EasyDetect
1.0.0

Uma estrutura de detecção de alucinações multimodais fácil de usar para MLLMs
Reconhecimento • Referência • Demonstração • Visão geral • ModelZoo • Instalação • Início rápido • Citação
Reconhecimento
Visão geral
Alucinação Multimodal Unificada
Conjunto de dados: estatística MHalluBench
Estrutura: Ilustração UniHD
ModeloZoo
Instalação
⏩Início rápido
Citação
2024-05-17 O artigo Unified Hallucination Detection for Multimodal Large Language Models foi aceito pela conferência principal ACL 2024.
2024-04-21 Substituímos todos os modelos básicos da demonstração por nossos próprios modelos treinados, reduzindo significativamente o tempo de inferência.
2024-04-21 Lançamos nosso modelo de detecção de alucinações de código aberto HalDet-LLAVA, que pode ser baixado em huggingface, modelscope e wisemodel.
2024-02-10 Lançamos a demonstração do EasyDetect .
2024-02-05 Lançamos o artigo:"Detecção unificada de alucinações para modelos multimodais de grandes linguagens" com um novo benchmark MHaluBench! Aguardamos quaisquer comentários ou discussões sobre este tópico :)
2023-10-20 O projeto EasyDetect foi lançado e está em desenvolvimento.
Parte da implementação deste projeto foi assistida e inspirada pelos kits de ferramentas de alucinação relacionados, incluindo FactTool, Woodpecker e outros. Este repositório também se beneficia do projeto público de mPLUG-Owl, MiniGPT-4, LLaVA, GroundingDINO e MAERec . Seguimos a mesma licença de código aberto e agradecemos por suas contribuições à comunidade.
EasyDetect é um pacote sistemático proposto como uma estrutura de detecção de alucinações fácil de usar para modelos multimodais de linguagem grande (MLLMs) como GPT-4V, Gemini, LlaVA em seus experimentos de pesquisa.
Um pré-requisito para a detecção unificada é a categorização coerente das principais categorias de alucinações dentro dos MLLMs. Nosso artigo examina superficialmente a seguinte Taxonomia de Alucinações de uma perspectiva unificada:


Figura 1: A detecção unificada de alucinações multimodais visa identificar e detectar alucinações conflitantes de modalidade em vários níveis, como objeto, atributo e texto de cena, bem como alucinações conflitantes de fatos tanto em imagem para texto quanto em texto para imagem geração.
Alucinação conflitante de modalidade. Às vezes, os MLLMs geram saídas que entram em conflito com entradas de outras modalidades, levando a problemas como objetos, atributos ou texto de cena incorretos. Um exemplo na Figura (a) acima inclui um MLLM que descreve imprecisamente o uniforme de um atleta, mostrando um conflito em nível de atributo devido à capacidade limitada dos MLLMs de obter um alinhamento de imagem de texto refinado.
Alucinação conflitante com fatos. Os resultados dos MLLM podem contradizer o conhecimento factual estabelecido. Os modelos de imagem para texto podem gerar narrativas que se desviam do conteúdo real ao incorporar factos irrelevantes, enquanto os modelos de texto para imagem podem produzir imagens que não reflectem o conhecimento factual contido nas instruções de texto. Estas discrepâncias sublinham a luta dos MLLMs para manter a consistência factual, representando um desafio significativo neste domínio.
A detecção unificada de alucinação multimodal requer a verificação de cada par imagem-texto a={v, x} , em que v denota a entrada visual fornecida a um MLLM ou a saída visual sintetizada por ele. Correspondentemente, x significa a resposta textual gerada pelo MLLM com base em v ou a consulta textual do usuário para sintetizar v . Dentro desta tarefa, cada x pode conter múltiplas declarações, denotadas como a para determinar se é "alucinatória" ou "não alucinatória", fornecendo uma justificativa para seus julgamentos com base na definição fornecida de alucinação. A detecção de alucinações de texto de LLMs denota um subcaso nesta configuração, onde v é nulo.
Para avançar nesta trajetória de pesquisa, apresentamos o benchmark de metaavaliação MHaluBench, que abrange o conteúdo da geração de imagem para texto e de texto para imagem, com o objetivo de avaliar rigorosamente os avanços nos detectores de alucinações multimodais. Mais detalhes estatísticos sobre o MHaluBench são fornecidos nas figuras abaixo.
