SimplyRetrieve
Dependencies Update
? Notícias : 21 de agosto de 2023 – Os usuários agora podem criar e anexar conhecimento dinamicamente por meio da Knowledge Tab recém-adicionada na GUI. Além disso, barras de progresso adicionadas nas guias Configuração e Conhecimento.
SimplyRetrieve é uma ferramenta de código aberto com o objetivo de fornecer uma plataforma GUI e API totalmente localizada, leve e fácil de usar para abordagem de geração centrada em recuperação (RCG) para a comunidade de aprendizado de máquina.
Crie uma ferramenta de chat com seus documentos e modelos de linguagem, altamente customizável. Os recursos são:
Um relatório técnico sobre esta ferramenta está disponível em arXiv.
Um pequeno vídeo sobre esta ferramenta está disponível no YouTube.
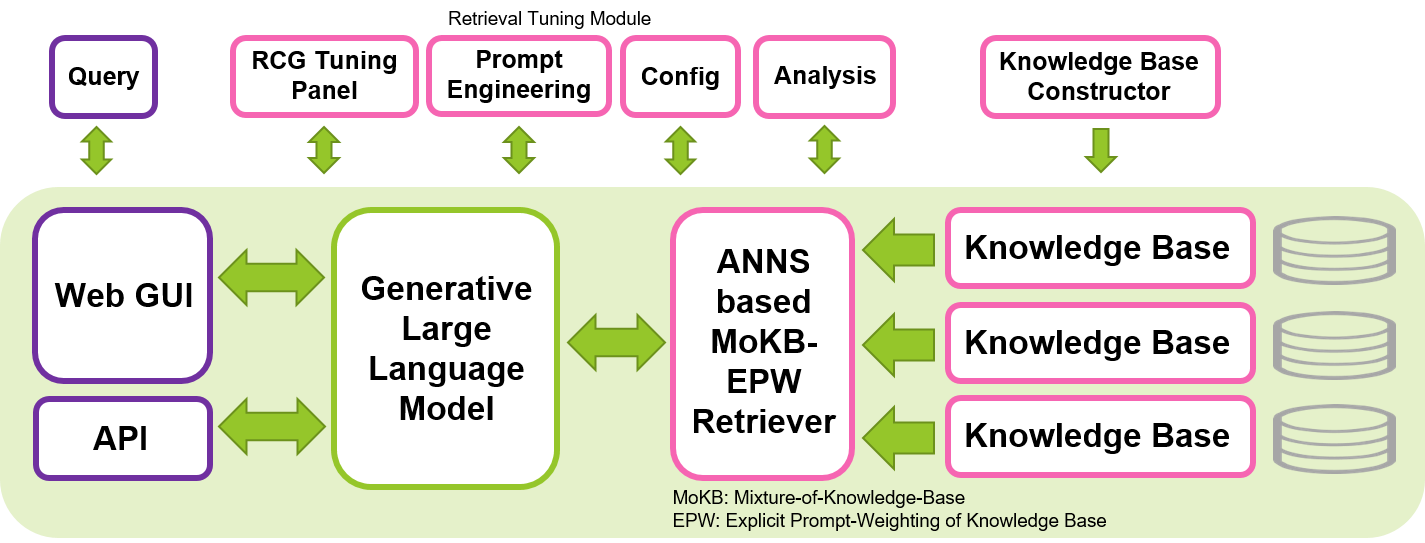
Nosso objetivo é contribuir para o desenvolvimento de LLMs seguros, interpretáveis e responsáveis, compartilhando nossa ferramenta de código aberto para implementar a abordagem RCG. Esperamos que esta ferramenta permita que a comunidade de aprendizado de máquina explore o uso de LLMs de uma forma mais eficiente, mantendo a privacidade e a implementação local. A Geração Centrada na Recuperação, que se baseia no conceito de Geração Aumentada na Recuperação (RAG), enfatizando o papel crucial dos LLMs na interpretação do contexto e confiando a memorização do conhecimento ao componente recuperador, tem o potencial de produzir uma geração mais eficiente e interpretável, e reduzir a escala de LLMs necessários para tarefas generativas. Esta ferramenta pode ser executada em uma única GPU Nvidia, como T4, V100 ou A100, tornando-a acessível a uma ampla gama de usuários.
Esta ferramenta é construída com base principalmente nas incríveis e familiares bibliotecas de Hugging Face, Gradio, PyTorch e Faiss. O LLM padrão configurado nesta ferramenta é o Wizard-Vicuna-13B-Uncensored com ajuste fino de instruções. O modelo de incorporação padrão para o retriever é multilingual-e5-base. Descobrimos que esses modelos funcionam bem neste sistema, bem como em muitos outros tamanhos de LLMs e recuperadores de código aberto disponíveis no Hugging Face. Esta ferramenta pode ser executada em outros idiomas além do inglês, selecionando LLMs apropriados e personalizando modelos de prompt de acordo com o idioma de destino.
pip install -r requirements.txtchat/data/ e execute o script de preparação de dados ( cd chat/ então o seguinte comando) CUDA_VISIBLE_DEVICES=0 python prepare.py --input data/ --output knowledge/ --config configs/default_release.json
pdf, txt, doc, docx, ppt, pptx, html, md, csv e podem ser facilmente expandidos editando o arquivo de configuração. Siga as dicas sobre esse problema se ocorrer um erro relacionado ao NLTK.Knowledge Tab da ferramenta GUI. Os usuários agora podem adicionar conhecimento dinamicamente. Executar o script prepare.py acima antes de executar a ferramenta não é uma necessidade. Após configurar os pré-requisitos acima, defina o caminho atual para o diretório chat ( cd chat/ ), execute o comando abaixo. Então grab a coffee! pois levará apenas alguns minutos para carregar.
