Descobrindo conexões ocultas em dados financeiros não estruturados usando Amazon Bedrock e Amazon Neptune
Este repositório contém código para implantar um protótipo de solução que demonstra como a IA generativa e o gráfico de conhecimento podem ser combinados para criar um sistema escalonável, orientado a eventos e sem servidor para processar dados não estruturados para serviços financeiros. Esta solução pode ajudar os gestores de ativos da sua organização a descobrir conexões ocultas em suas carteiras de investimentos e fornece um exemplo de interface de usuário fácil de usar para consumir notícias financeiras e compreender suas conexões com suas carteiras de investimentos.
Caso de uso comercial
Os gestores de ativos geralmente investem em um grande número de empresas em seus portfólios e precisam ser capazes de acompanhar quaisquer notícias relacionadas a essas empresas, porque essas notícias os ajudariam a ficar à frente dos movimentos do mercado, identificar oportunidades de investimento e gerenciar melhor seus investimentos. portfólio.
Geralmente, o rastreamento de notícias pode ser feito facilmente configurando um alerta de notícias simples baseado em palavras-chave usando o nome da empresa investida, mas isso se torna cada vez mais difícil quando o evento noticioso não impacta diretamente a empresa investida. Por exemplo, o impacto poderia ser para um fornecedor de uma empresa beneficiária, o que poderia perturbar potencialmente a cadeia de abastecimento da empresa. Ou o impacto pode ser para um cliente de um cliente da sua empresa investida. Se essas empresas tivessem suas receitas concentradas em alguns clientes-chave, isso teria potencialmente um impacto financeiro negativo no seu investimento.
Esses impactos de segunda ou terceira ordem são difíceis de identificar e ainda mais difíceis de acompanhar. Com esta solução automatizada, os gestores de ativos podem construir um gráfico de conhecimento das relações que envolvem a sua carteira de investimentos e, em seguida, utilizar esse conhecimento para obter correlação e insights das últimas notícias.
Arquitetura
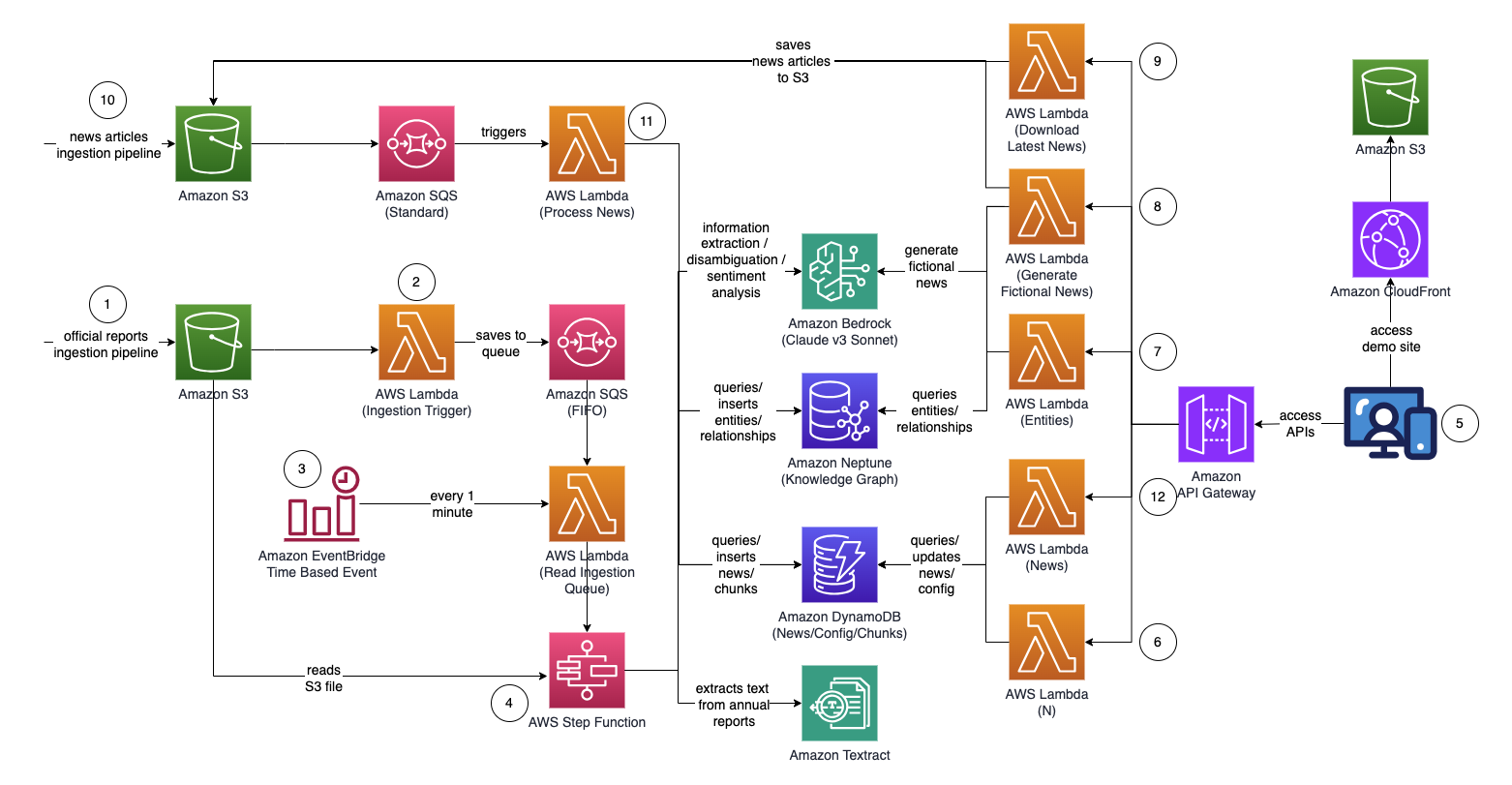
Gráfico de função de etapa (do ponto 4)
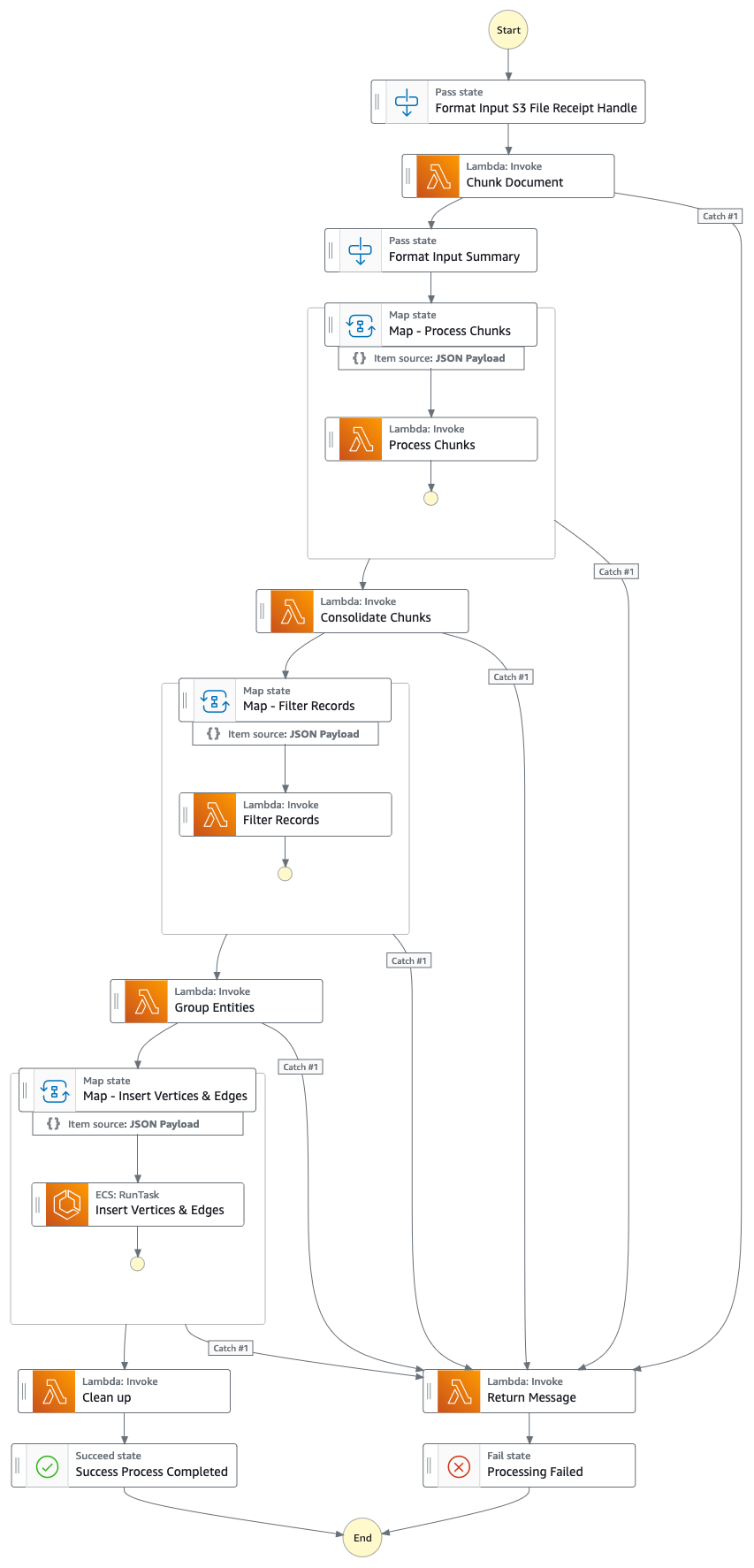
Fluxo da solução (passo a passo)
- Faça upload de relatórios proxy/anuais/10k oficiais (.PDF) para o bucket do Amazon S3.
