synthetic data generator
0.2.3
Mudar idioma: 简体中文 | Documentos mais recentes da API | Roteiro | Junte-se ao Grupo Wechat
Exemplos do Colab: LLM: Síntese de Dados | LLM: Inferência fora da mesa | CTGAN suportado por dados de nível de bilhão
O Synthetic Data Generator (SDG) é uma estrutura especializada projetada para gerar dados tabulares estruturados de alta qualidade.
Os dados sintéticos não contêm nenhuma informação sensível, mas mantêm as características essenciais dos dados originais, tornando-os isentos de regulamentações de privacidade como GDPR e ADPPA.
Dados sintéticos de alta qualidade podem ser utilizados com segurança em vários domínios, incluindo compartilhamento de dados, treinamento e depuração de modelos, desenvolvimento e teste de sistemas, etc.
Estamos entusiasmados por ter você aqui e aguardamos suas contribuições. Comece o projeto por meio deste Guia de Visão Geral de Contribuições!
Nossas principais conquistas e cronogramas atuais são os seguintes:
21 de novembro de 2024: 1) Integração do modelo - Integramos o modelo GaussianCopula em nosso sistema de processador de dados. Confira o exemplo de código neste PR; 2) Qualidade Sintética - Implementamos a detecção automática de relacionamentos de colunas de dados e permitimos a especificação de relacionamentos, melhorando