolha o método de edição de conhecimento apropriado
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )Etapa 3: forneça o descritor de edição e o destino de edição
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ] Passo 4: Combine-os em um BaseEditor EasyEdit fornece uma maneira simples e unificada de iniciar Editor , como huggingface: from_hparams .
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )Passo 5: Forneça os dados para avaliação Observe que os dados para portabilidade e localidade são opcionais (definido como Nenhum apenas para avaliação da taxa de sucesso de edição básica). O formato de dados para ambos é um dict , para cada dimensão de medição, você precisa fornecer o prompt correspondente e sua verdade básica correspondente. Aqui está um exemplo dos dados:
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}No exemplo acima, avaliamos o desempenho dos métodos de edição sobre “vizinhança” e “ditração”.
Etapa 6: Edição e avaliação concluídas! Podemos realizar edição e avaliação para que seu modelo seja editado. A função edit retornará uma série de métricas relacionadas ao processo de edição, bem como os pesos do modelo modificado. [ sequential_edit=True para edição contínua]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelO comprimento máximo de entrada para EasyEdit é 512. Se esse comprimento for excedido, você encontrará o erro "Erro CUDA: declaração do lado do dispositivo acionada". Você pode modificar o comprimento máximo no seguinte arquivo:LINK
Passo 7: RollBack Na edição sequencial, se você não estiver satisfeito com o resultado de uma de suas edições e não quiser perder as edições anteriores, você pode usar o recurso de rollback para desfazer a edição anterior. Atualmente, oferecemos suporte apenas ao método GRACE. Tudo que você precisa fazer é uma única linha de código, usando edit_key para reverter sua edição.
editor.rolllback('edit_key')
No EasyEdit, usamos como padrão target_new como edit_key
Especificamos as métricas de retorno como formato dict , incluindo avaliações de previsão do modelo antes e depois da edição. Para cada edição, incluirá as seguintes métricas:
rewrite_acc rephrase_acc locality portablility 