- O nome do bucket S3 para upload pode ser recuperado no console do CloudFormation - saída da pilha principal - "IngestionBucket"
- Observe que os relatórios usados devem ser relatórios publicados oficialmente para minimizar a inclusão de dados imprecisos em seu gráfico de conhecimento (em oposição a notícias/tablóides).
- A notificação de eventos S3 aciona uma função AWS Lambda que envia o nome do bucket/arquivo S3 para um Amazon Simple Queue Service Queue (FIFO).
- O uso da fila FIFO visa garantir que o processo de ingestão do relatório seja executado sequencialmente para reduzir a probabilidade de introdução de dados duplicados em seu gráfico de conhecimento.
- Um evento baseado em tempo do Amazon EventBridge é executado a cada minuto para invocar uma função do AWS Lambda. A função recuperará a próxima mensagem de fila disponível do SQS e iniciará a execução de uma AWS Step Function de forma assíncrona.
- Uma máquina de estado de função de etapa executa uma série de tarefas para processar o documento carregado, extraindo informações importantes e inserindo-as em seu gráfico de conhecimento.
- Tarefas
- Usando o Amazon Textract, extraia o conteúdo de texto do arquivo de relatório proxy/anual/10k (PDF) no Amazon S3 e divida-o em vários pedaços de texto menores para processamento. Armazene os blocos de texto no Amazon DynamoDB.
- Usando o Claude v3 Sonnet da Anthropic no Amazon Bedrock, processe os primeiros pedaços de texto para determinar a entidade principal à qual o relatório está se referindo, juntamente com atributos relevantes (por exemplo, indústria).
- Recupera os blocos de texto do DynamoDB e, para cada bloco de texto, invoca uma função lambda para extrair entidades (empresa/pessoa) e seu relacionamento (cliente/fornecedor/parceiro/concorrente/diretor) com a entidade principal usando o Amazon Bedrock.
- Consolidar todas as informações extraídas
- Filtra ruído/entidades irrelevantes (ou seja, termos genéricos como "consumidores") usando o Amazon Bedrock.
- Use o Amazon Bedrock para realizar a desambiguação raciocinando usando as informações extraídas em relação à lista de entidades semelhantes do gráfico de conhecimento. Se a entidade não existir, insira-a. Caso contrário, use a entidade que já existe no gráfico de conhecimento. Insere todos os relacionamentos extraídos.
- Execute a limpeza excluindo a mensagem da fila SQS e o arquivo S3.
- Assim que esta etapa for concluída, seu gráfico de conhecimento estará atualizado e pronto para uso.
- Um usuário acessa um aplicativo da web baseado em React para visualizar os artigos de notícias que são enriquecidos com informações de entidade/sentimento/caminho de conexão.
- O URL do aplicativo da web pode ser copiado do console do CloudFormation - saída da pilha do webapp - "WebApplicationURL"
- Como esta é uma solução de exemplo para fins de demonstração, o usuário especifica o endpoint da API, a chave da API e a chave da API do News no aplicativo da web clicando no ícone de engrenagem no canto superior direito.
- O endpoint da API pode ser copiado do console do CloudFormation - saída da pilha principal - "APIEndpoint".
- A chave de API pode ser copiada do console da chave de API do API Gateway - pilha principal.
- A chave da API de notícias pode ser obtida em NewsAPI.org depois de criar uma conta gratuitamente.
