Adding Private Data to LLMs
1.0.0
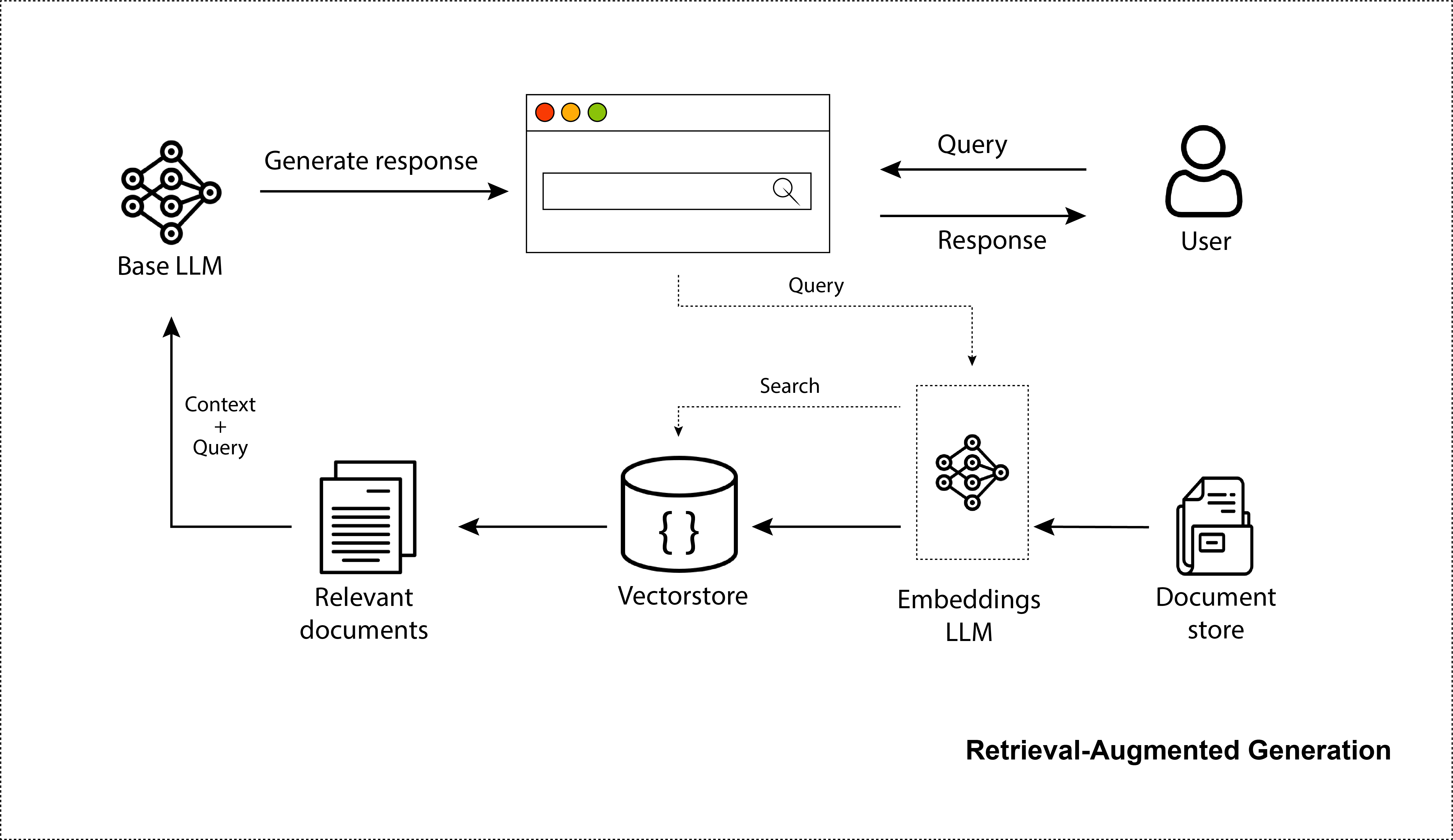
Os LLMs surpreenderam o mundo com sua capacidade de criar imagens, códigos e diálogos realistas. Sem dúvida, o ChatGPT conquistou o mundo. Milhões estão usando isso. Mas embora seja ótimo para conhecimento de uso geral, ele conhece apenas as informações nas quais foi treinado, que são dados da Internet geralmente disponíveis antes de 2021. Falta-lhe conhecimento dos seus dados privados e permanece desinformado sobre fontes de dados recentes. Assim, para melhorá-los nesse aspecto, podemos fornecer-lhes informações que recuperamos em uma etapa de pesquisa. Isso os torna mais factuais e proporciona uma melhor capacidade de fornecer informações atualizadas ao modelo, sem a necessidade de treinar novamente esses modelos massivos. Isso é exatamente o que é um sistema LLM de recuperação aumentada ou geração aumentada de recuperação (RAG). Na verdade, este repositório irá delinear com precisão a criação de um sistema RAG e elucidar as etapas de otimização envolvidas.
pano
Pilha de tecnologia
Instalação
Links úteis
Contato
LangChain
LhamaIndex
Azure OpenAI
Gradio
Clone o repositório Github
clone git https://github.com/zekaouinoureddine/Adding-Private-Data-to-LLMs.git
Cd de requisitos para o diretório do projeto e certifique-se de ter o Python 3 instalado, junto com as dependências necessárias.
cd Adicionando dados privados a LLMs pip instalar -r requisitos.txt
Execute o aplicativo Gradio
python rag.py
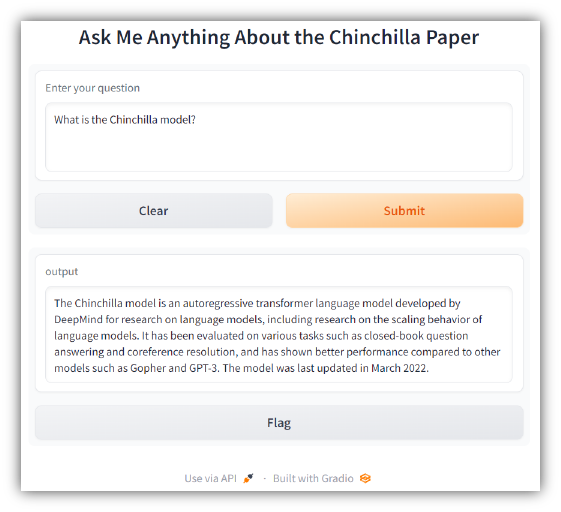
Visite http://127.0.0.1:7860 em sua máquina para testar o aplicativo. Você deverá ver algo como o seguinte:
| Blogue | Plataforma | Linguagem | Caderno |
|---|---|---|---|
| Pergunte aos seus próprios dados | Blog do Hiberus | ES | |
| Pergunte aos seus próprios dados | Médio | PT | |
| Pergunte às suas páginas da web | Blog do Hiberus | ES | |
| Pergunte às suas páginas da web | Médio | PT |
Se você gostou, dê um like e me siga em:
LinkedIn: Nour Eddine ZEKAOUI
Twitter: @NZekaoui
De volta ao topo