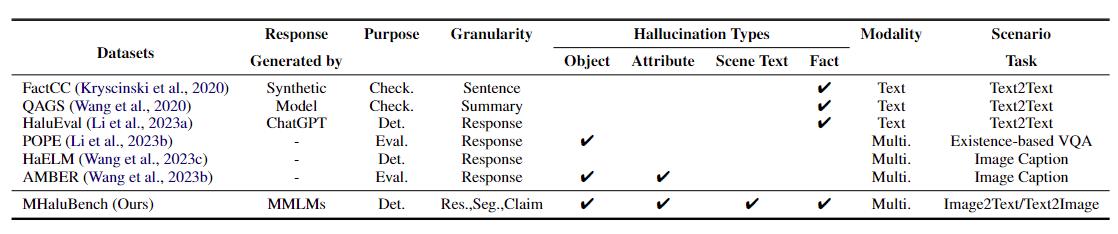
Tabela 1: Uma comparação de parâmetros de referência no que diz respeito à verificação de factos existente ou à avaliação de alucinações. "Verificar." indica verificação de consistência factual, "Eval". denota a avaliação de alucinações geradas por diferentes LLMs, e sua resposta é baseada em diferentes LLMs em teste, enquanto "Det." incorpora a avaliação da capacidade de um detector em identificar alucinações.
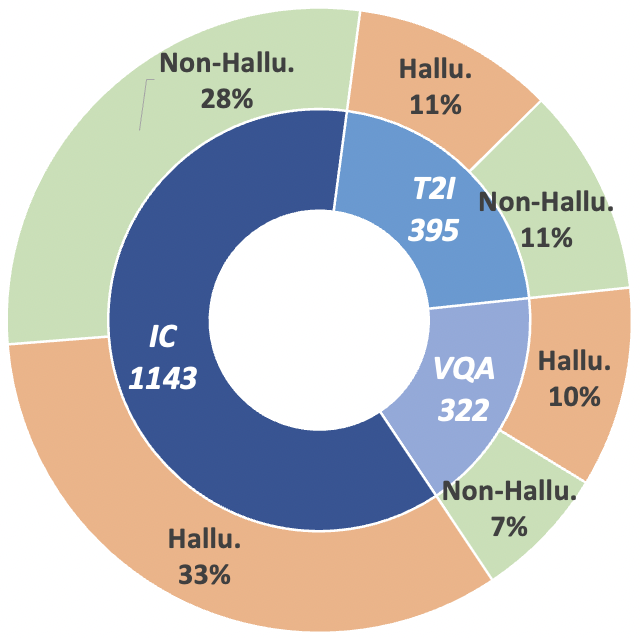
Figura 2: Estatísticas de dados em nível de reivindicação do MHaluBench. "IC" significa legenda de imagem e "T2I" indica síntese de texto para imagem, respectivamente.
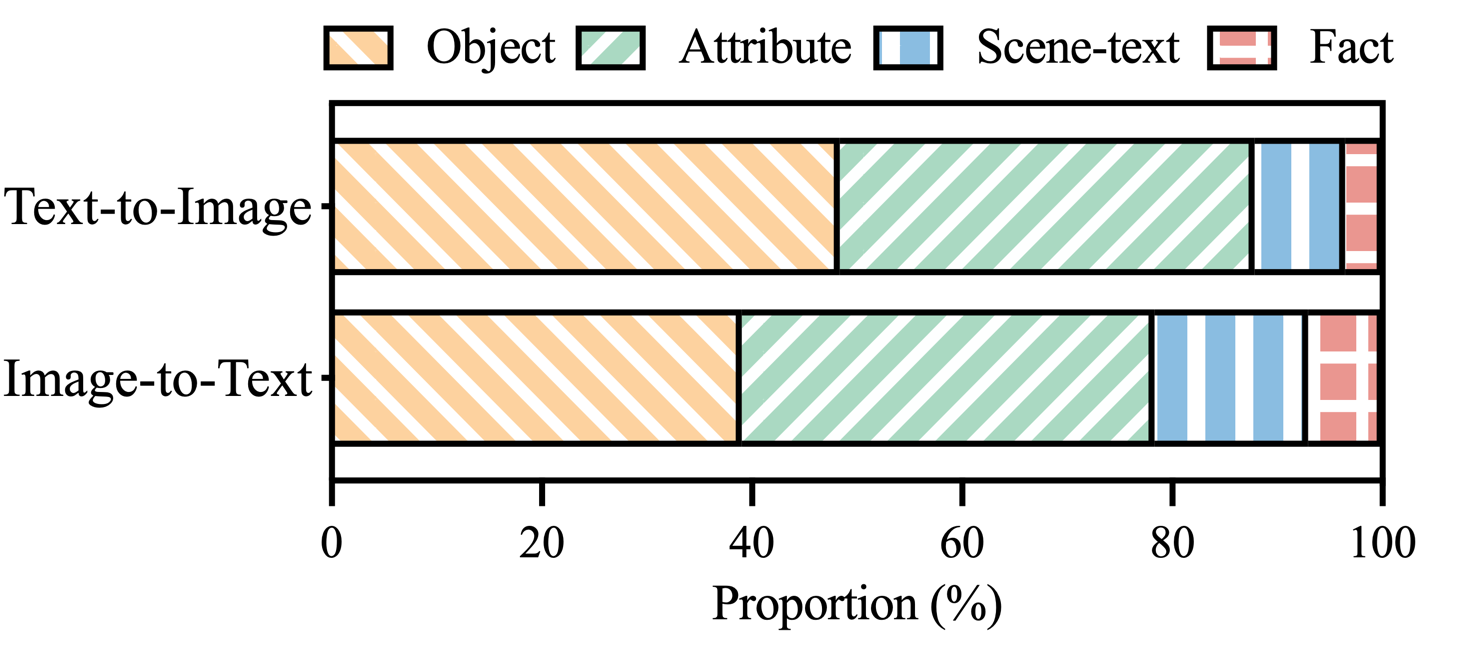
Figura 3: Distribuição de categorias de alucinações dentro das alegações rotuladas como alucinações do MHaluBench.