a qualidade dos dados sintéticos (Exemplo de Código); 3) Melhoria de desempenho - Reduzimos significativamente o uso de memória do GaussianCopula ao lidar com dados discretos, permitindo o treinamento em milhares de entradas de dados categóricos com uma configuração 2C4G !
30 de maio de 2024: O módulo Processador de Dados foi oficialmente incorporado. Este módulo irá: 1) ajudar o SDG a converter o formato de algumas colunas de dados (como colunas de data e hora) antes de alimentar o modelo (para evitar serem tratados como tipos discretos) e converter reversamente os dados gerados pelo modelo no formato original ; 2) realizar pré-processamento e pós-processamento mais customizados em vários tipos de dados; 3) lidar facilmente com problemas como valores nulos nos dados originais; 4) apoiar o sistema de plug-in.
20 de fevereiro de 2024: um modelo de síntese de dados de tabela única baseado em LLM está incluído, veja o exemplo do colab: LLM: Síntese de Dados e LLM: Inferência de Recursos Fora da Tabela.
7 de fevereiro de 2024: Melhoramos sdgx.data_models.metadata para oferecer suporte à descrição de informações de metadados para tabelas únicas e múltiplas tabelas, suporte a vários tipos de dados e suporte à inferência automática de tipos de dados. veja o exemplo do colab: metadados de tabela única SDG。
