xTuring
0.1.8


xTuring fornece ajuste fino rápido, eficiente e simples de LLMs de código aberto, como Mistral, LLaMA, GPT-J e muito mais. Ao fornecer uma interface fácil de usar para ajustar LLMs para seus próprios dados e aplicativos, o xTuring simplifica a construção, modificação e controle de LLMs. Todo o processo pode ser feito dentro do seu computador ou na sua nuvem privada, garantindo a privacidade e segurança dos dados.
Com xTuring você pode,
pip install xturing from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset ( "./examples/models/llama/alpaca_data" )
# Initialize the model
model = BaseModel . create ( "llama_lora" )
# Finetune the model
model . finetune ( dataset = instruction_dataset )
# Perform inference
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( "Generated output by the model: {}" . format ( output ))Você pode encontrar a pasta de dados aqui.
Temos o prazer de anunciar as melhorias mais recentes em nossa biblioteca xTuring :
LLaMA 2 - Você pode usar e ajustar o modelo LLaMA 2 em diferentes configurações: pronto para uso , pronto para uso com precisão INT8 , ajuste fino LoRA , ajuste fino LoRA com precisão INT8 e ajuste fino LoRA ajustando com precisão INT4 usando o wrapper GenericModel e/ou você pode usar a classe Llama2 de xturing.models para testar e ajustar o modelo. from xturing . models import Llama2
model = Llama2 ()
## or
from xturing . models import BaseModel