Abordando os principais desafios na detecção de alucinações, introduzimos uma estrutura unificada na Figura 4 que aborda sistematicamente a identificação multimodal de alucinações para tarefas de imagem para texto e de texto para imagem. Nossa estrutura aproveita os pontos fortes específicos do domínio de várias ferramentas para coletar com eficiência evidências multimodais para confirmar alucinações.
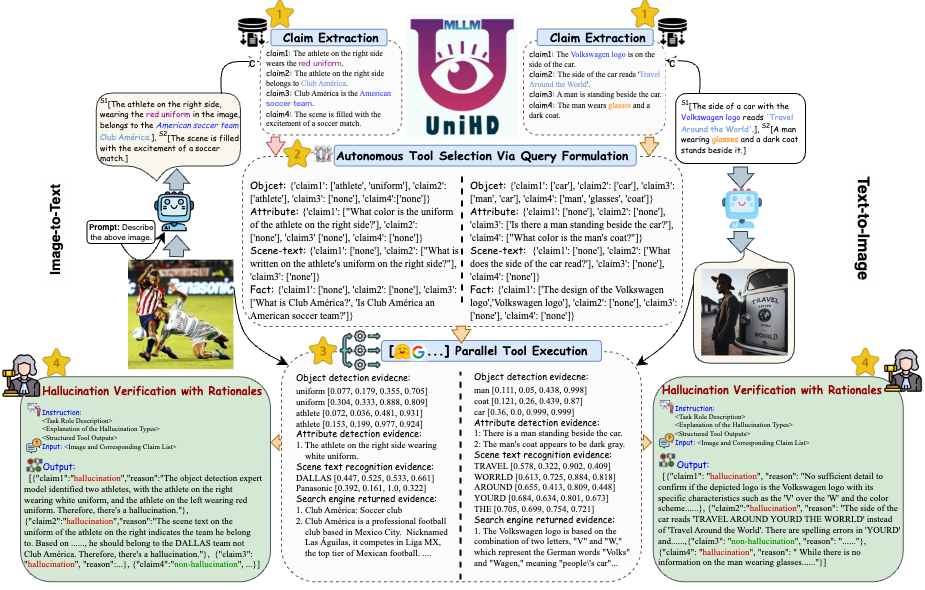
Figura 4: A ilustração específica do UniHD para detecção unificada de alucinações multimodais.
Você pode baixar duas versões do HalDet-LLaVA, 7b e 13b, em três plataformas: HuggingFace, ModelScope e WiseModel.
