ComfyUI N Nodes
1.0.0
Um conjunto de nós personalizados para ComfyUI que inclui nós de variáveis inteiras, de string e flutuantes, nós GPT e nós de vídeo.
Importante
Esses nós foram testados principalmente no Windows no ambiente padrão fornecido pelo ComfyUI e no ambiente criado pelo notebook para paperspace especificamente com a imagem docker cyberes/gradient-base-py3.10:latest. Qualquer outro ambiente não foi testado.
Clone o repositório: git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
para o diretório custom_nodes do ComfyUI
IMPORTANTE: Se você quiser os nós GPT na GPU, você precisará executar install_dependency bat files . Existem 2 versões: install_dependency_ggml_models.bat para os modelos ggmlv3 antigos e install_dependency_gguf_models.bat para todos os novos modelos (GGUF). VOCÊ SÓ PODE USAR UM DELES DE CADA VEZ! Como o llama-cpp-python precisa ser compilado a partir do código-fonte para permitir que ele use a GPU, primeiro você precisará ter o CUDA e o visual studio 2019 ou 2022 (no caso do meu bat) instalados para compilá-lo. Para detalhes e o guia completo você pode acessar AQUI.
Se você pretende usar GPTLoaderSimple com o modelo Moondream, você precisará executar o script 'install_extra.bat', que instalará os transformadores versão 4.36.2.
Reinicie o ComfyUI
Caso precise reverter essas alterações (devido à incompatibilidade com outros nós), você pode utilizar o script 'remove_extra.bat'.
O ComfyUI carregará automaticamente todos os scripts e nós personalizados na inicialização.
Observação
A instalação do llama-cpp-python será feita automaticamente pelo script. Se você tiver uma GPU NVIDIA NÃO É NECESSÁRIO MAIS CUDA BUILD graças ao repositório jllllll. Também abandonei o suporte para modelos GGMLv3, já que todos os modelos notáveis já deveriam ter mudado para a versão mais recente do GGUF.
Observação
Desde 14/02/2024, o nó passou por uma grande reescrita, o que também levou à mudança de todos os nomes dos nós para evitar conflitos com outras extensões no futuro (ou pelo menos assim espero). Consequentemente, os fluxos de trabalho antigos não são mais compatíveis e exigirão a substituição manual de cada nó. Para evitar isso, criei uma ferramenta que permite a substituição automática. No Windows, basta arrastar qualquer fluxo de trabalho *.json para o arquivo Migrate.bat localizado em (custom_nodes/ComfyUI-N-Nodes) e outro fluxo de trabalho com o sufixo _migrated será criado na mesma pasta do fluxo de trabalho atual. No Linux, você pode usar o script da seguinte maneira: python libs/migrate.py path/to/original/workflow/. Por motivos de segurança, o fluxo de trabalho original não será excluído." Para instalar a última versão deste repositório antes que esta seja alterada do Comfyui-N-Suite, execute git checkout 29b2e43baba81ee556b2930b0ca0a9c978c47083
ComfyUI-N-Nodes em custom_nodescomfyui-n-nodes em ComfyUIwebextensionsn-styles.csv e n-styles.csv.backup em ComfyUIstylesGPTcheckpoints em ComfyUImodelscustom_nodes/ComfyUI-N-Nodesgit pull
O nó LoadVideoAdvanced permite carregar um arquivo de vídeo e extrair quadros dele. O nome foi alterado de LoadVideo para LoadVideoAdvanced para evitar conflitos com o nó animado LoadVideo .
video : selecione o arquivo de vídeo a ser carregado.framerate : escolha se deseja manter a taxa de quadros original ou reduzir para metade ou um quarto da velocidade.resize_by : Selecione como redimensionar os quadros - 'none', 'height' ou 'width'.size : Tamanho alvo se for redimensionado por altura ou largura.images_limit : Limite o número de quadros a serem extraídos.batch_size : Tamanho do lote para codificação de quadros.starting_frame : selecione de qual quadro começar.autoplay : selecione se deseja reproduzir automaticamente o vídeo.use_ram : Use RAM em vez de disco para descompactar quadros de vídeo. IMAGES : Imagens de quadros extraídas como tensores PyTorch.LATENT : Vetores latentes vazios.METADATA : Metadados de vídeo - FPS e número de frames.WIDTH: Largura do quadro.HEIGHT : Altura do quadro.META_FPS : Taxa de quadros.META_N_FRAMES : Número de quadros.O nó extrai quadros do vídeo de entrada na taxa de quadros especificada. Ele redimensiona os quadros, se escolhido, e os retorna como lotes de tensores de imagem PyTorch junto com vetores latentes, metadados e dimensões do quadro.
