wikisearch
1.0.0
Aplicativo Streamlit para pesquisa semântica multilíngue em mais de 10 milhões de documentos da Wikipedia vetorizados em embeddings pela Weaviate. Esta implementação é baseada no blog da Cohere ´Using LLMs for Search´ e seu caderno correspondente. Ele permite comparar o desempenho da pesquisa por palavras-chave , recuperação densa e pesquisa híbrida para consultar o conjunto de dados da Wikipedia. Ele demonstra ainda o uso do Cohere Rerank para melhorar a precisão dos resultados e do Cohere Generate para fornecer uma resposta com base nos referidos resultados classificados.
A pesquisa semântica refere-se a algoritmos de pesquisa que consideram a intenção e o significado contextual das frases de pesquisa ao gerar resultados, em vez de focar apenas na correspondência de palavras-chave. Ele fornece resultados mais precisos e relevantes ao compreender a semântica, ou significado, por trás da consulta.
Uma incorporação é um vetor (lista) de números de ponto flutuante que representa dados como palavras, frases, documentos, imagens ou áudio. A referida representação numérica captura o contexto, a hierarquia e a semelhança dos dados. Eles podem ser usados para tarefas posteriores, como classificação, agrupamento, detecção de valores discrepantes e pesquisa semântica.
Bancos de dados vetoriais, como o Weaviate, são desenvolvidos especificamente para otimizar recursos de armazenamento e consulta para incorporações. Na prática, um banco de dados vetorial usa uma combinação de diferentes algoritmos que participam da pesquisa por vizinho mais próximo aproximado (ANN). Esses algoritmos otimizam a pesquisa por meio de hashing, quantização ou pesquisa baseada em gráfico.
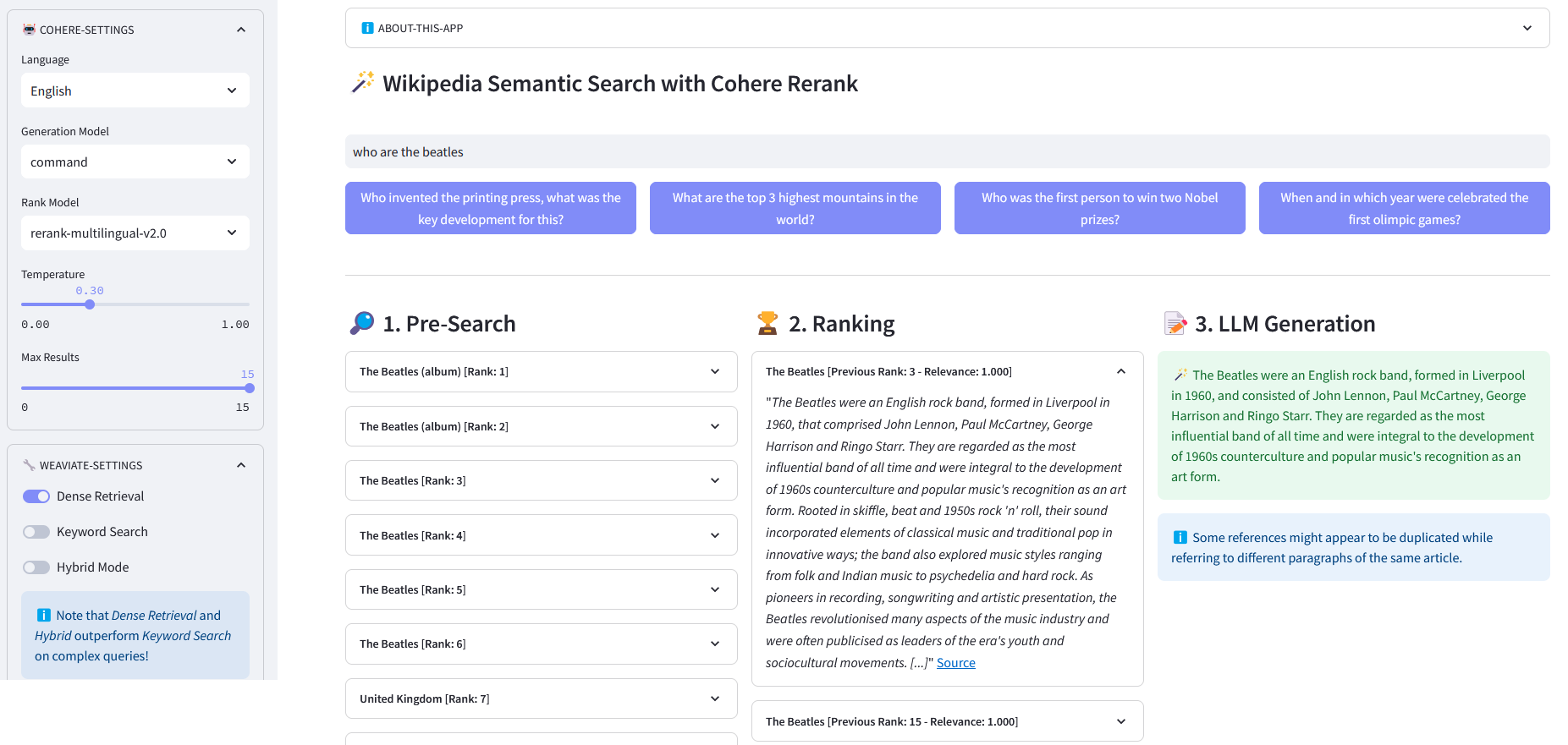
Pré-pesquisa : pré-pesquisa em embeddings da Wikipedia com correspondência de palavras-chave , recuperação densa ou pesquisa híbrida :
Keyword Matching: procura objetos que contenham os termos de pesquisa em suas propriedades. Os resultados são pontuados de acordo com a função BM25F:
@retry(wait=wait_random_exponencial(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" Executa uma palavra-chave pesquisa (recuperação esparsa) em artigos da Wikipedia usando embeddings armazenados no Weaviate Parâmetros: - query (str): A consulta de pesquisa. (str, opcional): O idioma dos artigos padrão é 'en' - top_n (int, opcional): O número dos principais resultados a serem retornados. pontuação. """logging.info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Artigos", self.WIKIPEDIA_PROPERTIES)