20 de dezembro de 2023: v0.1.0 lançada, um modelo CTGAN que suporta bilhões de recursos de processamento de dados está incluído, veja nosso benchmark em relação ao SDV, onde o SDG alcançou menos consumo de memória e evitou travamentos durante o treinamento. Para uso específico, veja o exemplo do colab: CTGAN com suporte para dados de bilhões de níveis.
10 de agosto de 2023: Primeira linha do código ODS confirmada.
Há muito tempo, o LLM tem sido utilizado para compreender e gerar diversos tipos de dados. Na verdade, o LLM também possui certos recursos na geração de dados tabulares. Além disso, possui algumas habilidades que não podem ser alcançadas pelos métodos tradicionais (baseados em métodos GAN ou métodos estatísticos).
Nosso sdgx.models.LLM.single_table.gpt.SingleTableGPTModel implementa dois novos recursos:
Nenhum dado de treinamento é necessário, dados sintéticos podem ser gerados com base em dados de metadados, veja nosso exemplo de colab.
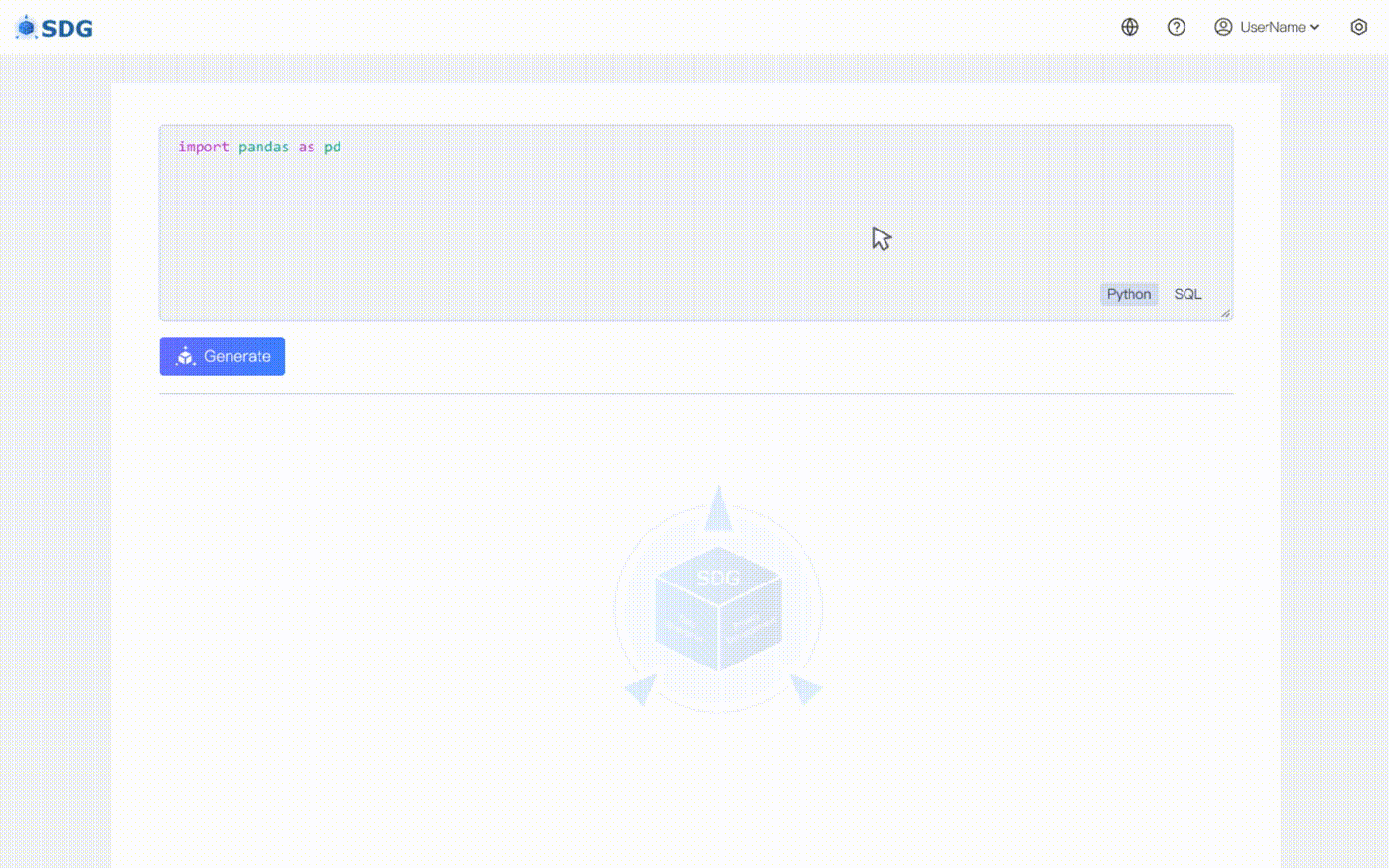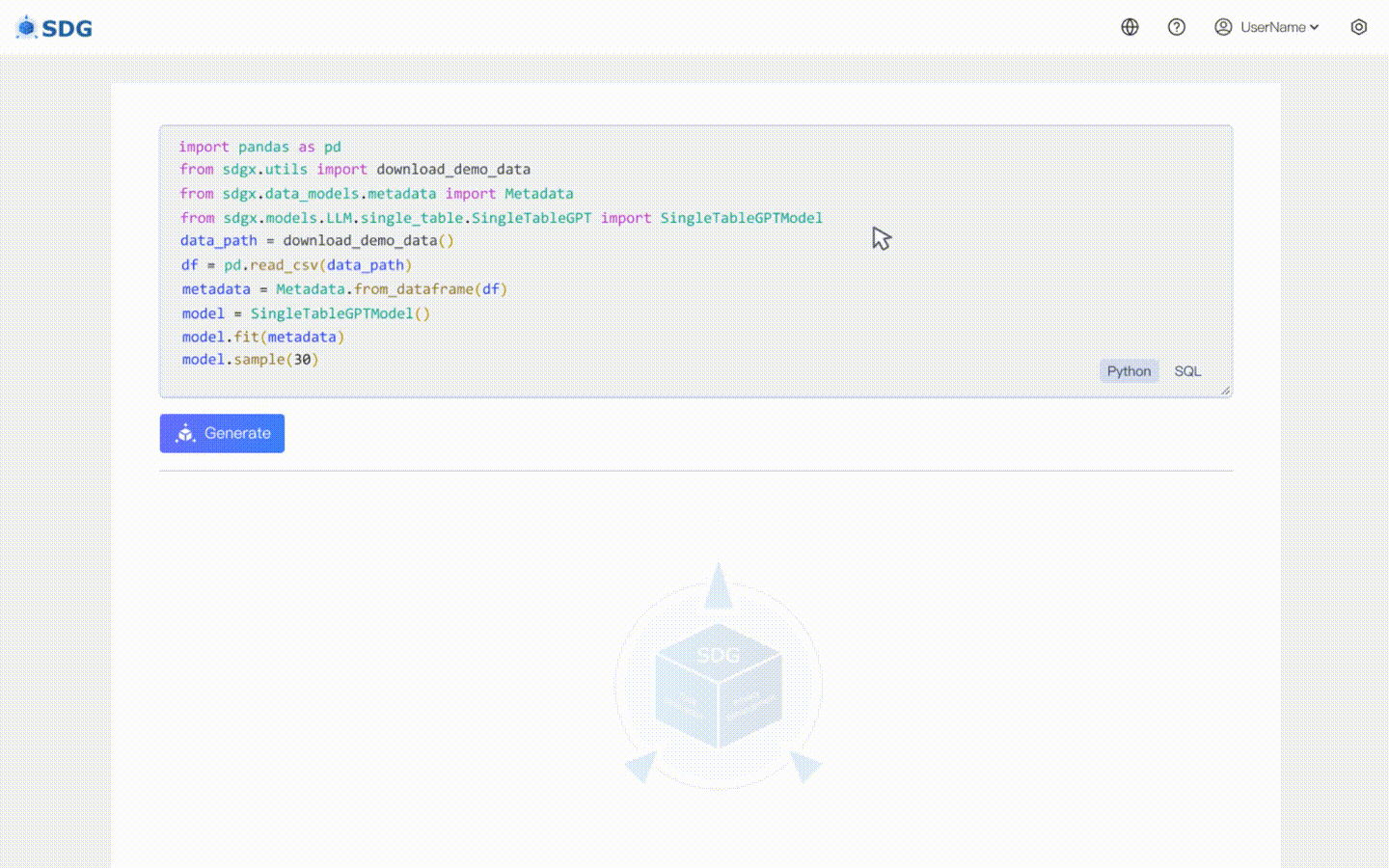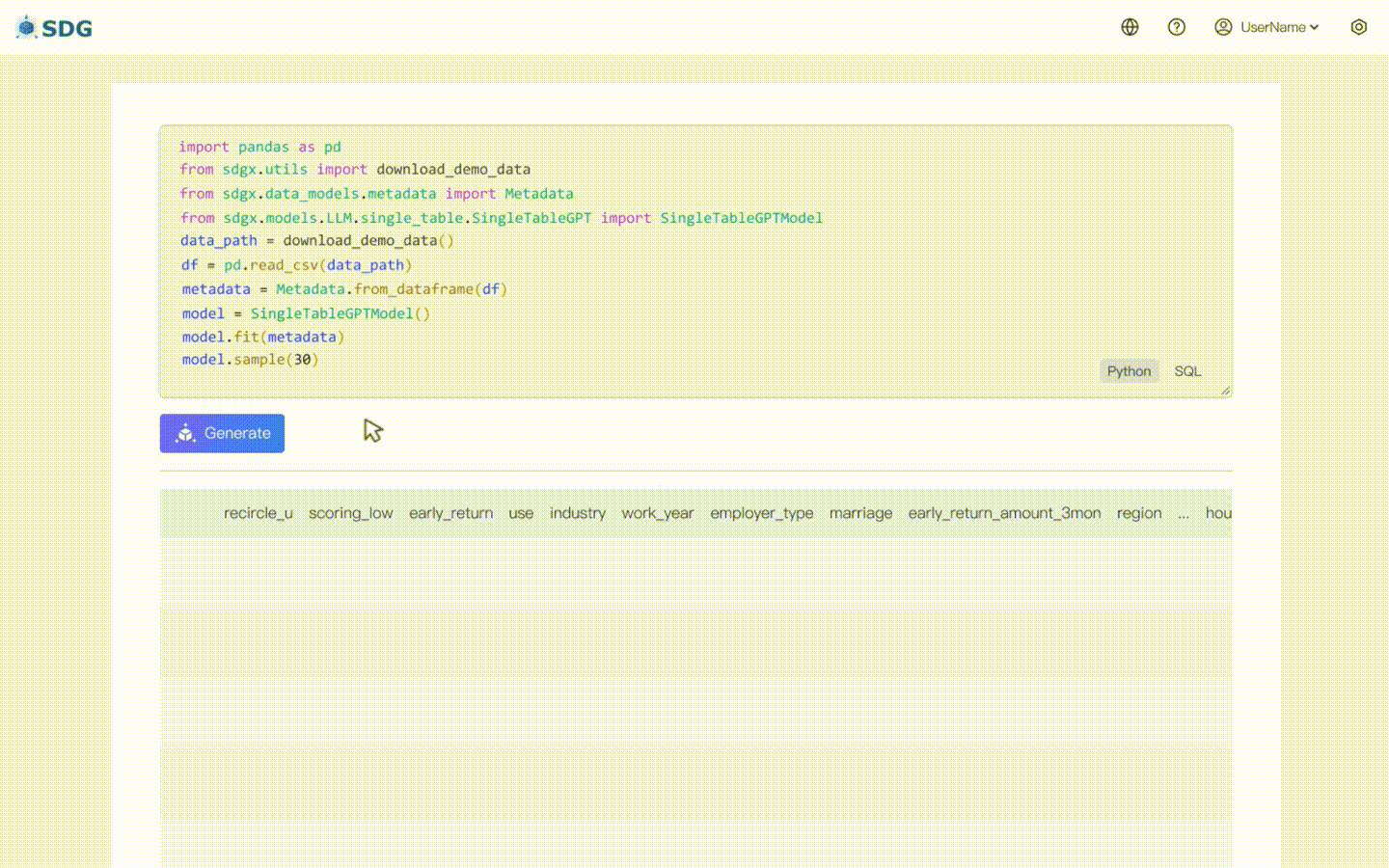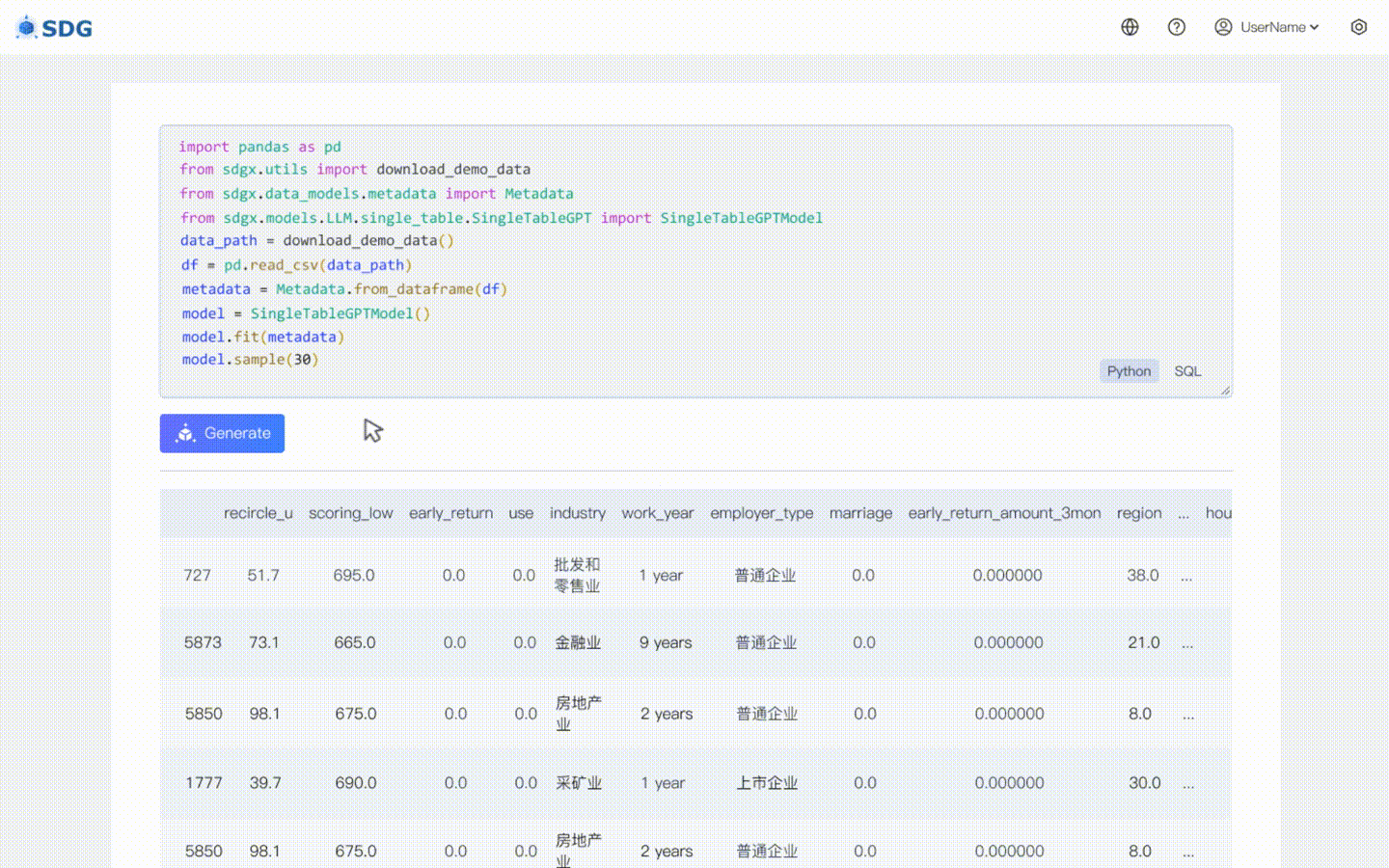
Inferir novos dados de coluna com base nos dados existentes na tabela e no conhecimento dominado pelo LLM, veja em nosso exemplo de colab.