- Clique no botão “Atualizar configurações” após preencher os valores.
- Usando o aplicativo Web, um usuário especifica o número de saltos (padrão N=2) no caminho de conexão a ser monitorado.
- Para fazer isso, clique no ícone de engrenagem no canto superior direito e especifique o valor de N.
- Usando o aplicativo web, um usuário especifica a lista de entidades a serem rastreadas.
- Para fazer isso, clique no ícone de engrenagem no canto superior direito e depois alterne o botão "Interessado" que marca a entidade correspondente como INTERESSADO=SIM/NÃO.
- Esta é uma etapa importante e deve ser realizada antes do processamento de qualquer artigo de notícias.
- Para gerar notícias fictícias, um usuário clica no botão "Gerar amostras de notícias" para gerar 10 amostras de notícias financeiras com conteúdo aleatório para serem inseridas no processo de ingestão de notícias.
- O conteúdo é gerado usando Amazon Bedrock e é puramente fictício.
- Para baixar notícias reais, o usuário clica no botão "Baixar últimas notícias" para baixar as principais notícias do dia (desenvolvido por NewsAPI.org).
- Carregar notícias (.TXT) para o bucket S3.
- O nome do bucket S3 para upload pode ser recuperado no console do CloudFormation - saída da pilha principal - "NewsBucket"
- As etapas 8 ou 9 carregaram notícias para o bucket S3 automaticamente, mas você também pode criar integrações com seu provedor de notícias preferido, como AWS Data Exchange ou qualquer provedor de notícias terceirizado, para colocar artigos de notícias como arquivos no bucket S3.
- O conteúdo do arquivo de dados de notícias deve ser formatado como: <date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>
- A notificação de eventos S3 envia o nome do bucket/arquivo S3 para SQS (padrão), que aciona várias funções lambda para processar os dados de notícias em paralelo.
- Usando o Amazon Bedrock, a função lambda extrai as entidades mencionadas nas notícias junto com quaisquer informações, relacionamentos e sentimentos relacionados da entidade mencionada.
- Em seguida, ele verifica o gráfico de conhecimento e usa o Amazon Bedrock para realizar a desambiguação, raciocinando usando as informações disponíveis nas notícias e no gráfico de conhecimento para identificar a entidade correspondente.
- Depois que a entidade for localizada, ela pesquisará e retornará quaisquer caminhos de conexão conectando-se a entidades marcadas com INTERESTED=YES no gráfico de conhecimento que estejam a N=2 saltos de distância.
- O aplicativo da web é atualizado automaticamente a cada 1 segundo para extrair o conjunto mais recente de notícias processadas para exibição no aplicativo da web.
Aplicativo Web React - Configurações
Explorador de gráficos
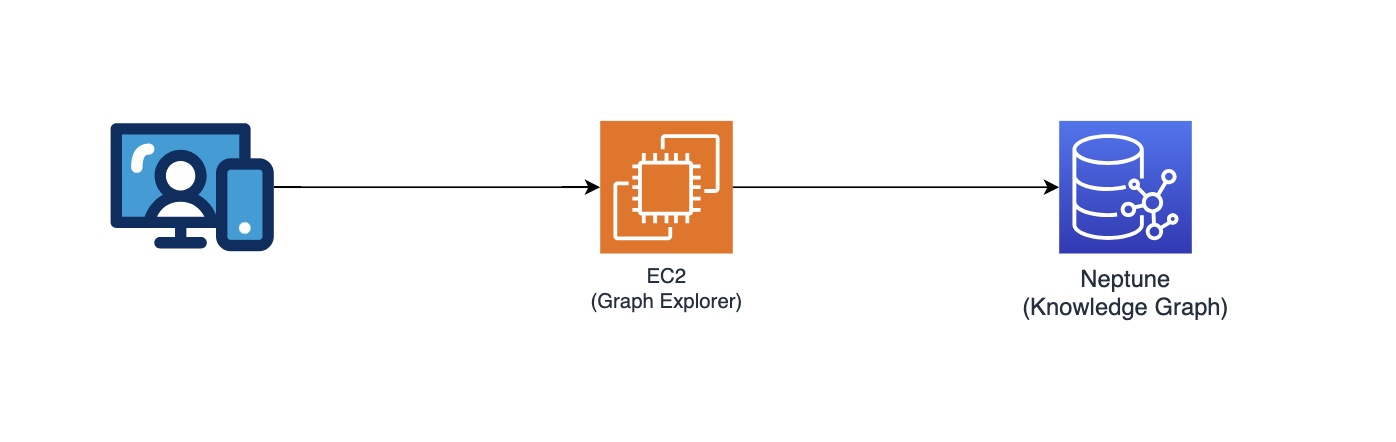
Este repositório também implanta o Graph Explorer (github/aws/graphexplorer), que é um aplicativo da web baseado em React que permite aos usuários visualizar as entidades e relacionamentos extraídos.