.with_bm25(consulta=consulta)
.with_where(where_filter)
.com_limit(top_n)
.fazer()
)resposta de retorno["dados"]["Obter"]["Artigos"]Recuperação densa: encontre objetos mais semelhantes a um texto bruto (não vetorizado):
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" Executa uma semântica pesquisa (recuperação densa) em artigos da Wikipedia usando embeddings armazenados no Weaviate Parâmetros: - query (str): A consulta de pesquisa. (str, opcional): O idioma dos artigos padrão é 'en' - top_n (int, opcional): O número dos principais resultados a serem retornados. semelhança. """logging.info("with_neartext()")nearText = {"conceitos": [consulta]
}where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Artigos", self.WIKIPEDIA_PROPERTIES)
.with_near_text(pertoTexto)
.with_where(where_filter)
.com_limit(top_n)
.fazer()
)retornar resposta['dados']['Obter']['Artigos']Pesquisa híbrida: produz resultados com base em uma combinação ponderada de resultados de uma pesquisa por palavra-chave (bm25) e uma pesquisa vetorial.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" Executa um híbrido pesquise artigos da Wikipedia usando embeddings armazenados no Weaviate. Parâmetros: - query (str): A consulta de pesquisa. - lang (str, opcional): O idioma da pesquisa. articles. O padrão é 'en' - top_n (int, opcional): O número dos principais resultados a serem retornados. O padrão é 10. Retorna: - list: Lista dos principais artigos com base na pontuação híbrida. with_hybrid()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Artigos", self.WIKIPEDIA_PROPERTIES)
.with_hybrid(consulta=consulta)
.with_where(where_filter)
.com_limit(top_n)
.fazer()
)resposta de retorno["dados"]["Obter"]["Artigos"]ReRank : Cohere Rerank reorganiza a pré-pesquisa atribuindo uma pontuação de relevância a cada resultado da pré-pesquisa dada a consulta de um usuário. Em comparação com a pesquisa semântica baseada em incorporação, ela produz melhores resultados de pesquisa – especialmente para consultas complexas e específicas de domínio.