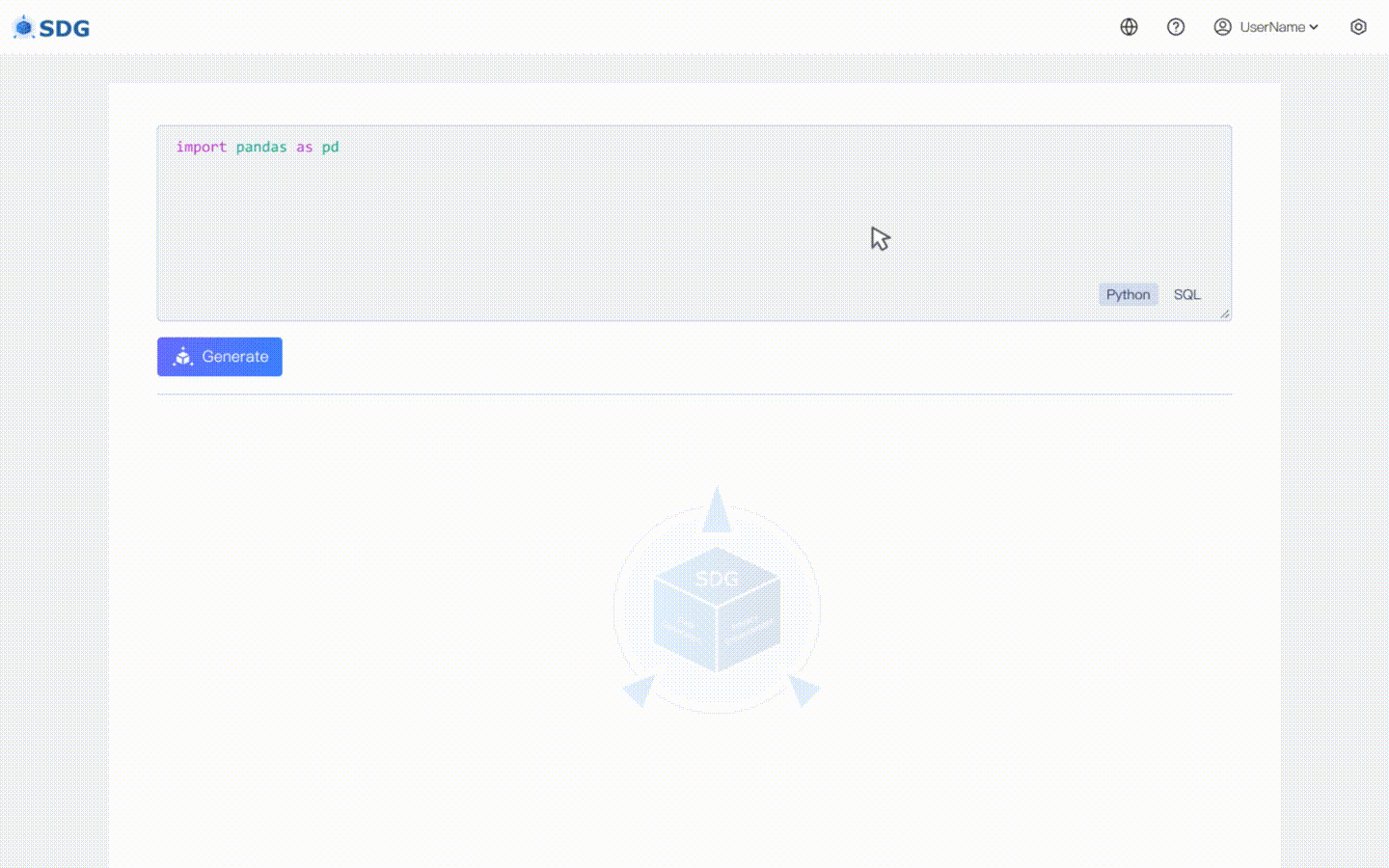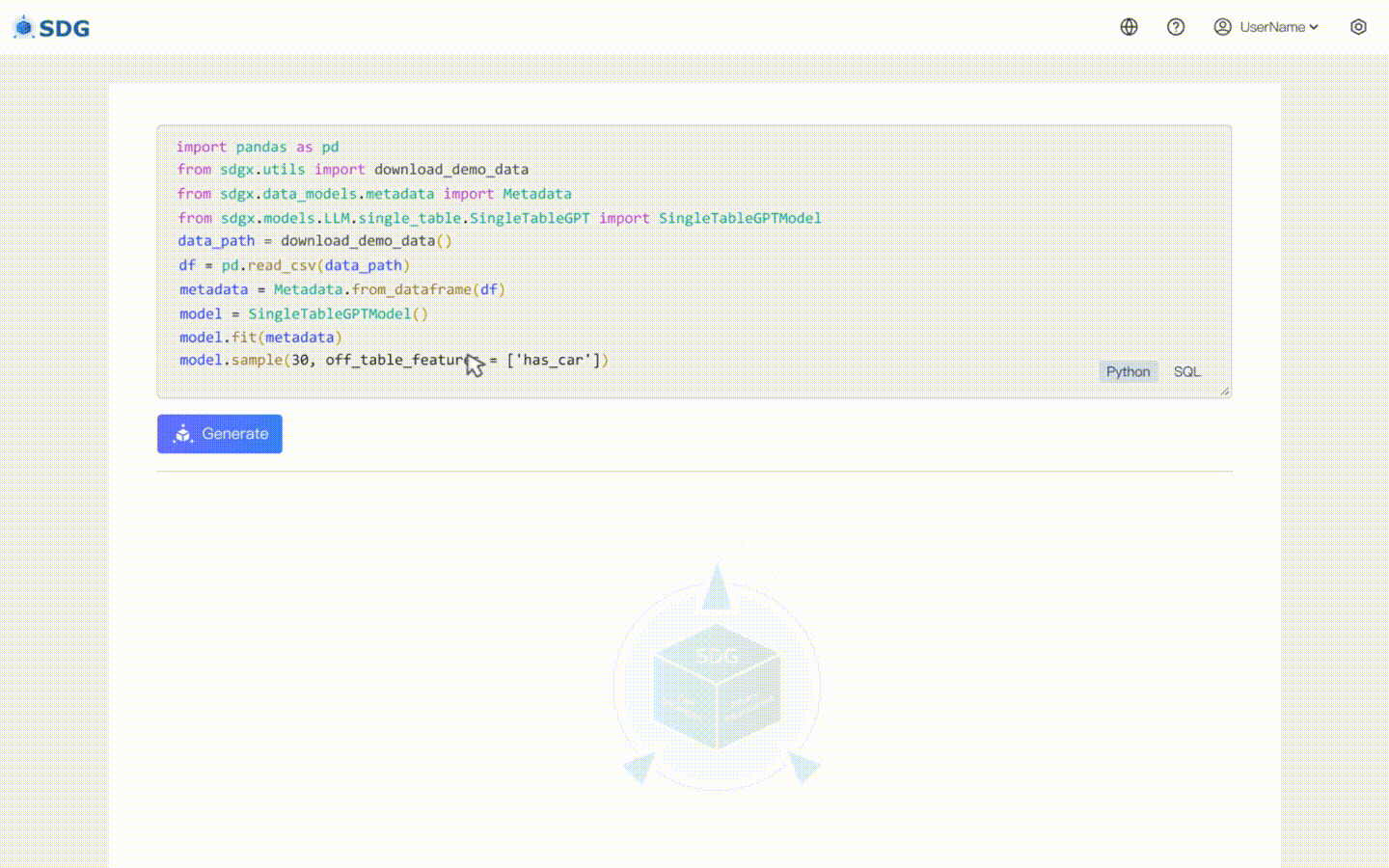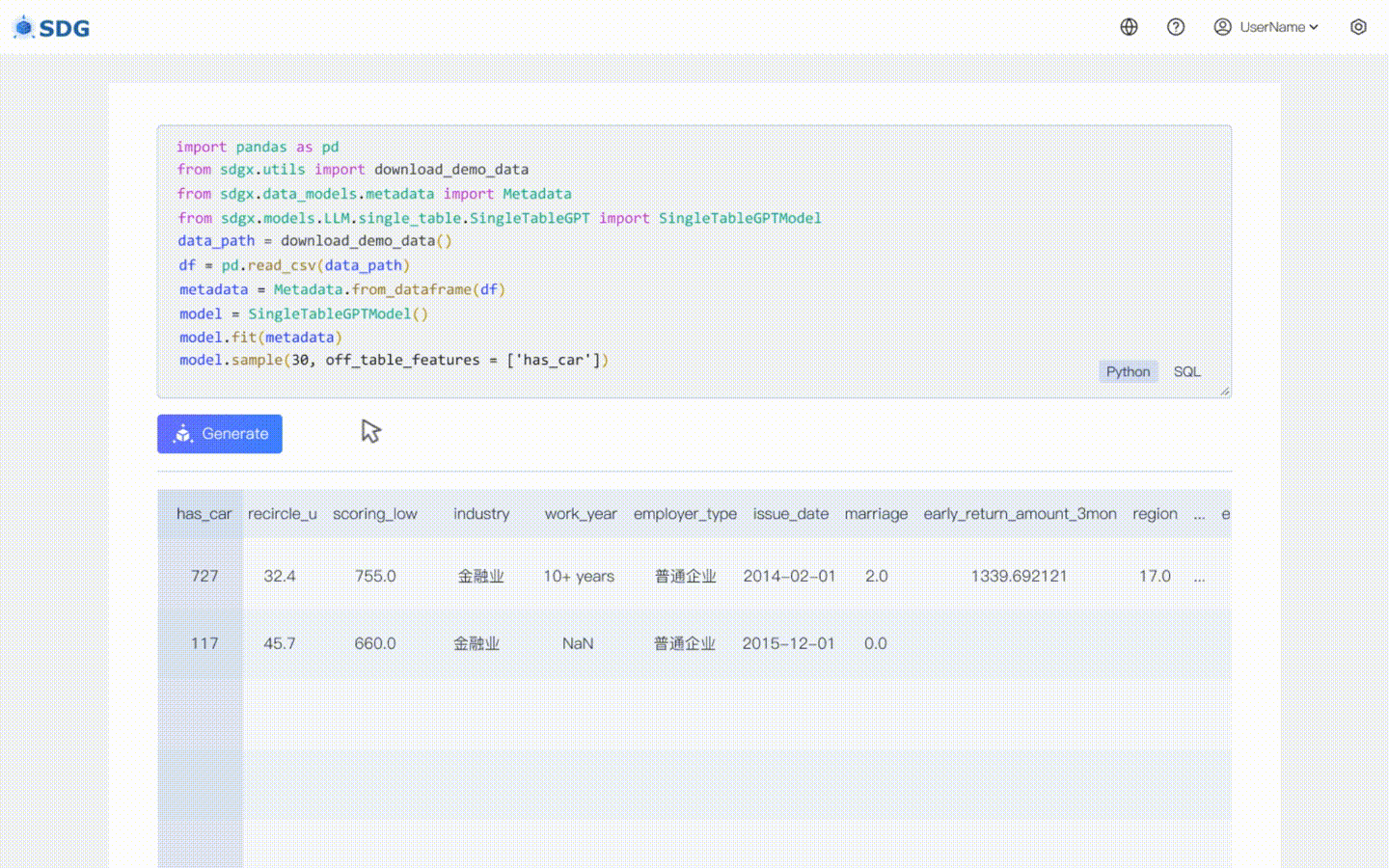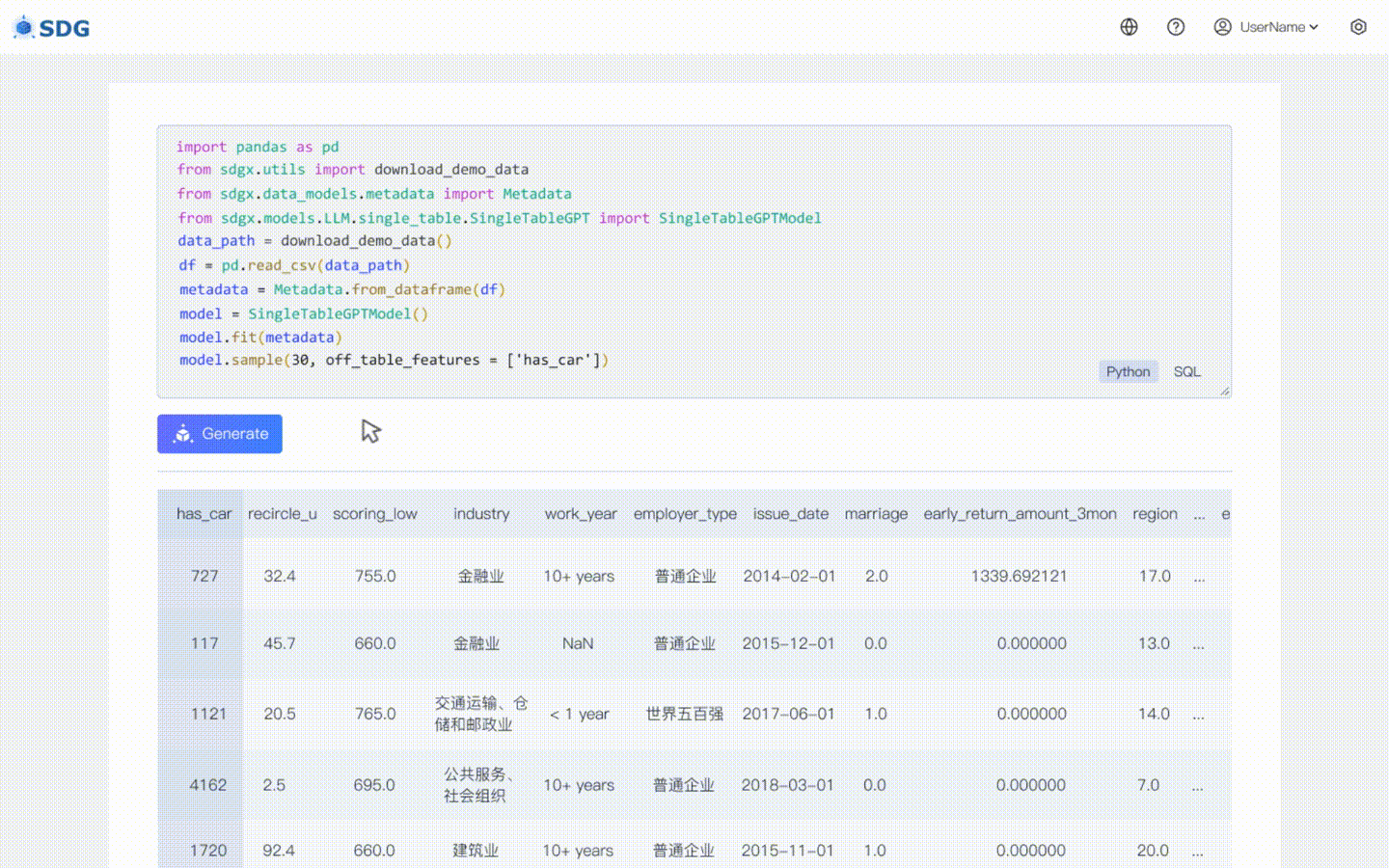
Avanços tecnológicos:
Suporta uma ampla gama de algoritmos de síntese de dados estatísticos, o modelo de geração de dados sintéticos baseado em LLM também está integrado;
Otimizado para big data, reduzindo efetivamente o consumo de memória;
Acompanhar continuamente os últimos avanços na academia e na indústria e introduzir suporte para algoritmos e modelos excelentes em tempo hábil.