| Abraçando o rosto | ModelScope | Modelo Sábio |
|---|---|---|
| HalDet-llava-7b | HalDet-llava-7b | HalDet-llava-7b |
| HalDet-llava-13b | HalDet-llava-13b | HalDet-llava-13b |
Os resultados do nível de declaração no conjunto de dados de validação
Autoverificação (GPT-4V) significa usar GPT-4V com 0 ou 2 casos
UniHD (GPT-4V/GPT-4o) significa usar GPT-4V/GPT-4o com 2 disparos e informações da ferramenta
HalDet (LLAVA) significa usar LLAVA-v1.5 treinado em nossos conjuntos de dados de trem
| tipo de tarefa | modelo | conta | Média de prec. | Média de recall | Mac.F1 |
| imagem para texto | Autoverificação 0shot (GPV-4V) | 75.09 | 74,94 | 75,19 | 74,97 |
| Autoverificação 2shot (GPV-4V) | 79,25 | 79.02 | 79,16 | 79.08 | |
| HalDet (LLAVA-7b) | 75.02 | 75,05 | 74,18 | 74,38 | |
| HalDet (LLAVA-13b) | 78,16 | 78,18 | 77,48 | 77,69 | |
| UniHD(GPT-4V) | 81,91 | 81,81 | 81,52 | 81,63 | |
| UniHD (GPT-4o) | 86.08 | 85,89 | 86.07 | 85,96 | |
| texto para imagem | Autoverificação 0shot (GPV-4V) | 76,20 | 79,31 | 75,99 | 75,45 |
| Autoverificação 2shot (GPV-4V) | 80,76 | 81.16 | 80,69 | 80,67 | |
| HalDet (LLAVA-7b) | 67,35 | 69,31 | 67,50 | 66,62 | |
| HalDet (LLAVA-13b) | 74,74 | 76,68 | 74,88 | 74,34 | |
| UniHD(GPT-4V) | 85,82 | 85,83 | 85,83 | 85,82 | |
| UniHD (GPT-4o) | 89,29 | 89,28 | 89,28 | 89,28 |
Para ver informações mais detalhadas sobre HalDet-LLaVA e o conjunto de dados do trem, consulte o leia-me.
Instalação para desenvolvimento local:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
Instalação de ferramentas (GroundingDINO e MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
Fornecemos código de exemplo para os usuários começarem rapidamente a usar o EasyDetect.
Os usuários podem configurar facilmente os parâmetros do EasyDetect em um arquivo yaml ou simplesmente usar rapidamente os parâmetros padrão no arquivo de configuração que fornecemos. O caminho do arquivo de configuração é EasyDetect/pipeline/config/config.yaml
openai: api_key: Insira sua chave de API openai
base_url: Insira base_url, o padrão é Nenhum
temperatura: 0,2
max_tokens: 1024ferramenta:
detect:groundingdino_config: o caminho de GroundingDINO_SwinT_OGC.pymodel_path: o caminho de groundingdino_swint_ogc.pthdevice: cuda:0BOX_TRESHOLD: 0,35TEXT_TRESHOLD: 0,25AREA_THRESHOLD: 0,001
ocr:dbnetpp_config: o caminho de dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path: o caminho de dbnetpp.pthmaerec_config: o caminho de maerec_b_union14m.pymaerec_path: o caminho de maerec_b.pthdevice: cuda:0content: word.numbercachefiles_path: o caminho de cache_files para salvar imagens temporáriasBOX_TRESHOLD: 0,2TEXT_TRESHOLD: 0,25
google_serper:serper_api_key: Insira sua API serper keysnippet_cnt: 10prompts: Claim_generate: pipeline/prompts/claim_generate.yaml
query_generate: pipeline/prompts/query_generate.yaml
verificar: pipeline/prompts/verify.yamlCódigo de exemplo
from pipeline.run_pipeline import *pipeline = Pipeline()text = "O café na imagem se chama "Hauptbahnhof""image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response, Claim_list = pipeline .run(text=text, image_path=image_path, type=type)print(response)print(claim_list)
Por favor, cite nosso repositório se você usa EasyDetect em seu trabalho.
@artigo{chen23factchd, autor = {Xiang Chen e Duanzheng Song e Honghao Gui e Chengxi Wang e Ningyu Zhang e Jiang Yong e Fei Huang e Chengfei Lv e Dan Zhang e Huajun Chen}, título = {FactCHD: Benchmarking Fact-Conflicting Hallucination Detection }, diário = {CoRR}, volume = {abs/2310.12086}, ano = {2023}, url = {https://doi.org/10.48550/arXiv.2310.12086}, doi = {10.48550/ARXIV.2310.12086}, eprinttype = {arXiv}, eprint = {2310.12086}, biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}, bibsource = {bibliografia de ciência da computação dblp, https://dblp.org}}@inproceedings{chen-etal-2024- unified-hallucination,title = "Detecção unificada de alucinações para modelos multimodais de grandes linguagens",author = "Chen, Xiang e Wang, Chenxi e Xue, Yida e Zhang, Ningyu e Yang, Xiaoyan e Li, Qiang e Shen, Yue e Liang, Lei e Gu, Jinjie e Chen, Huajun",editor = "Ku, Lun-Wei e Martins, Andre e Srikumar, Vivek" ,booktitle = "Anais da 62ª Reunião Anual da Association for Computational Linguistics (Volume 1: Long Papers)",mês = agosto, ano = "2024",address = "Bangkok, Tailândia",publisher = "Association for Computational Linguistics",url = "https://aclanthology.org/2024.acl-long.178",pages = "3235--3252",
}Ofereceremos manutenção de longo prazo para corrigir bugs, resolver problemas e atender novas solicitações. Então, se você tiver algum problema, por favor, coloque-nos.


