YAYI2
1.0.0

[README] [?HF Repo] [?Versão web]
Chinês | Inglês
[2024.03.28] Todos os modelos e dados são carregados na Magic Community.
[2023.12.22] Lançamos o relatório técnico YAYI 2: Multilingual Open-Source Large Language Models.
YAYI 2 é uma nova geração de modelo de linguagem grande de código aberto desenvolvido por Zhongke Wenge, incluindo versões Base e Chat, com tamanho de parâmetro de 30B. YAYI2-30B é um grande modelo de linguagem baseado no Transformer, que usa corpus multilíngue de alta qualidade de mais de 2 trilhões de tokens para pré-treinamento. Para cenários de aplicação gerais e específicos de domínio, usamos milhões de instruções para ajuste fino e métodos de aprendizagem por reforço de feedback humano para alinhar melhor o modelo com os valores humanos.
O modelo de código aberto desta vez é o modelo YAYI2-30B Base. Esperamos promover o desenvolvimento da comunidade chinesa de código aberto de grandes modelos pré-treinados por meio do código aberto de grandes modelos Yayi e contribuir ativamente para isso. Através do código aberto, trabalhamos com todos os parceiros para construir o grande ecossistema de modelos Yayi.
Para obter mais detalhes técnicos, leia nosso relatório técnico YAYI 2: Multilingual Open-Source Large Language Models.
| Nome do conjunto de dados | tamanho | ?Identificação do modelo HF | Endereço de download | Logotipo do modelo mágico | Endereço de download |
|---|---|---|---|---|---|
| Dados de pré-treinamento YAYI2 | 500G | wengué-pesquisa/yayi2_pretrain_data | Download do conjunto de dados | wengué-pesquisa/yayi2_pretrain_data | Download do conjunto de dados |
| Nome do modelo | comprimento do contexto | ?Identificação do modelo HF | Endereço de download | Logotipo do modelo mágico | Endereço de download |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | pesquisa wengué/yayi2-30b | Baixar modelo | pesquisa wengué/yayi2-30b | Baixar modelo |
| YAYI2-30B-Bate-papo | 4096 | pesquisa wengué/yayi2-30b-chat | Em breve... |
Conduzimos avaliações em vários conjuntos de dados de referência, incluindo C-Eval, MMLU, CMMLU, AGIEval, GAOKAO-Bench, GSM8K, MATH, BBH, HumanEval e MBPP. Examinamos o desempenho do modelo na compreensão da linguagem, conhecimento do assunto, raciocínio matemático, raciocínio lógico e geração de código. O modelo YAYI 2 demonstra melhorias significativas de desempenho em relação a modelos de código aberto de tamanho semelhante.
| conhecimento do assunto | matemática | raciocínio lógico | código | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Modelo | C-Eval(val) | MMLU | AGIEval | CMMLU | Banco GAOKAO | GSM8K | MATEMÁTICA | BBH | Avaliação Humana | MBPP |
| 5 tiros | 5 tiros | Tiro 3/0 | 5 tiros | 0 tiro | 8/4 tiro | 4 tiros | 3 tiros | 0 tiro | 3 tiros | |
| MPT-30B | - | 46,9 | 33,8 | - | - | 15.2 | 3.1 | 38,0 | 25,0 | 32,8 |
| Falcão-40B | - | 55,4 | 37,0 | - | - | 19.6 | 5.5 | 37.1 | 0,6 | 29,8 |
| LLaMA2-34B | - | 62,6 | 43,4 | - | - | 42,2 | 6.2 | 44,1 | 22.6 | 33,0 |
| Baichuan2-13B | 59,0 | 59,5 | 37,4 | 61,3 | 45,6 | 52,6 | 10.1 | 49,0 | 17.1 | 30,8 |
| Qwen-14B | 71,7 | 67,9 | 51,9 | 70,2 | 62,5 | 61,6 | 25.2 | 53,7 | 32,3 | 39,8 |
| EstagiárioLM-20B | 58,8 | 62,1 | 44,6 | 59,0 | 45,5 | 52,6 | 7,9 | 52,5 | 25,6 | 35,6 |
| Aquila2-34B | 98,5 | 76,0 | 43,8 | 78,5 | 37,8 | 50,0 | 17,8 | 42,5 | 0,0 | 41,0 |
| Yi-34B | 81,8 | 76,3 | 56,5 | 82,6 | 68,3 | 67,6 | 15,9 | 66,4 | 26.2 | 38,2 |
| YAYI2-30B | 80,9 | 80,5 | 62,0 | 84,0 | 64,4 | 71,2 | 14,8 | 54,5 | 53.1 | 45,8 |
Conduzimos nossa avaliação usando o código-fonte fornecido pelo repositório OpenCompass Github. Para modelos de comparação, listamos seus resultados de avaliação na lista OpenCompass em 15 de dezembro de 2023. Para outros modelos que não participaram da avaliação na plataforma OpenCompass, incluindo MPT, Falcon e LLaMa 2, adotamos os resultados reportados pelo LLaMA 2.