Melhorias de privacidade:
O SDG apoia a privacidade diferencial, o anonimato e outros métodos para aumentar a segurança dos dados sintéticos.
Fácil de estender:
Suporta expansão de modelos, processamento de dados, conectores de dados, etc. na forma de pacotes de plug-ins.
Você pode usar imagens pré-construídas para experimentar rapidamente os recursos mais recentes.
docker pull idsteam/sdgx:mais recente
pip instalar sdgx
Use o SDG instalando-o por meio do código-fonte.
git clone [email protected]:hitsz-ids/synthetic-data-generator.git pip install .# Ou instale a partir de gitpip install git+https://github.com/hitsz-ids/synthetic-data-generator.git
from sdgx.data_connectors.csv_connector import CsvConnectorfrom sdgx.models.ml.single_table.ctgan import CTGANSynthesizerModelfrom sdgx.synthesizer import Synthesizerfrom sdgx.utils import download_demo_data# Isso fará o download dos dados de demonstração para ./datasetdataset_csv = download_demo_data()# Criar conector de dados para csv filedata_connector = CsvConnector(path=dataset_csv)# Inicialize o sintetizador, use CTGAN modelsynthesizer = Synthesizer(model=CTGANSynthesizerModel(epochs=1), # Para rápido demodata_connector=data_connector, )# Ajuste o modelsynthesizer.fit()# Samplesampled_data = sintetizador.sample(1000)print(sampled_data)
Os dados reais são os seguintes:
>>> data_connector.read() idade classe de trabalho fnlwgt educação ... horas de perda de capital por semana classe do país de origem0 2 State-gov 77516 Bacharéis ... 0 2 Estados Unidos <= 50K1 3 Autônomo-não-inc 83311 Bacharéis .. . 0 0 Estados Unidos <=50K2 2 Privado 215646 HS-grad ... 0 2 Estados Unidos <=50K3 3 Privado 234721 11º ... 0 2 Estados Unidos <=50K4 1 Privado 338409 Bacharel ... 0 2 Cuba <=50K... ... ... ... ... ... . .. ... ... ...48837 2 Privado 215419 Bacharel ... 0 2 Estados Unidos <=50K48838 4 NaN 321403 HS-grad ... 0 2 Estados Unidos <= 50K48839 2 Privado 374983 Bacharelado ... 0 3 Estados Unidos <= 50K48840 2 Privado 83891 Bacharelado ... 0 2 Estados Unidos <= 50K48841 1 Autônomo-inc 182148 Bacharelado ... 0 3 Estados Unidos >50K[48.842 linhas x 15 colunas]
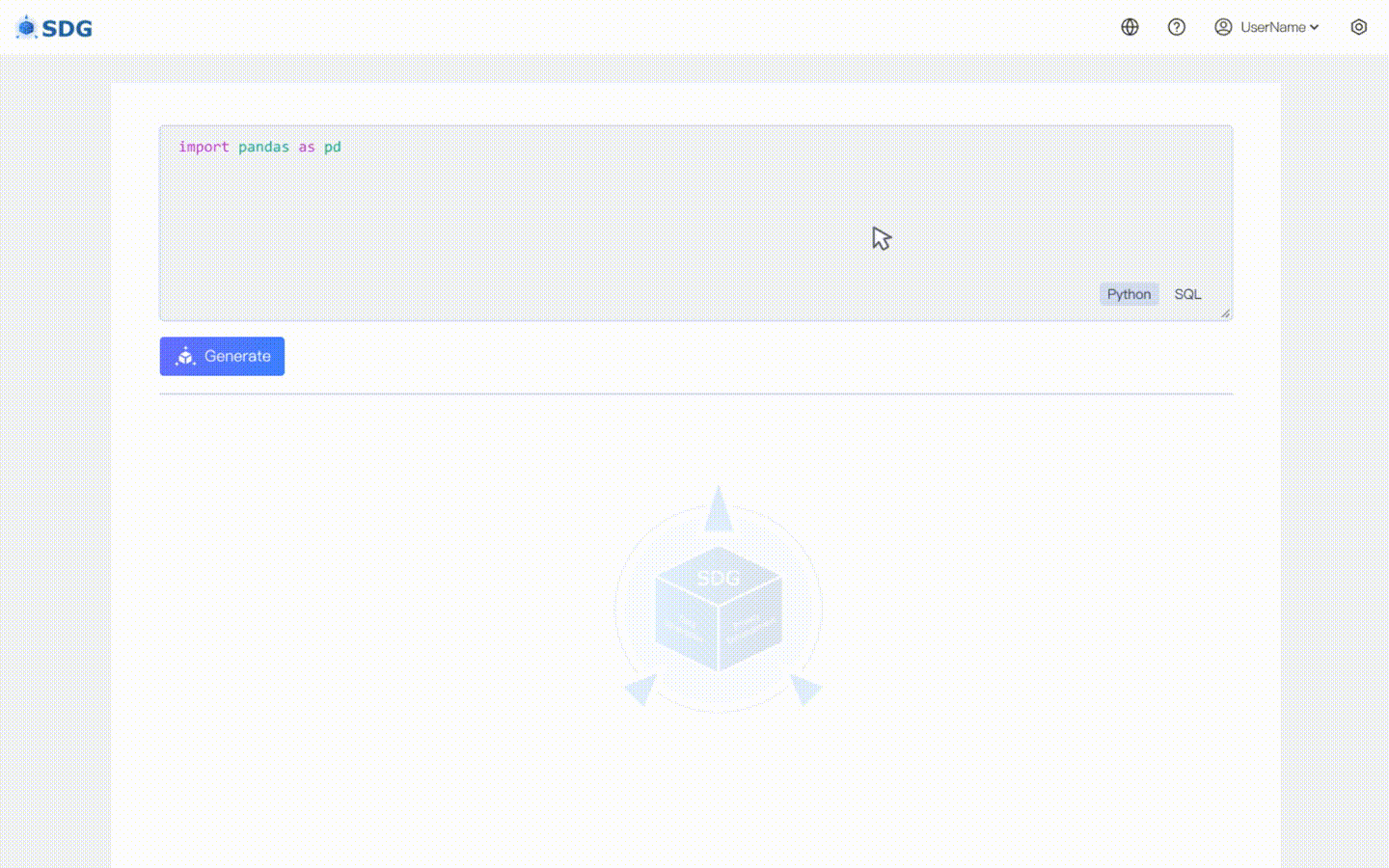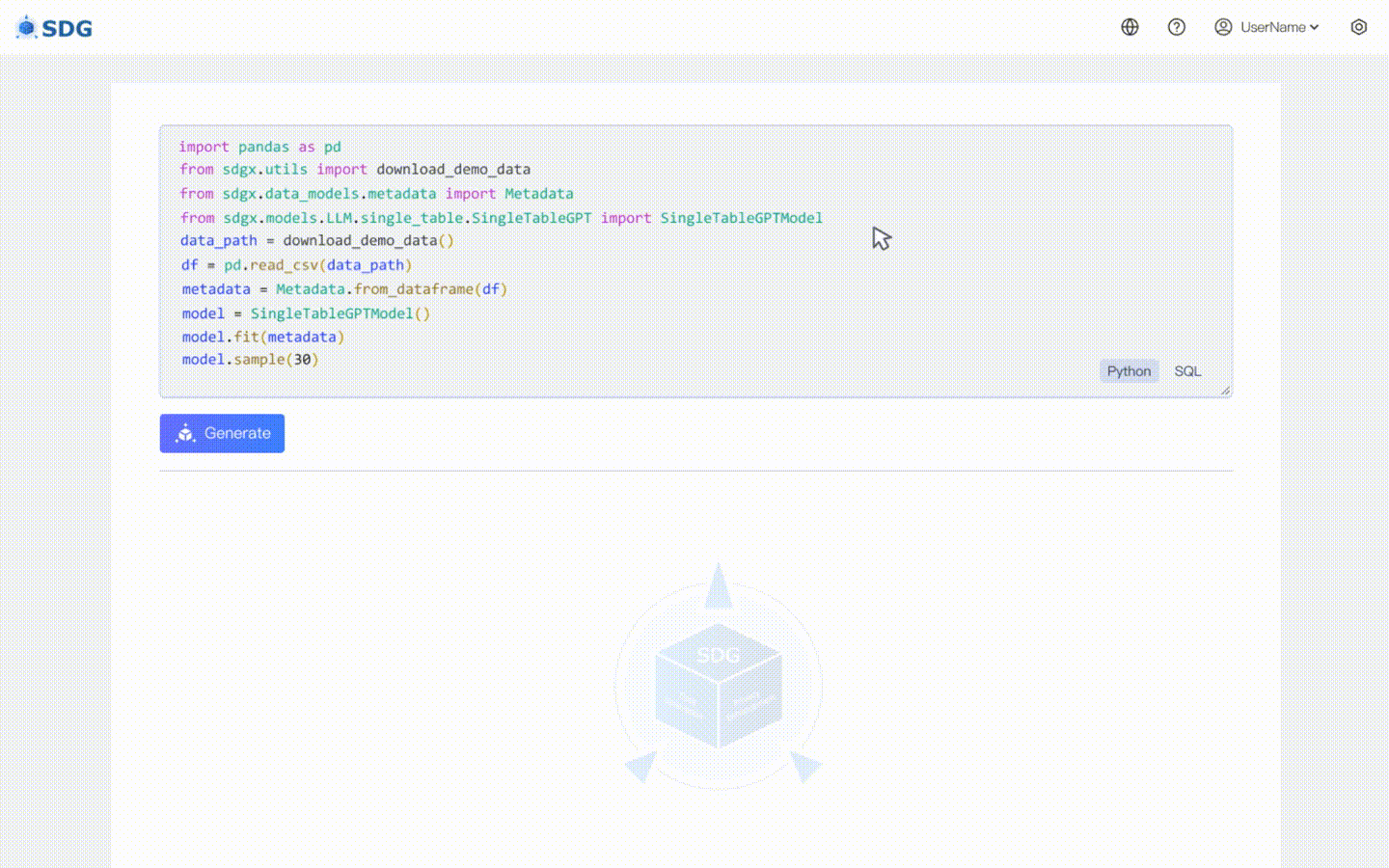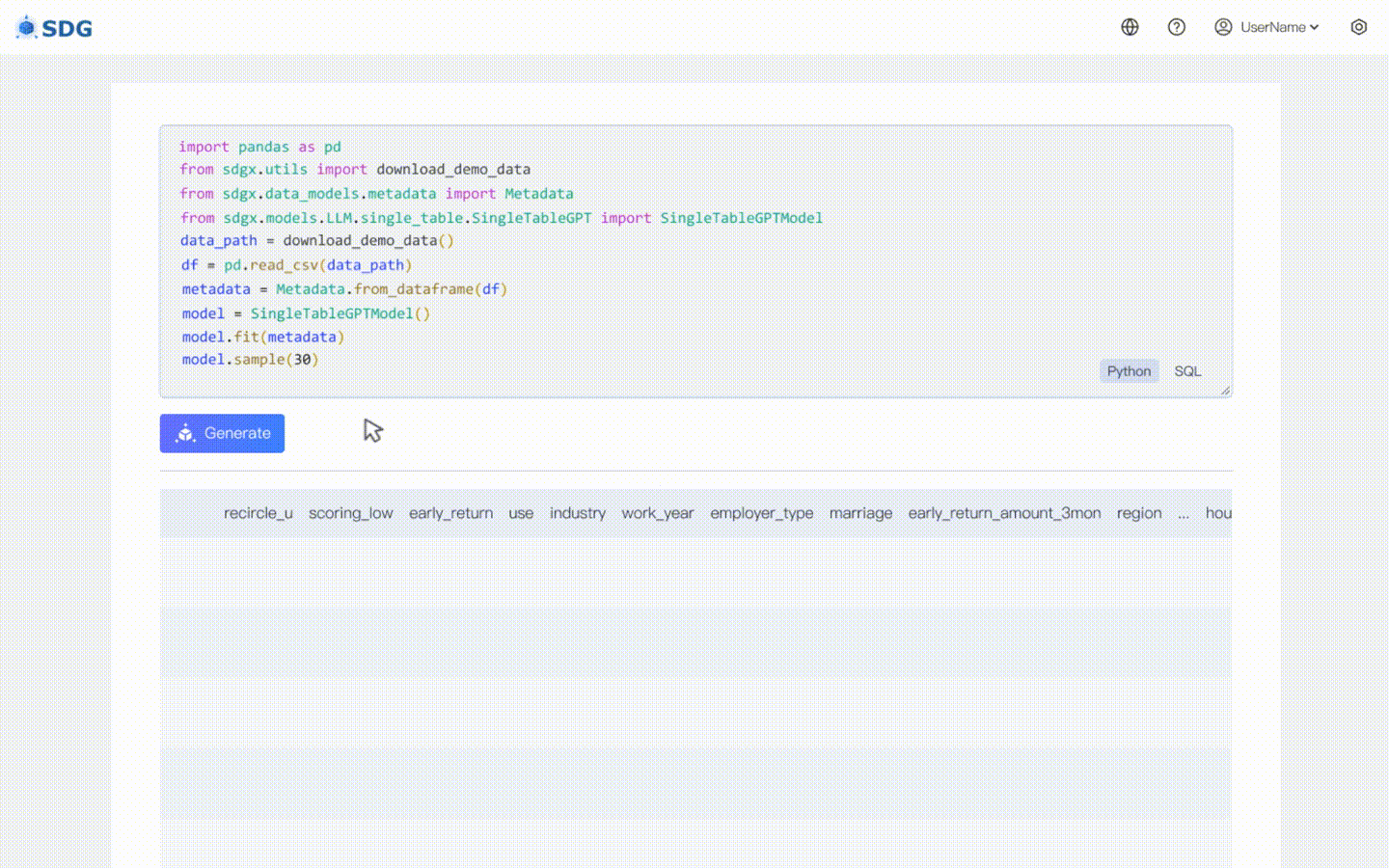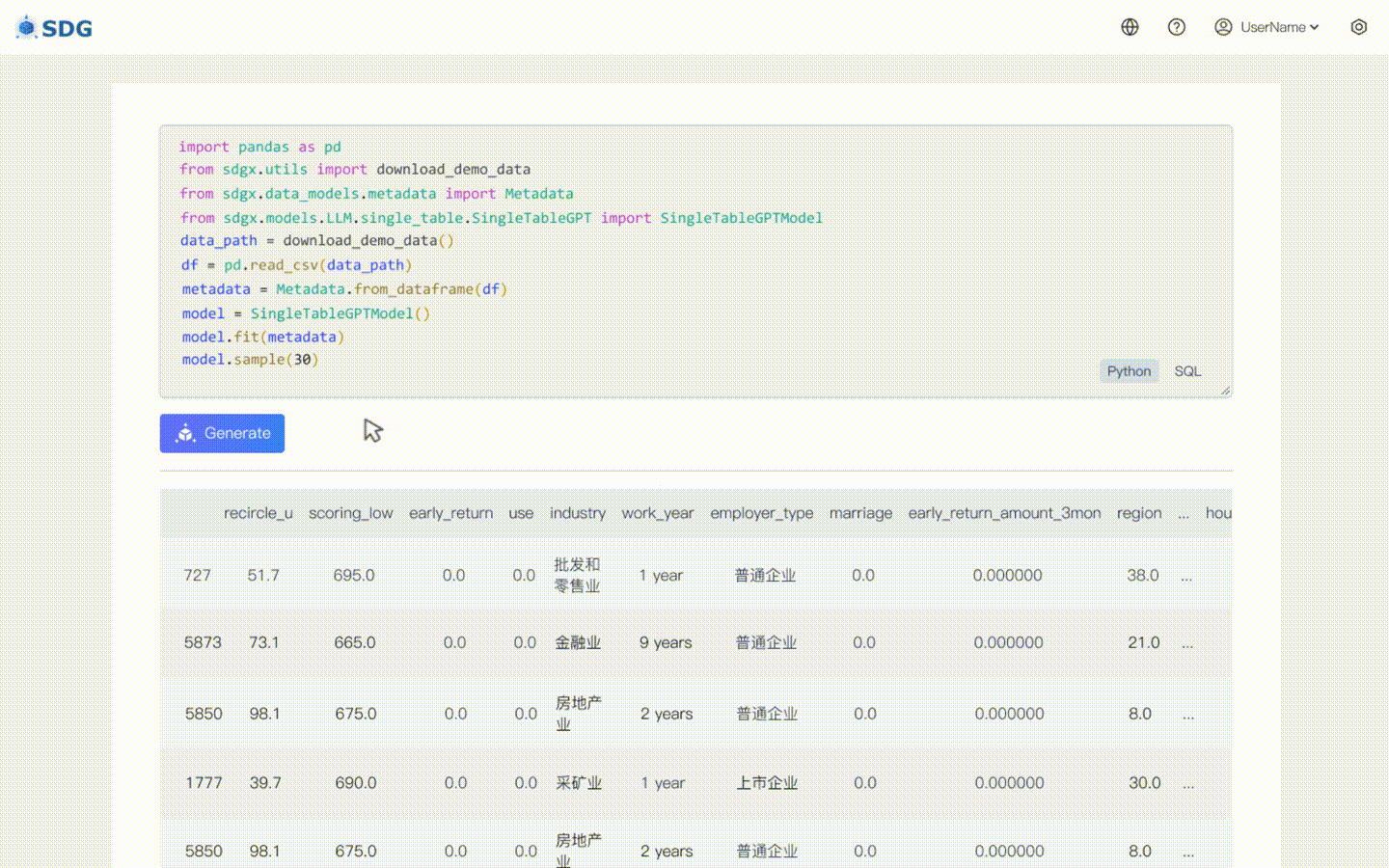
Os dados sintéticos são os seguintes:
>>> sampled_data idade classe de trabalho fnlwgt educação ... horas de perda de capital por semana classe do país de origem0 1 NaN 28219 Alguma faculdade ... 0 2 Porto Rico <= 50K1 2 Privado 250166 HS-grad ... 0 2 Estados Unidos> 50K2 2 Privado 50304 HS-grad ... 0 2 Estados Unidos <=50K3 4 Privado 89318 Bacharelado ... 0 2 Porto Rico >50K4 1 Privado 172149 Bacharelado ... 