- Para acessar o Graph Explorer, recupere a URL do console do CloudFormation - saída da pilha principal - "GraphExplorer"
- Ao acessar o aplicativo web, você receberá um aviso sobre possíveis riscos de segurança em seu navegador, pois o certificado usado para o site é autoassinado. Você pode continuar a prosseguir. Para se livrar do aviso, leia isto.
- Uma vez iniciado, o aplicativo se conectará automaticamente ao banco de dados AWS Neptune e sincronizará seus dados. Você pode clicar no ícone de atualização a qualquer momento para sincronizar novamente os dados.
- Clique em "Open Graph Explorer" no canto superior direito para começar a visualizar o gráfico de conhecimento.
- Acesse github/aws/graphexplorer para obter mais informações sobre o Graph Explorer.
- Observe que o Graph Explorer não é necessário como parte da solução, mas facilita a exploração dos relacionamentos extraídos.
Demonstração - Introdução ao Graph Explorer
começando-com-graph-explorer.mp4
Aqui está outro vídeo de demonstração sobre os recursos do Graph Explorer: link para vídeo de demonstração
Explorador de Gráficos - Gráfico de Conhecimento
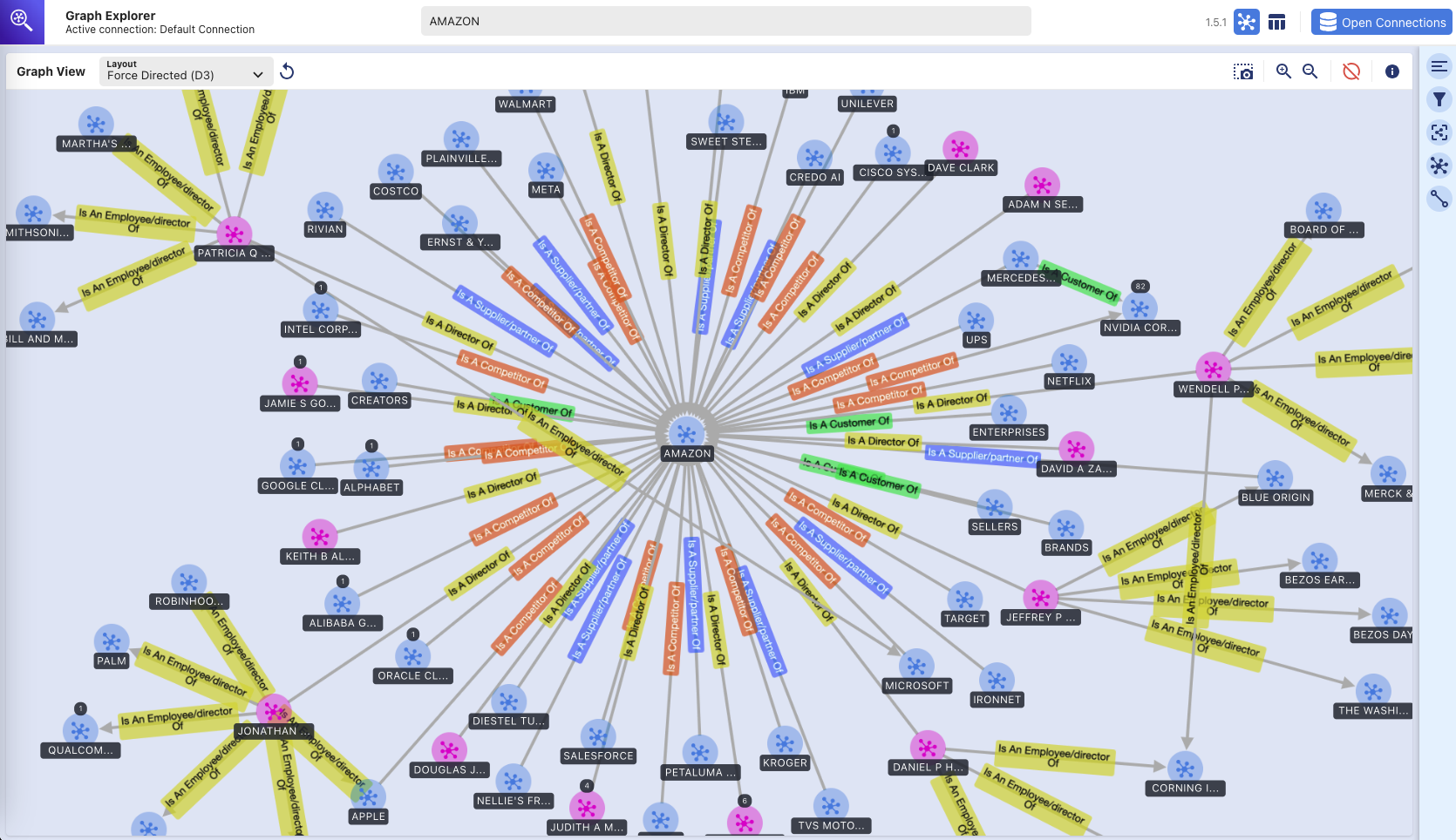
(exploração visual do banco de dados gráfico Amazon Neptune usando a ferramenta Graph Explorer)
Instruções de implantação
Este repositório fornece um aplicativo CDK que implantará toda a solução de protótipo em duas pilhas de CDK:
- pilha de aplicativos principal ("pilha principal") que pode ser implantada em qualquer região (por exemplo, us-east-1, us-west-2) que tenha os serviços necessários e os modelos Amazon Bedrock.
- pilha de aplicativos da web ("pilha de webapp") que só pode ser implantada em us-east-1, pois requer AWS WAF.
Você pode implantar as duas pilhas em regiões diferentes ou na mesma região (ou seja, us-east-1).
Serviços AWS usados
- Base Amazônica
- Amazon Netuno
- Amazon Textract
- Amazon DynamoDB
- Função de etapa AWS
- AWS Lambda
- Amazon Simple Queue Service (SQS)
- Amazon Event Bridge
- Serviço de armazenamento simples da Amazon (S3)
- Amazon Cloud Front
- AWS WAF