O nó SaveVideo coleta quadros extraídos e os salva como um arquivo de vídeo. 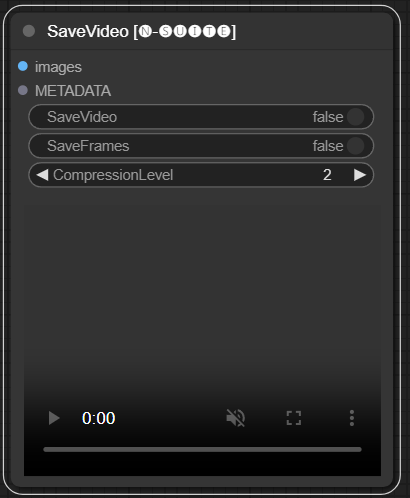
images : Enquadrar imagens como tensores.METADATA : Metadados do nó LoadVideo.SaveVideo : alterna para salvar o arquivo de vídeo de saída.SaveFrames : alterna para salvar quadros em uma pasta.CompressionLevel : nível de compactação PNG para salvar quadros. Salva o arquivo de vídeo de saída e/ou quadros extraídos.
O nó extrai quadros e metadados e pode salvá-los como um novo arquivo de vídeo e/ou imagens de quadros individuais. A compactação de vídeo e a compactação de quadro PNG podem ser configuradas. NOTA: Se você estiver usando LoadVideo como fonte dos frames, o áudio do arquivo original será mantido, mas apenas caso images_limit e startup_frame sejam iguais a Zero.
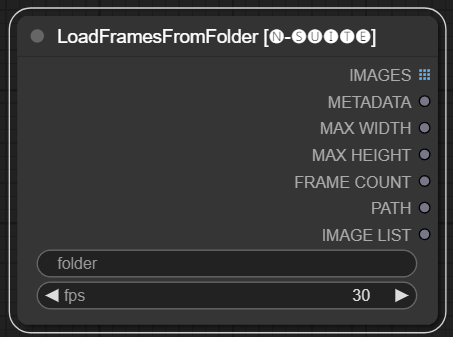
O nó LoadFramesFromFolder permite carregar quadros de imagem de uma pasta e retorná-los em lote.
folder : Caminho para a pasta que contém as imagens do quadro. Deve estar no formato png, nomeado com um número (por exemplo, 1.png ou mesmo 0001.png). As imagens serão carregadas sequencialmente.fps : Quadros por segundo para atribuir aos quadros carregados. IMAGES : lote de imagens de quadros carregados como tensores PyTorch.METADATA : Metadados contendo o valor FPS definido.MAX_WIDTH : Largura máxima do quadro.MAX_HEIGHT : Altura máxima do quadro.FRAME COUNT : Número de frames na pasta.PATH : Caminho para a pasta que contém as imagens do quadro.IMAGE LIST : Lista de imagens de quadros na pasta (não uma lista real, apenas uma string dividida por n).O nó carrega todos os arquivos de imagem da pasta especificada, converte-os em tensores PyTorch e os retorna como um tensor em lote junto com metadados simples contendo o valor FPS definido.
Isto permite carregar facilmente um conjunto de frames que foram extraídos e salvos anteriormente, por exemplo, para recarregá-los e processá-los novamente. Ao definir o valor FPS, os quadros podem ser interpretados adequadamente como uma sequência de vídeo.
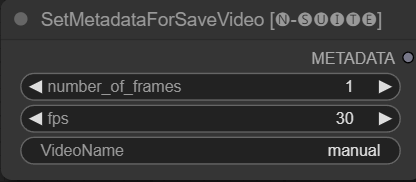
O nó SetMetadataForSaveVideo permite configurar metadados para o nó SaveVideo.