Fornecemos exemplos simples para ilustrar como usar rapidamente YAYI2-30B para inferência. Este exemplo pode ser executado em um único A100/A800.
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envObserve que este projeto requer Python 3.8 ou superior.
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))Na primeira visita, o modelo precisa ser baixado e carregado, o que pode levar algum tempo.
Este projeto oferece suporte ao ajuste fino de instruções com base na estrutura de treinamento distribuída deepspeed Configure o ambiente e execute o script correspondente para iniciar o ajuste fino de parâmetros completos ou o ajuste fino de LoRA.
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps Formato de dados: consulte data/yayi_train_example.json , que é um arquivo JSON padrão. Cada dado consiste em "system" e "conversations" , onde "system" é a informação de configuração de função global e pode ser uma string vazia "conversations" . "conversations" são múltiplas rodadas de diálogo entre personagens humanos e yayi.
Instruções de operação: Execute o seguinte comando para iniciar o ajuste fino de parâmetros completos do modelo Yayi. Este comando suporta treinamento de várias máquinas e várias placas. Recomenda-se usar configuração de hardware 16*A100 (80G) ou superior.
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True Ou inicie via linha de comando:
bash scripts/start.sh Observe que se você precisar usar o modelo ChatML para ajuste fino de instruções, você pode alterar --module training.trainer_yayi2 no comando para --module training.trainer_chatml ; se precisar personalizar o modelo Chat, você pode modificar; o sistema no modelo de bate-papo de trainer_chatml.py Definições de token especiais para as três funções de, usuário e assistente. A seguir está um exemplo de modelo ChatML. Se esse modelo ou um modelo personalizado for usado durante o treinamento, ele também precisará ser consistente durante a inferência.