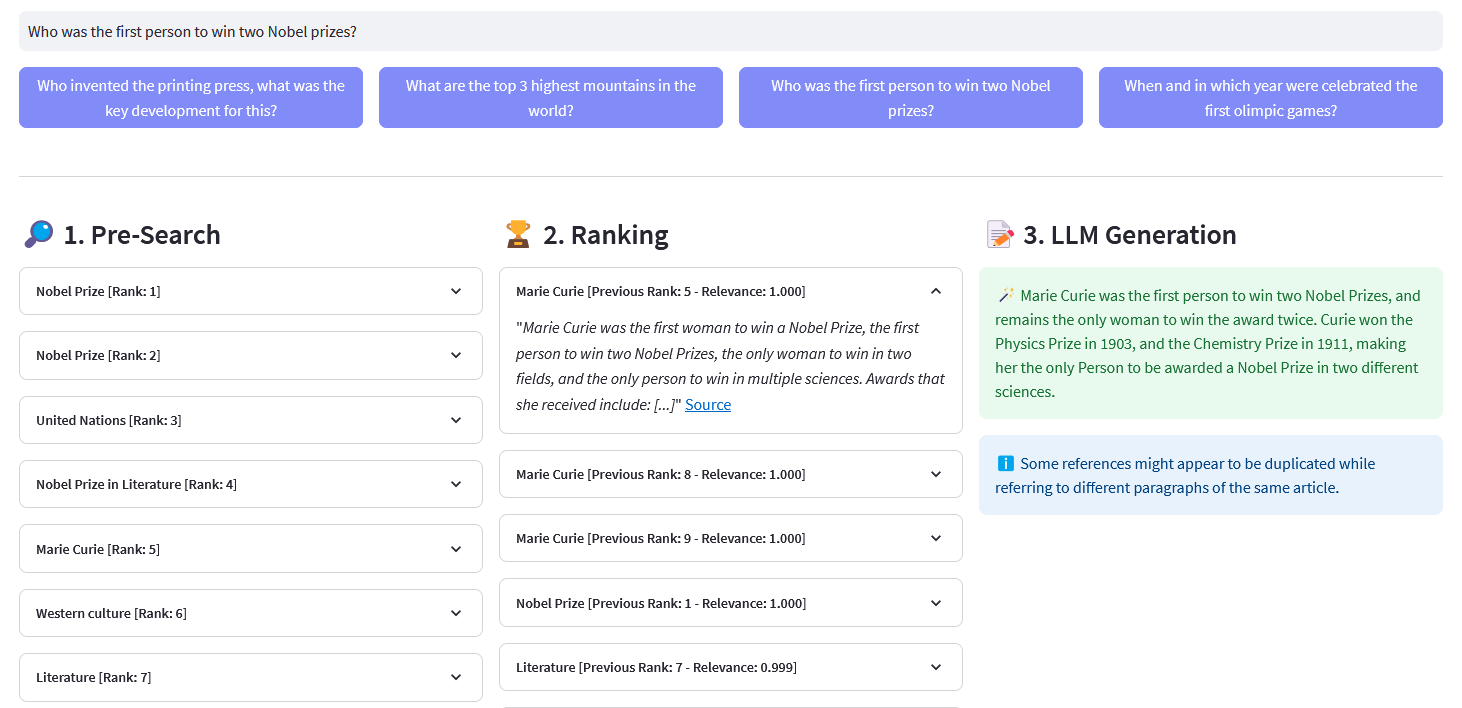
@retry(wait=wait_random_exponencial(min=1, max=5), stop=stop_after_attempt(5))def rerank(self, query,documents, top_n=10, model='rerank-english-v2.0') -> dict:""" Reclassifica uma lista de respostas usando a API de reclassificação do Cohere. Parâmetros: - query (str): A consulta de pesquisa. -documents (list): Lista de documentos a serem reclassificados - top_n (int, opcional): O número dos principais resultados reclassificados a serem retornados. - model: O modelo a ser usado para reclassificação. - dict: Documentos reclassificados da API do Cohere """return self.cohere.rerank(query=query,documents=documents, top_n=top_n, modelo=modelo)
Fonte: Cohere
Geração de resposta : Cohere Generate compõe uma resposta com base nos resultados classificados.
@retry(wait=wait_random_exponencial(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, context, query, temperature=0.2, model="command", lang="english") -> list:prompt = f""" Utilize as informações fornecidas abaixo para responder às perguntas do final. / Inclua alguns fatos curiosos ou relevantes extraídos do contexto. / Gere a resposta no idioma da consulta. Se você não conseguir determinar o idioma da consulta, use {lang} / Se a resposta à pergunta não estiver contida nas informações fornecidas, gere "A resposta não está no contexto". - Pergunta: {query} """return self.cohere.generate(prompt=prompt,num_generations=1,max_tokens=1000,temperature=temperature,model=model,
)Clone o repositório:
[email protected]:dcarpintero/wikisearch.git
Crie e ative um ambiente virtual:
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
Instale dependências:
pip install -r requirements.txt
Iniciar aplicativo da web
streamlit run ./app.py
Demo Web App implantado no Streamlit Cloud e disponível em https://wikisearch.streamlit.app/
Reclassificação Cohere
Nuvem iluminada
Os arquivos de incorporação: milhões de incorporações de artigos da Wikipédia em vários idiomas
Usando LLMs para pesquisa com recuperação densa e reclassificação
Bancos de dados vetoriais
Tecer pesquisa vetorial
Pesquisa Weaviate BM25
Tecer pesquisa híbrida