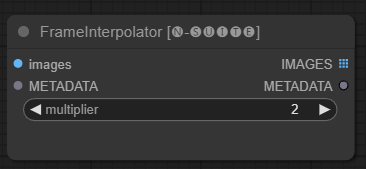
O nó FrameInterpolator permite a interpolação entre quadros de vídeo extraídos para aumentar a taxa de quadros e suavizar o movimento.
images : imagens de quadro extraídas como tensores.METADATA : Metadados do vídeo - FPS e número de frames.multiplier : Fator pelo qual aumentar a taxa de quadros. IMAGES : Quadros interpolados como tensores de imagem.METADATA : Metadados atualizados com nova taxa de quadros.O nó recebe quadros e metadados extraídos como entrada. Ele usa um modelo de interpolação (RIFE) para gerar quadros intermediários adicionais a uma taxa de quadros mais alta.
A taxa de quadros original nos metadados é multiplicada pelo valor multiplier para obter a nova taxa de quadros interpolada.
Os quadros interpolados são retornados como um lote de tensores de imagem, juntamente com metadados atualizados contendo a nova taxa de quadros.
Isso permite aumentar a taxa de quadros de um vídeo existente para obter movimentos mais suaves e uma reprodução mais lenta. O modelo de interpolação cria novos quadros realistas para preencher as lacunas, em vez de apenas duplicar os quadros existentes.
O código original foi retirado AQUI
Como o nó primitivo tem limitações em links (por exemplo, no momento em que escrevo, você não pode vincular "start_at_step" e "steps" de outro ksampler), decidi criar essas variáveis de nó simples para contornar essa limitação. variáveis são:
