JoyVASA
1.0.0
Xuyang Cao 1* Guoxin Wang 12* Sheng Shi 1* Jun Zhao 1 Yang Yao 1
Jintao Fei 1 Minyu Gao 1
1 JD Health International Inc. 2 Universidade de Zhejiang
A animação de retratos baseada em áudio fez avanços significativos com modelos baseados em difusão, melhorando a qualidade do vídeo e a precisão da sincronização labial. No entanto, a crescente complexidade destes modelos levou a ineficiências no treinamento e inferência, bem como a restrições na duração do vídeo e na continuidade entre quadros. Neste artigo, propomos o JoyVASA, um método baseado em difusão para gerar dinâmica facial e movimento da cabeça em animação facial orientada por áudio. Especificamente, na primeira etapa, introduzimos uma estrutura de representação facial desacoplada que separa expressões faciais dinâmicas de representações faciais 3D estáticas. Essa dissociação permite que o sistema gere vídeos mais longos combinando qualquer representação facial 3D estática com sequências de movimento dinâmicas. Então, no segundo estágio, um transformador de difusão é treinado para gerar sequências de movimento diretamente a partir de sinais de áudio, independentemente da identidade do personagem. Finalmente, um gerador treinado na primeira etapa utiliza a representação facial 3D e as sequências de movimento geradas como entradas para renderizar animações de alta qualidade. Com a representação facial dissociada e o processo de geração de movimento independente de identidade, o JoyVASA vai além dos retratos humanos para animar rostos de animais de forma integrada. O modelo é treinado em um conjunto de dados híbrido de dados privados em chinês e dados públicos em inglês, permitindo suporte multilíngue. Resultados experimentais validam a eficácia da nossa abordagem. O trabalho futuro se concentrará na melhoria do desempenho em tempo real e no refinamento do controle de expressão, expandindo ainda mais as aplicações da estrutura em animação de retratos.
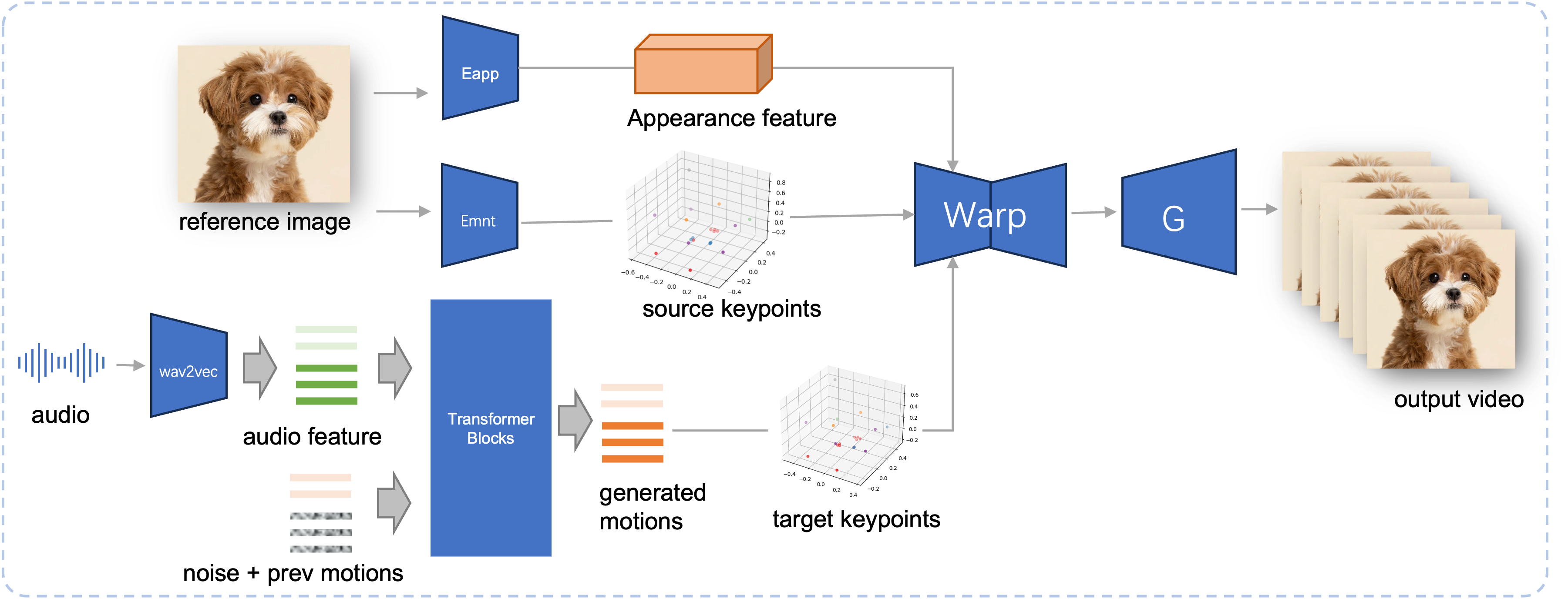
Pipeline de inferência do JoyVASA proposto. Dada uma imagem de referência, primeiro extraímos o recurso de aparência facial 3D usando o codificador de aparência no LivePortrait, e também uma série de pontos-chave 3D aprendidos usando o codificador de movimento. Para a fala de entrada, os recursos de áudio são inicialmente extraídos usando o codificador wav2vec2. As sequências de movimento acionadas por áudio são então amostradas usando um modelo de difusão treinado no segundo estágio em uma janela deslizante. Usando os pontos-chave 3D da imagem de referência e as sequências de movimento alvo amostradas, os pontos-chave alvo são calculados. Finalmente, o recurso de aparência facial 3D é distorcido com base nos pontos-chave de origem e destino e renderizado por um gerador para produzir o vídeo de saída final.