- Amazon Elastic Compute Cloud (EC2)
- Amazon VPC
- Gateway de API da Amazon
- Gerenciamento de identidade e acesso da AWS
Pré-requisitos
- Amazon Bedrock - Você precisará de acesso ao Anthropic Claude v3 Sonnet. Para configurar o acesso ao modelo no Amazon Bedrock, leia isto.
- Python - você precisará do Python 3 e superior.
- Nó - Você precisará da versão 18.0.0 e superior.
- Docker - você precisará da versão 24.0.0 e superior com Docker Buildx e terá o daemon docker em execução.
Configurar o virtualenv
Para criar manualmente um virtualenv no MacOS e Linux:
Após a conclusão do processo init e a criação do virtualenv, você pode usar a etapa a seguir para ativar seu virtualenv.
$ source .venv/bin/activate
Se você for uma plataforma Windows, você ativaria o virtualenv assim:
% .venvScriptsactivate.bat
Depois que o virtualenv for ativado, você poderá instalar as dependências necessárias.
$ pip install -r requirements.txt
Pré-implantação
Se esta for a primeira vez que você implanta seu código via CDK em sua conta da AWS, você precisará primeiro inicializar sua conta da AWS em us-east-1 e também na região em que está implantando. Caso contrário, você pode pular esta etapa.
$ cdk bootstrap aws://<account no>/us-east-1 aws://<account no>/<aws region to deploy main application stack>
Em seguida, execute o comando abaixo para:
- construir o aplicativo da web baseado em React
- baixe as dependências python necessárias para criar a camada AWS Lambda
- copiar biblioteca personalizada (connectionsinsights)
Implantar
Para implantar a solução (leva aproximadamente 30 minutos):
$ ./deploy.sh <aws region to deploy main application stack>
Limpar
Para destruir a solução:
$ ./destroy.sh <aws region where main application stack was deployed>
Se você encontrar uma falha de exclusão devido aos buckets S3 não estarem vazios, isso pode ser devido ao acesso aos arquivos de log gravados nos buckets S3 depois que eles foram esvaziados como parte do processo de destruição do cdk. Se isso acontecer, basta esvaziar esses buckets e executar novamente o comando de limpeza.