Esses nós personalizados são projetados para aprimorar os recursos da estrutura ConfyUI, permitindo a geração de texto usando modelos GGUF GPT. Este README fornece uma visão geral dos dois nós personalizados e seu uso no ConfyUI.
Você pode adicionar no extra_model_paths.yaml o caminho onde seu modelo GGUF está desta forma (exemplo):
other_ui: base_path: I:\text-generation-webui GPTcheckpoints: models/
Caso contrário, ele criará uma pasta GPTcheckpoints na pasta de modelos do ComfyUI, onde você poderá colocar seus modelos .gguf.
Duas pastas também foram criadas dentro do diretório 'Llava' na pasta 'GPTcheckpoints' para o modelo LLava:
clips : Esta pasta é designada para armazenar os clipes dos seus modelos LLava (geralmente, arquivos que começam com mm no repositório). models : Esta pasta é designada para armazenar os modelos LLava.
Na verdade, esses nós suportam 4 modelos diferentes:
Os modelos GGUF podem ser baixados do Huggingface Hub
AQUI um vídeo de exemplo de utilização dos modelos GGUF de boricuapab
Aqui está uma pequena lista dos modelos suportados por estes nós:
LlaVa 1.5 7B LlaVa 1.5 13B LlaVa 1.6 Mistral 7B BakLLaVa Nous Hermes 2 Visão
####Exemplo com modelo Llava: 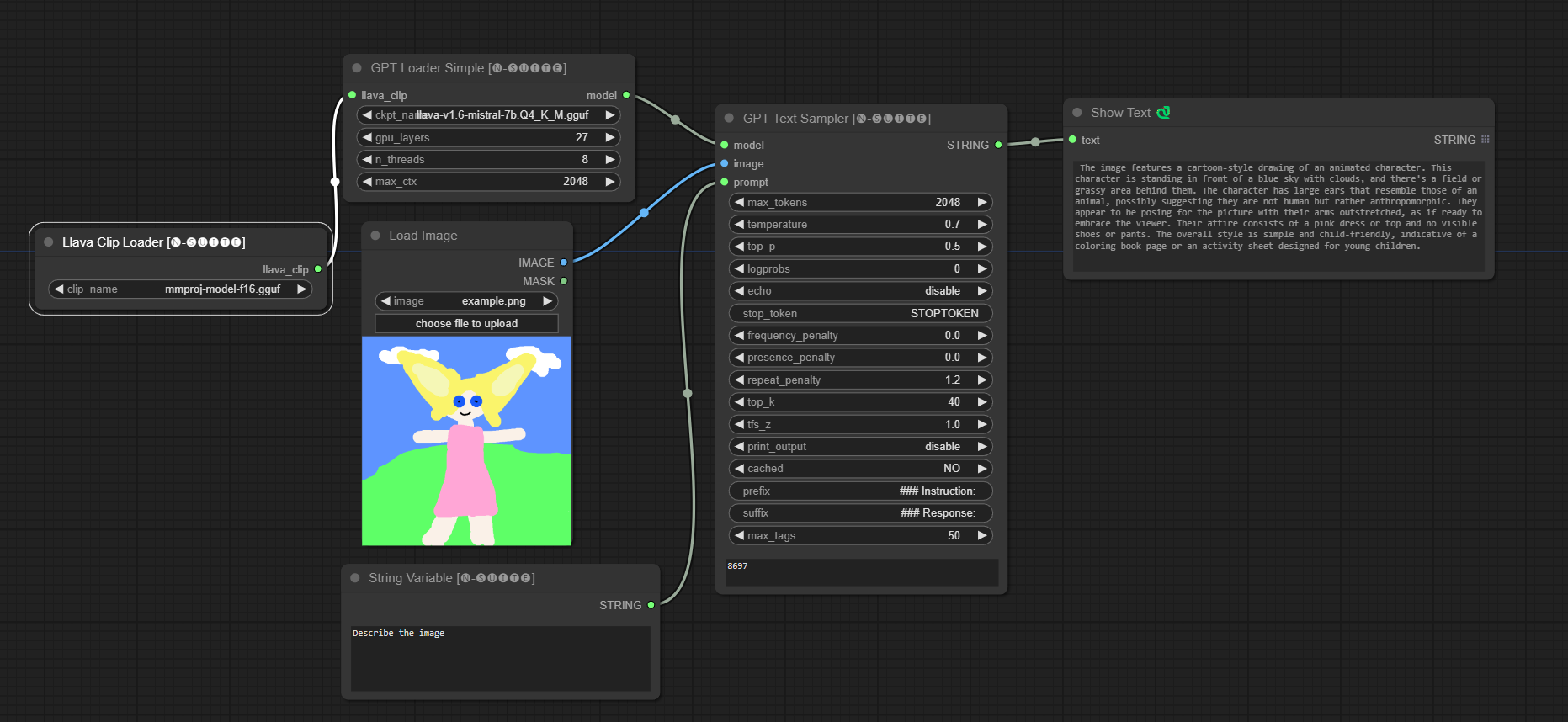
O modelo será baixado automaticamente quando você executar pela primeira vez. De qualquer forma, está disponível AQUI O código retirado deste repositório