Requisitos do sistema:
Ubuntu:
Testado no Ubuntu 20.04, Cuda 11.3
GPUs testadas: A100
Windows:
Testado no Windows 11, CUDA 12.1
GPUs testadas: GPU VRAM de 8 GB para laptop RTX 4060
Criar ambiente:
# 1. Criar ambiente baseconda create -n joyvasa python=3.10 -y conda ativar joyvasa # 2. Instale os requisitospip install -r requisitos.txt# 3. Instale o ffmpegsudo apt-get update sudo apt-get install ffmpeg -y# 4. Instale MultiScaleDeformableAttentioncd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build installcd - # igual a cd ../../../../../../../
Certifique-se de ter o git-lfs instalado e baixe todos os seguintes pontos de verificação para pretrained_weights :
instalação do git lfs clone git https://huggingface.co/jdh-algo/JoyVASA
Oferecemos suporte a dois tipos de codificadores de áudio, incluindo wav2vec2-base e hubert-chinese.
Execute os seguintes comandos para baixar pesos pré-treinados em hubert-chinese:
instalação do git lfs clone git https://huggingface.co/TencentGameMate/chinese-hubert-base
Para obter os pesos pré-treinados do wav2vec2-base, execute os seguintes comandos:
instalação do git lfs clone git https://huggingface.co/facebook/wav2vec2-base-960h
Observação
O modelo de geração de movimento com codificador wav2vec2 será suportado posteriormente.
# !pip install -U "huggingface_hub[cli]"huggingface-cli download KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
Consulte Liveportrait para obter mais métodos de download.
pretrained_weights O diretório pretrained_weights final deve ficar assim:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.jsonObservação
A pasta TencentGameMate:chinese-hubert-base no Windows deve ser renomeada como chinese-hubert-base .
Animal:
python inference.py -r assets/examples/imgs/joyvasa_001.png -a assets/examples/audios/joyvasa_001.wav --animation_mode animal --cfg_scale 2.0
Humano:
python inference.py -r assets/examples/imgs/joyvasa_003.png -a assets/examples/audios/joyvasa_003.wav --animation_mode humano --cfg_scale 2.0
Você pode alterar cfg_scale para obter resultados com diferentes expressões e poses.
Observação
A incompatibilidade do modo de animação e da imagem de referência pode resultar em resultados incorretos.
Use o seguinte comando para iniciar a demonstração da web:
aplicativo python.py
A demonstração será criada em http://127.0.0.1:7862.
Se você achar nosso trabalho útil, considere nos citar:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}Gostaríamos de agradecer aos colaboradores dos repositórios LivePortrait, Open Facevid2vid, InsightFace, X-Pose, DiffPoseTalk, Hallo, wav2vec 2.0, Chinese Speech Pretrain, Q-Align, Syncnet e VBench, por sua pesquisa aberta e trabalho extraordinário.