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh Na fase de pré-treinamento, não apenas usamos dados da Internet para treinar as capacidades linguísticas do modelo, mas também adicionamos dados gerais selecionados e dados de domínio para aprimorar as habilidades profissionais do modelo. A distribuição dos dados é a seguinte: 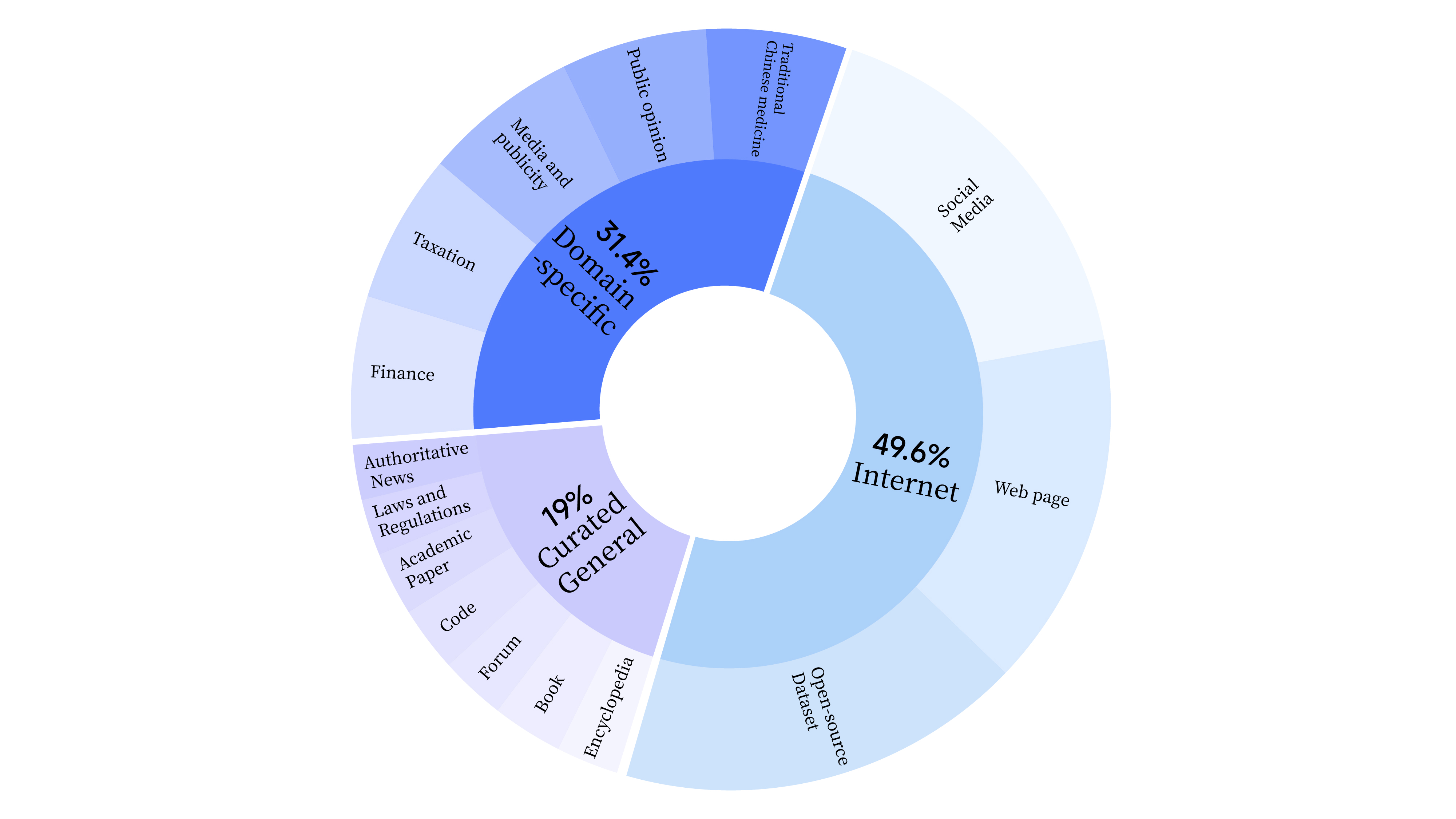
Construímos um conjunto de pipelines de processamento de dados para melhorar a qualidade dos dados em todos os aspectos, incluindo quatro módulos: padronização, limpeza heurística, desduplicação multinível