####Exemplo com modelo Moondream: 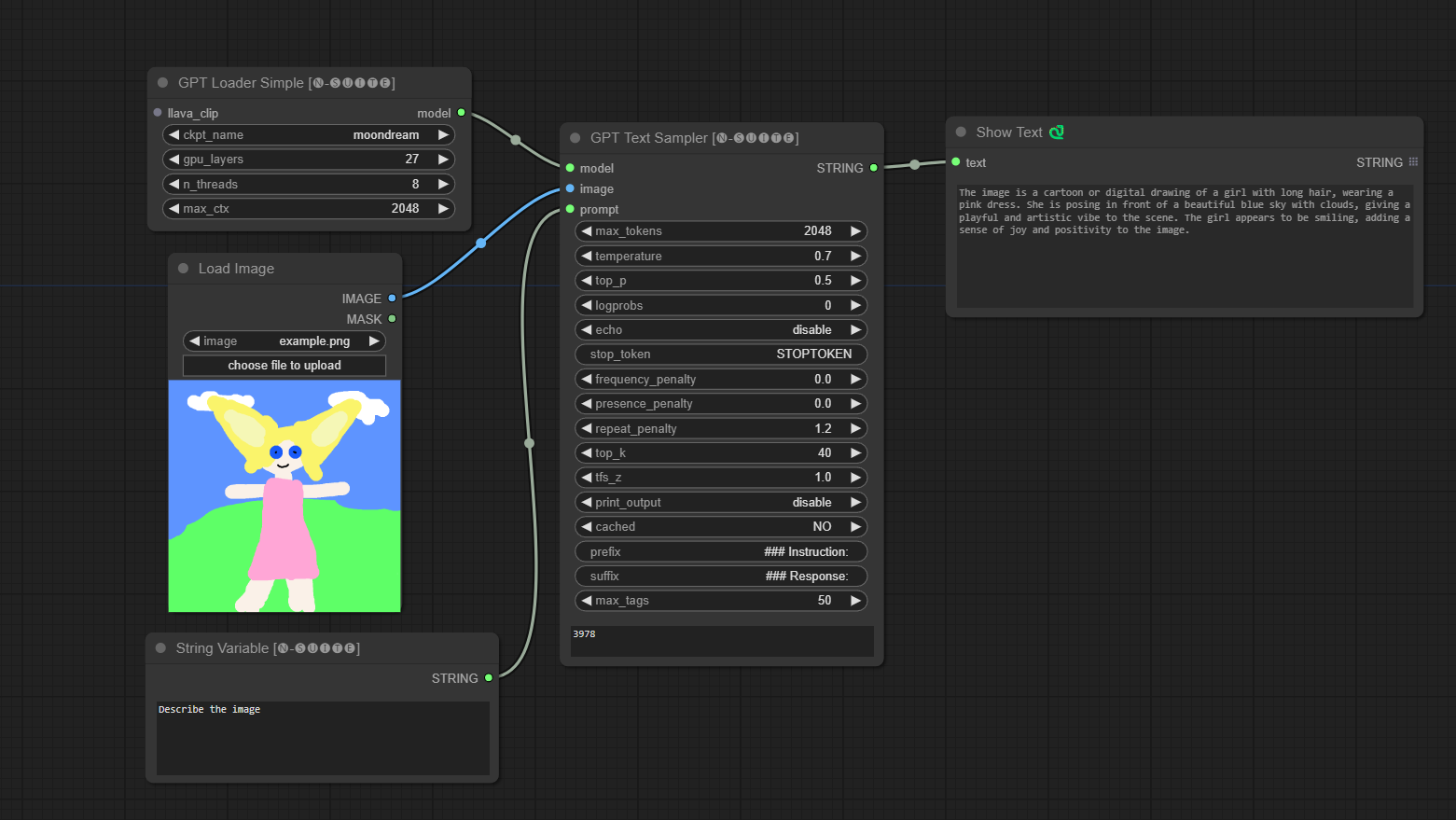
O modelo será baixado automaticamente quando você executar pela primeira vez. De qualquer forma, está disponível AQUI O código retirado deste repositório
####Exemplo com modelo Joytag: 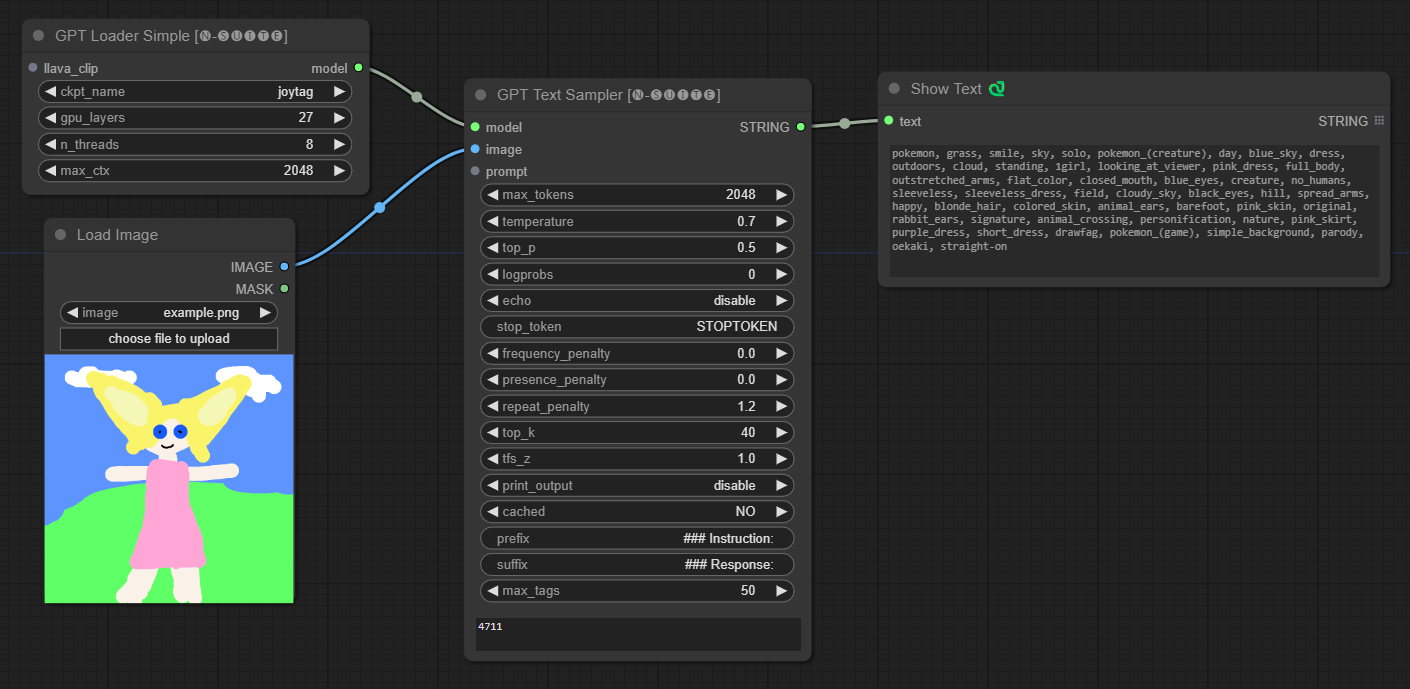
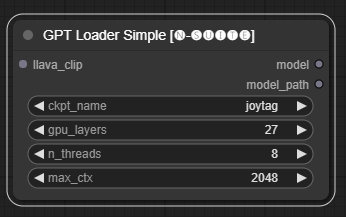
O nó GPTLoaderSimple é responsável por carregar os pontos de verificação do modelo GPT e criar uma instância da biblioteca Llama para geração de texto. Ele fornece uma interface para configurar as camadas da GPU, o número de threads e o contexto máximo para geração de texto.
ckpt_name : Selecione o nome do ponto de verificação GPT entre as opções disponíveis (joytag e moondream serão baixados automaticamente na primeira vez).gpu_layers : Especifique o número de camadas GPU a serem usadas (padrão: 27).n_threads : Especifique o número de threads para geração de texto (padrão: 8).max_ctx : Especifique o comprimento máximo do contexto para geração de texto (padrão: 2048). O nó retorna uma instância da biblioteca Llama (MODEL) e o caminho para o checkpoint carregado (STRING).
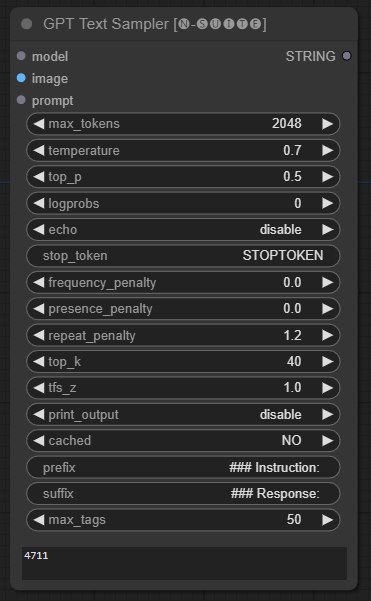
O nó GPTSampler facilita a geração de texto usando modelos GPT baseados no prompt de entrada e em vários parâmetros de geração. Ele permite que você controle aspectos como temperatura, amostragem top-p, penalidades e muito mais.