CUDA_VISIBLE_DEVICES=0 python chat.py --config configs/default_release.json
Em seguida, acesse a GUI baseada na Web em seu navegador favorito navegando até http://<LOCAL_SERVER_IP>:7860 . Substitua <LOCAL_SERVER_IP> pelo endereço IP do seu servidor GPU. E é isso, você está pronto para começar!
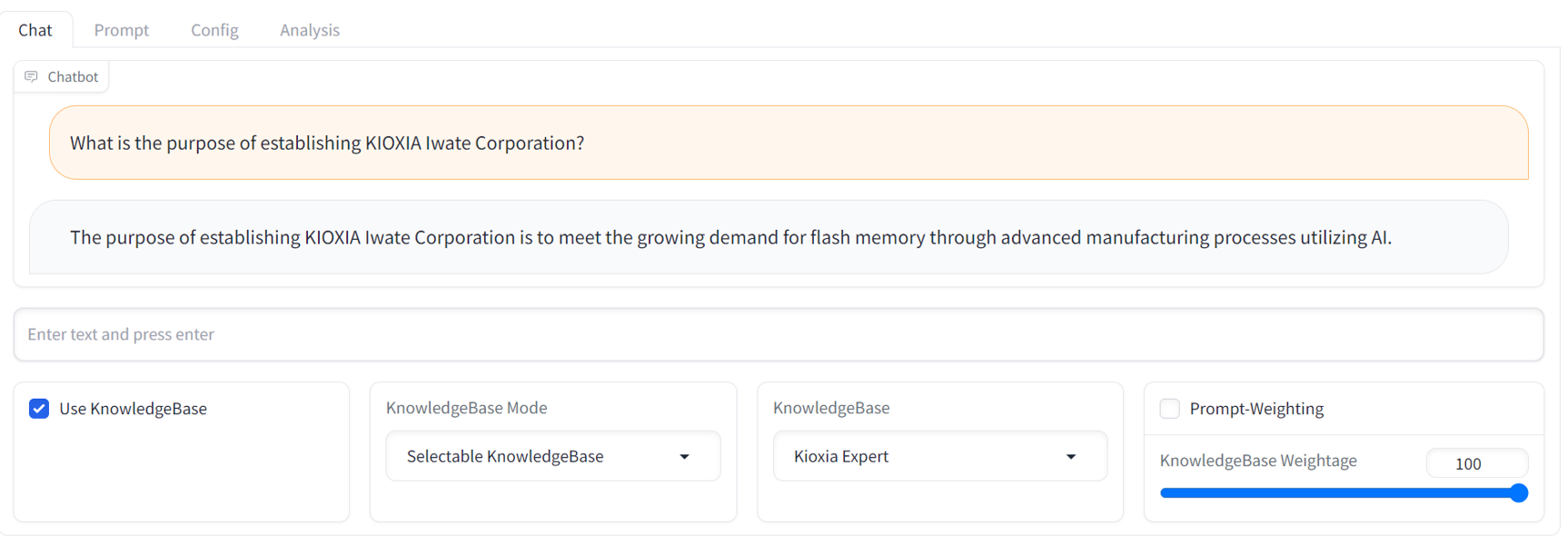
GUI operation manual , consulte o leia-me da GUI localizado no diretório docs/ .API access manual , consulte o leia-me da API e os scripts de amostra localizados no diretório examples/ .Abaixo está um exemplo de captura de tela do bate-papo da GUI. Ele fornece uma interface familiar de chatbot de streaming com um painel de ajuste RCG abrangente.
Não tem um servidor GPU local para executar esta ferramenta neste momento? Sem problemas. Visite este Repositório. Ele mostra as instruções para experimentar esta ferramenta na plataforma de nuvem AWS EC2.
Sinta-se à vontade para nos dar qualquer feedback e comentário. Agradecemos qualquer discussão e contribuição sobre esta ferramenta, incluindo novos recursos, melhorias e melhores documentações. Sinta-se à vontade para abrir um problema ou discussão. Ainda não temos nenhum modelo para problema ou discussão, então qualquer coisa servirá por enquanto.
Desenvolvimentos Futuros
É importante notar que esta ferramenta não fornece uma solução infalível para garantir uma resposta completamente segura e responsável de modelos generativos de IA, mesmo dentro de uma abordagem centrada na recuperação. O desenvolvimento de sistemas de IA mais seguros, interpretáveis e responsáveis continua a ser uma área ativa de investigação e esforço contínuo.
Os textos gerados a partir desta ferramenta podem apresentar variações, mesmo quando modificam apenas ligeiramente os prompts ou consultas, devido ao comportamento de previsão do próximo token dos LLMs da geração atual. Isso significa que os usuários podem precisar ajustar cuidadosamente os prompts e as consultas para obter as respostas ideais.
Se você achar nosso trabalho útil, cite-nos da seguinte forma:
@article{ng2023simplyretrieve,
title={SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool},
author={Youyang Ng and Daisuke Miyashita and Yasuto Hoshi and Yasuhiro Morioka and Osamu Torii and Tomoya Kodama and Jun Deguchi},
year={2023},
eprint={2308.03983},
archivePrefix={arXiv},
primaryClass={cs.CL},
journal={arXiv preprint arXiv:2308.03983}
}
?️ Afiliação: Instituto de P&D de Tecnologia de Memória, Kioxia Corporation, Japão