0 3 Estados Unidos <=50K.. ... ... ... ... ... ... ... ... ...995 2 NaN 208938 Bacharelado ... 0 1 Estados Unidos <= 50K996 2 Privado 166416 Bacharelado ... 2 2 Estados Unidos <=50K997 2 NaN 336022 HS-grad ... 0 1 Estados Unidos <=50K998 3 Privado 198051 Masters ... 0 2 Estados Unidos >50K999 1 NaN 41973 HS-grad ... 0 2 Estados Unidos <= 50K[1000 linhas x 15 colunas]
CTGAN: Modelagem de dados tabulares usando GAN condicional
C3-TGAN: C3-TGAN- Síntese de dados tabulares controláveis com correlações explícitas e restrições de propriedade
TVAE: Modelagem de dados tabulares usando GAN condicional
table-GAN:Síntese de dados baseada em redes adversárias generativas
CTAB-GAN:CTAB-GAN: Sintetização Eficaz de Dados de Tabela
OCT-GAN: OCT-GAN: GANs tabulares condicionais baseados em ODE neurais
O projeto ODS foi iniciado pelo Instituto de Segurança de Dados do Harbin Institute of Technology . Se você estiver interessado em nosso projeto, seja bem-vindo para se juntar à nossa comunidade. Damos as boas-vindas a organizações, equipes e indivíduos que compartilham nosso compromisso com a proteção e segurança de dados por meio de código aberto:
Leia CONTRIBUTING antes de elaborar uma solicitação pull.
Envie um problema visualizando Visualizar primeiro problema válido ou envie uma solicitação pull.
Junte-se ao nosso Grupo Wechat através do código QR.