prompt : insira o prompt de entrada para geração de texto.image : Entrada de imagem para modelos Joytag, moondream e llava.model : escolha o modelo GPT a ser usado para geração de texto.max_tokens : Defina o número máximo de tokens no texto gerado (padrão: 128).temperature : Defina o parâmetro de temperatura para aleatoriedade (padrão: 0,7).top_p : Defina a probabilidade p superior para amostragem de núcleo (padrão: 0,5).logprobs : Especifique o número de probabilidades de log a serem geradas (padrão: 0).echo : habilita ou desabilita a impressão do prompt de entrada junto com o texto gerado.stop_token : Especifique o token no qual a geração de texto é interrompida.frequency_penalty , presence_penalty , repeat_penalty : Penalidades de geração de palavras de controle.top_k : Defina os k principais tokens a serem considerados durante a geração (padrão: 40).tfs_z : Defina o fator de escala de temperatura para amostras mais frequentes (padrão: 1,0).print_output : habilita ou desabilita a impressão do texto gerado no console.cached : escolha se deseja usar a geração em cache (padrão: NO).prefix , suffix : Especifique o texto a ser prefixado e anexado ao prompt.max_tags : afeta apenas o número máximo de tags geradas pelo joydag. O nó retorna o texto gerado junto com uma representação amigável à UI.
