Copulas
v0.12.0 - 2024-11-12
Este repositório faz parte do The Synthetic Data Vault Project, um projeto da DataCebo.

Copulas é uma biblioteca Python para modelagem de distribuições multivariadas e amostragem delas usando funções de cópula. Dada uma tabela de dados numéricos, use Cópulas para aprender a distribuição e gerar novos dados sintéticos seguindo as mesmas propriedades estatísticas.
Principais recursos:
Modele dados multivariados. Escolha entre uma variedade de distribuições e cópulas univariadas – incluindo Cópulas Arquimedianas, Cópulas Gaussianas e Cópulas Vine.
Compare visualmente dados reais e sintéticos após construir seu modelo. As visualizações estão disponíveis como histogramas 1D, gráficos de dispersão 2D e gráficos de dispersão 3D.
Acesse e manipule parâmetros aprendidos. Com acesso completo às partes internas do modelo, defina ou ajuste os parâmetros de sua escolha.
Instale a biblioteca Copulas usando pip ou conda.
pip install copulasconda install -c conda-forge copulasComece a usar um conjunto de dados de demonstração. Este conjunto de dados contém 3 colunas numéricas.
from copulas . datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz ()
real_data . head ()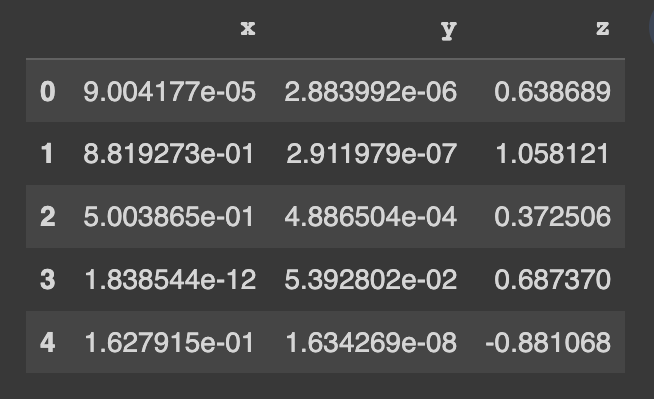
Modele os dados usando uma cópula e use-a para criar dados sintéticos. A biblioteca Copulas oferece muitas opções, incluindo Cópulas Gaussianas, Cópulas Vine e Cópulas Arquimedianas.
from copulas . multivariate import GaussianMultivariate
copula = GaussianMultivariate ()
copula . fit ( real_data )
synthetic_data = copula . sample ( len ( real_data ))Visualize os dados reais e sintéticos lado a lado. Vamos fazer isso em 3D, então veja nosso conjunto de dados completo.
from copulas . visualization import compare_3d
compare_3d ( real_data , synthetic_data )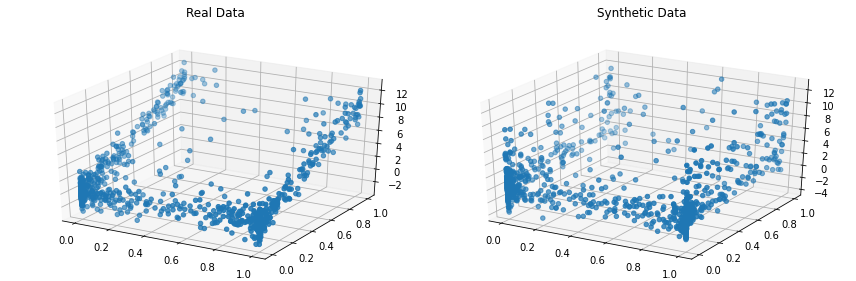
Clique abaixo para executar o código em um Notebook Colab e descobrir novos recursos.
Saiba mais sobre a biblioteca Copulas em nosso site de documentação.
Perguntas ou problemas? Junte-se ao nosso canal no Slack para discutir mais sobre cópulas e dados sintéticos. Se você encontrar um bug ou tiver uma solicitação de recurso, também poderá abrir um problema em nosso GitHub.
Interessado em contribuir para Copulas? Leia nosso Guia de Contribuição para começar.
O projeto de código aberto Copulas começou no Data to AI Lab do MIT em 2018. Obrigado à nossa equipe de colaboradores que construíram e mantiveram a biblioteca ao longo dos anos!
Ver colaboradores

O Projeto Synthetic Data Vault foi criado pela primeira vez no Data to AI Lab do MIT em 2016. Após 4 anos de pesquisa e tração com empresas, criamos o DataCebo em 2020 com o objetivo de expandir o projeto. Hoje, DataCebo é o orgulhoso desenvolvedor do SDV, o maior ecossistema para geração e avaliação de dados sintéticos. É o lar de várias bibliotecas que oferecem suporte a dados sintéticos, incluindo:
Comece a usar o pacote SDV – uma solução totalmente integrada e seu balcão único para dados sintéticos. Ou use as bibliotecas independentes para necessidades específicas.