e filtragem de toxicidade. Coletamos um total de 240 TB de dados brutos e apenas 10,6 TB de dados de alta qualidade permaneceram após o pré-processamento. O processo geral é o seguinte: 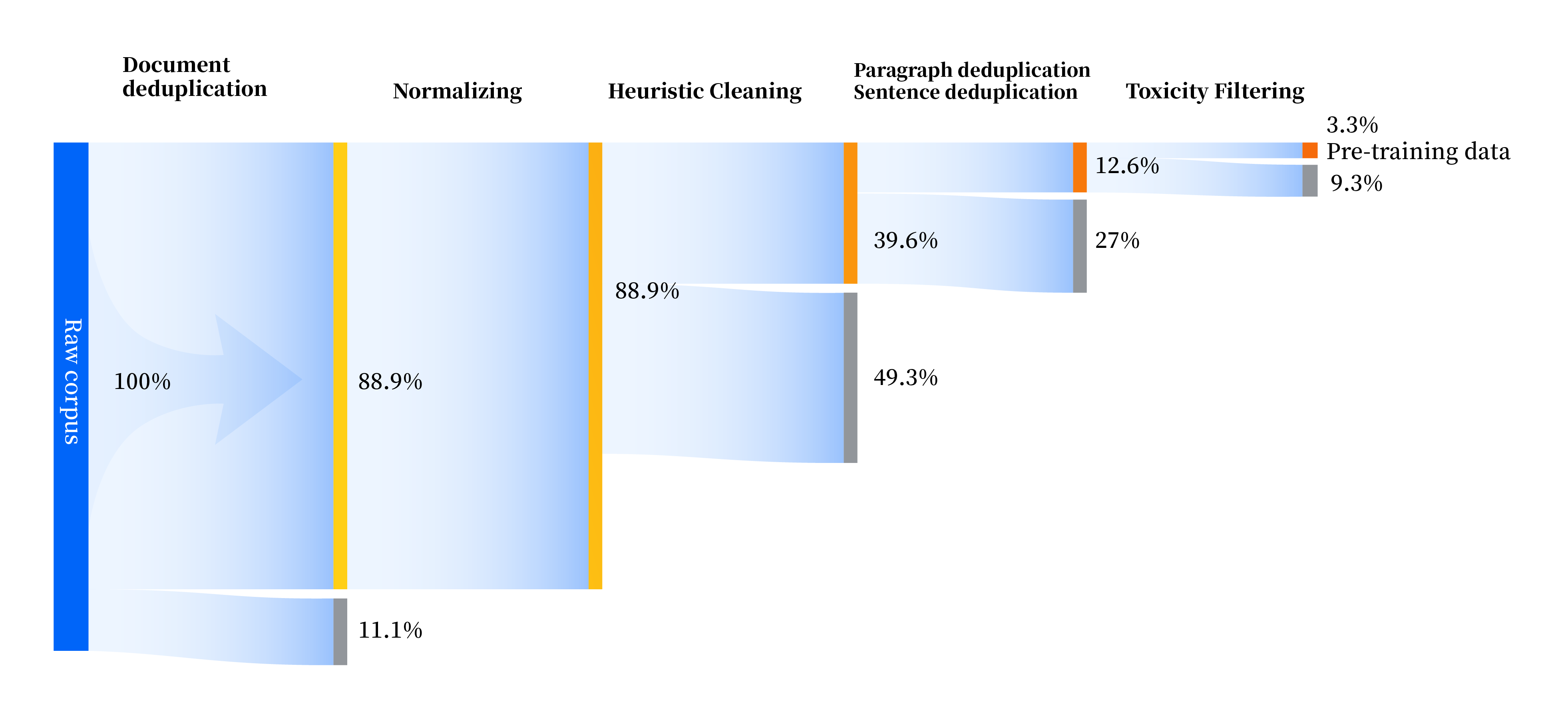

A curva de perdas do modelo YAYI 2 é mostrada na figura abaixo: 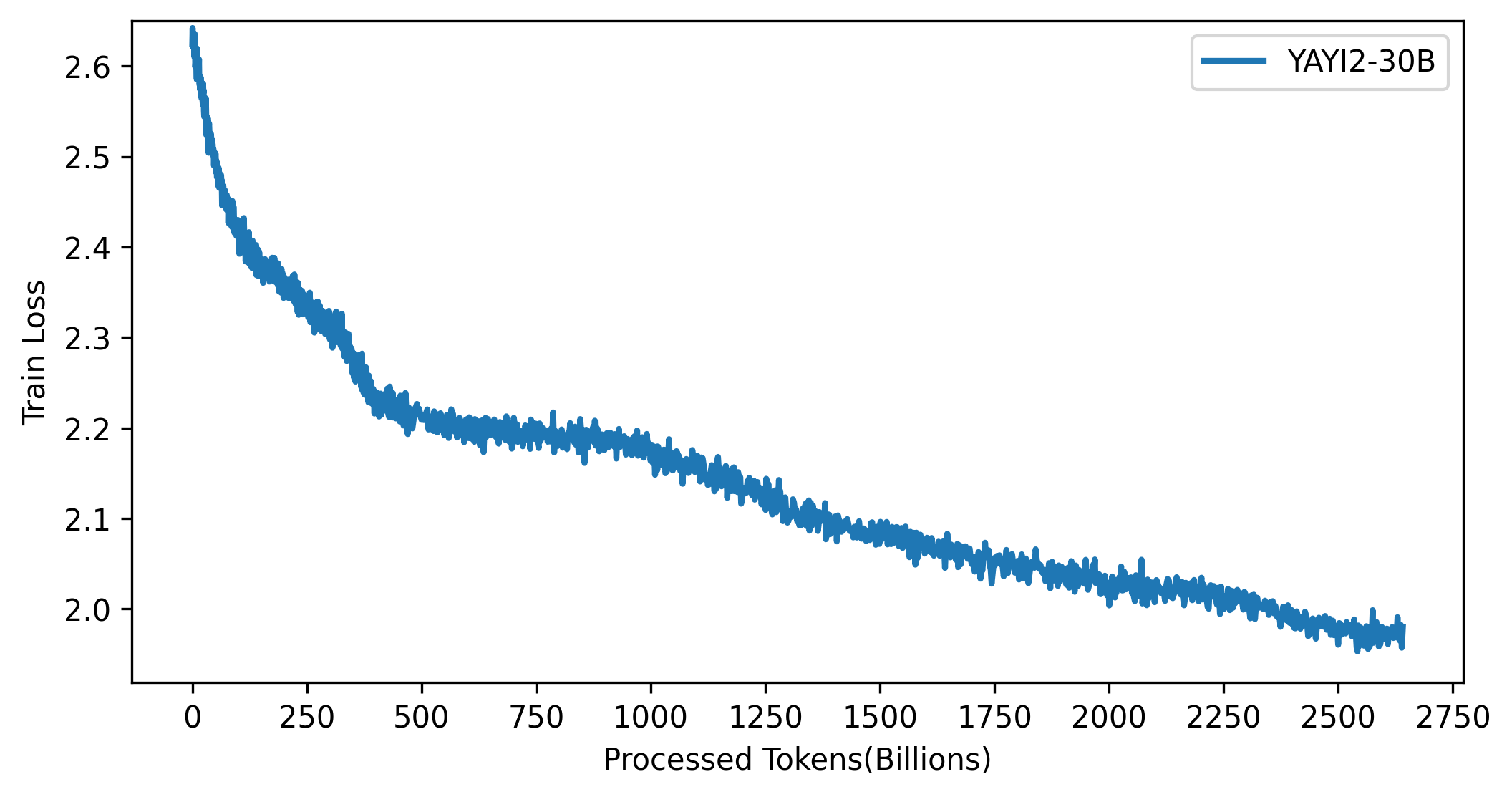
O código neste projeto é de código aberto de acordo com o protocolo Apache-2.0. O uso do modelo e dos dados YAYI 2 pela comunidade precisa estar em conformidade com o "Contrato de licença comunitária modelo Yayi YAYI 2". Se você precisar usar os modelos da série YAYI 2 ou seus derivados para fins comerciais, preencha as "Informações de registro comercial do modelo YAYI 2" e envie-as para [email protected]. Entraremos em contato dentro de 3 dias úteis após o recebimento do e-mail. . A revisão será realizada diariamente. Após aprovação na revisão, você receberá uma licença comercial. Cumpra rigorosamente o conteúdo relevante do "Contrato de Licença Comercial Modelo YAYI 2" durante o uso.
Se você usa nosso modelo em seu trabalho, cite nosso artigo:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