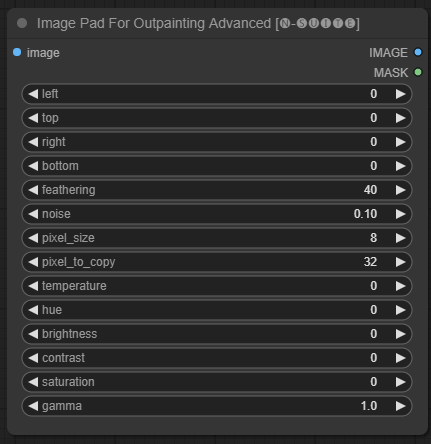
O nó ImagePadForOutpaintingAdvanced é uma alternativa ao nó ImagePadForOutpainting que aplica a técnica vista neste vídeo sob a máscara outpainting. A parte de correção de cores foi retirada deste nó personalizado do Sipherxyz
image : entrada de imagem.left : pixel para estender da esquerda,top : pixel para estender do topo,right : pixel para estender da direita,bottom : pixel para estender da parte inferior.feathering : força de enevoamentonoise : combina a força do ruído e da borda copiadapixel_size : quão grande será o pixel no efeito pixeladopixel_to_copy : quantos pixels copiar (de cada lado)temperature : configuração de correção de cor aplicada apenas à parte da máscara.hue : configuração de correção de cor aplicada apenas à parte da máscara.brightness : configuração de correção de cor aplicada apenas à parte da máscara.contrast : configuração de correção de cor aplicada apenas à parte da máscara.saturation : configuração de correção de cor aplicada apenas à parte da máscara.gamma : configuração de correção de cores aplicada apenas à parte da máscara. O nó retorna a imagem processada e a máscara.

O nó DynamicPrompt gera prompts combinando um prompt fixo com uma seleção aleatória de tags de um prompt variável. Isso permite a geração de prompts flexíveis e dinâmicos para vários casos de uso.
variable_prompt : insira o prompt da variável para seleção de tag.cached : escolha se deseja armazenar em cache o prompt gerado (padrão: NO).number_of_random_tag : Escolha entre "Fixo" e "Aleatório" para o número de tags aleatórias a serem incluídas.fixed_number_of_random_tag : If number_of_random_tag if "Fixed" Especifique o número de tags aleatórias a serem incluídas (padrão: 1).fixed_prompt (opcional): insira o prompt fixo para gerar o prompt final. O nó retorna o prompt gerado, que é uma combinação do prompt fixo e tags aleatórias selecionadas.
variable_prompt com a tag separada por vírgula, o fixed_prompt é opcional 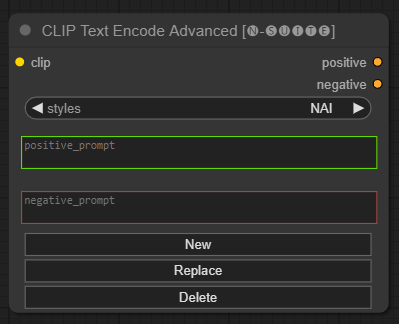
O nó CLIP Text Encode Advanced é uma alternativa ao nó CLIP Text Encode padrão. Ele oferece suporte para estilos Adicionar/Substituir/Excluir, permitindo a inclusão de prompts positivos e negativos em um único nó.
O arquivo de estilo base é chamado n-styles.csv e está localizado na pasta ComfyUIstyles . O arquivo de estilos segue o mesmo formato do arquivo styles.csv atual utilizado no A1111 (no momento da escrita).
NOTA: esta nota é experimental e ainda contém muitos bugs
clip : entrada de clipestyle : preencherá automaticamente os prompts positivos e negativos com base no estilo escolhido positive : condições positivasnegative : condições negativas Sinta-se à vontade para contribuir com este projeto relatando problemas ou sugerindo melhorias. Abra um problema ou envie uma solicitação pull no repositório GitHub.
Este projeto está licenciado sob a licença MIT. Consulte o arquivo LICENSE para obter detalhes.