model = BaseModel . create ( 'llama2' )Evaluation – Agora você pode avaliar qualquer Causal Language Model em qualquer conjunto de dados. A métrica atualmente suportada é perplexity . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model
model = BaseModel . create ( 'gpt2' )
# Run the Evaluation of the model on the dataset
result = model . evaluate ( dataset )
# Print the result
print ( f"Perplexity of the evalution: { result } " )INT4 - Agora você pode usar e ajustar qualquer LLM com INT4 Precision usando GenericLoraKbitModel . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Run the fine-tuning
model . finetune ( dataset ) # Make the necessary imports
from xturing . models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel . create ( "llama2_int8" )
# Once the model has been quantized, do inferences directly
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( output ) # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Generate outputs on desired prompts
outputs = model . generate ( dataset = dataset , batch_size = 10 )Uma exploração do exemplo de trabalho do Llama LoRA INT4 é recomendada para uma compreensão de sua aplicação.
Para obter uma visão mais ampla, considere examinar o exemplo funcional do GenericModel disponível no repositório.

$ xturing chat -m " <path-to-model-folder> "
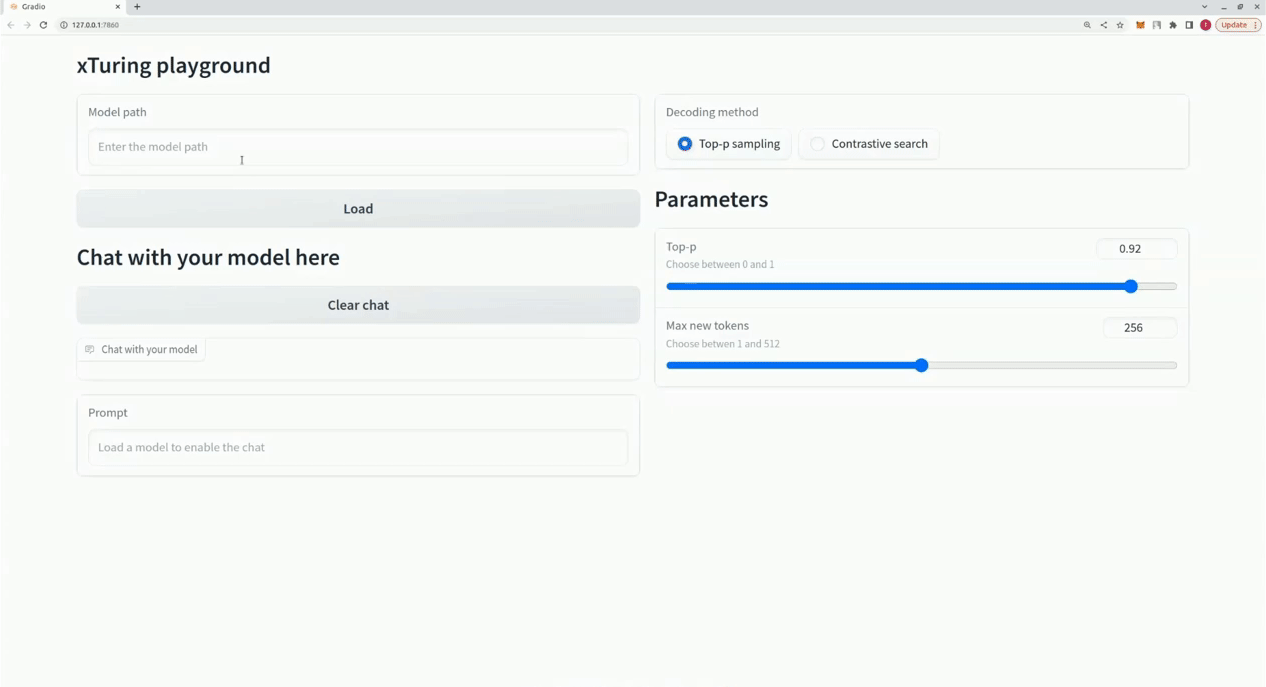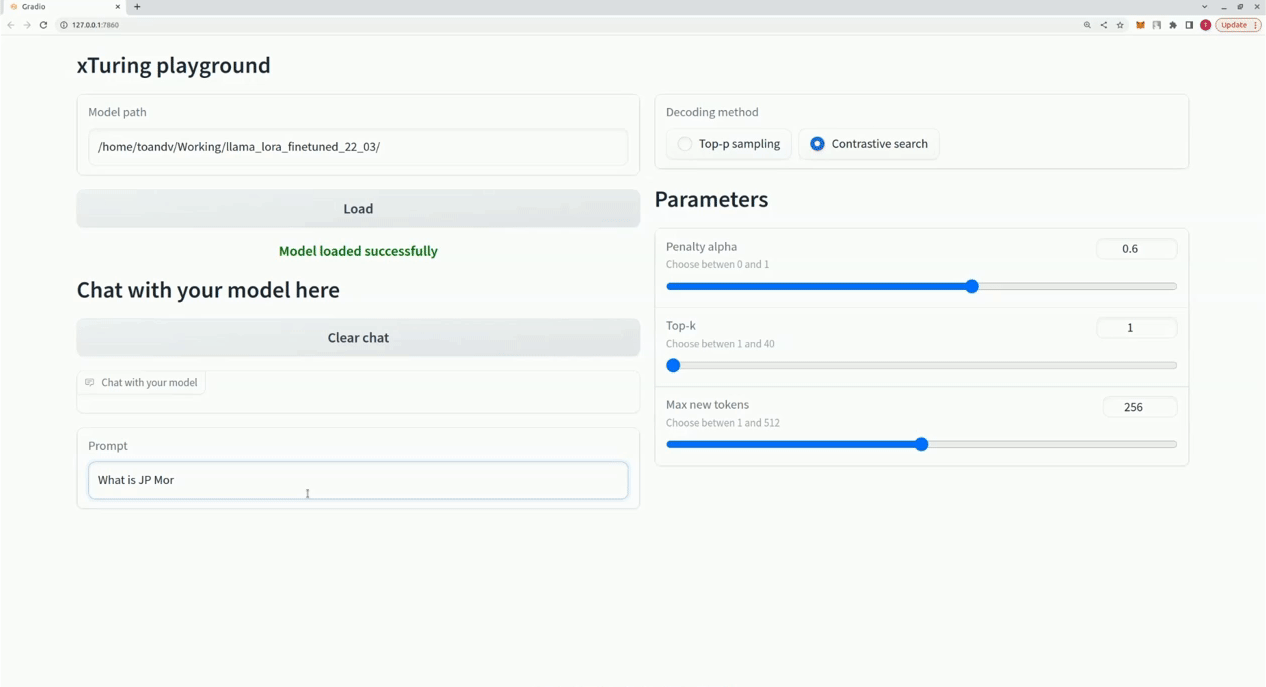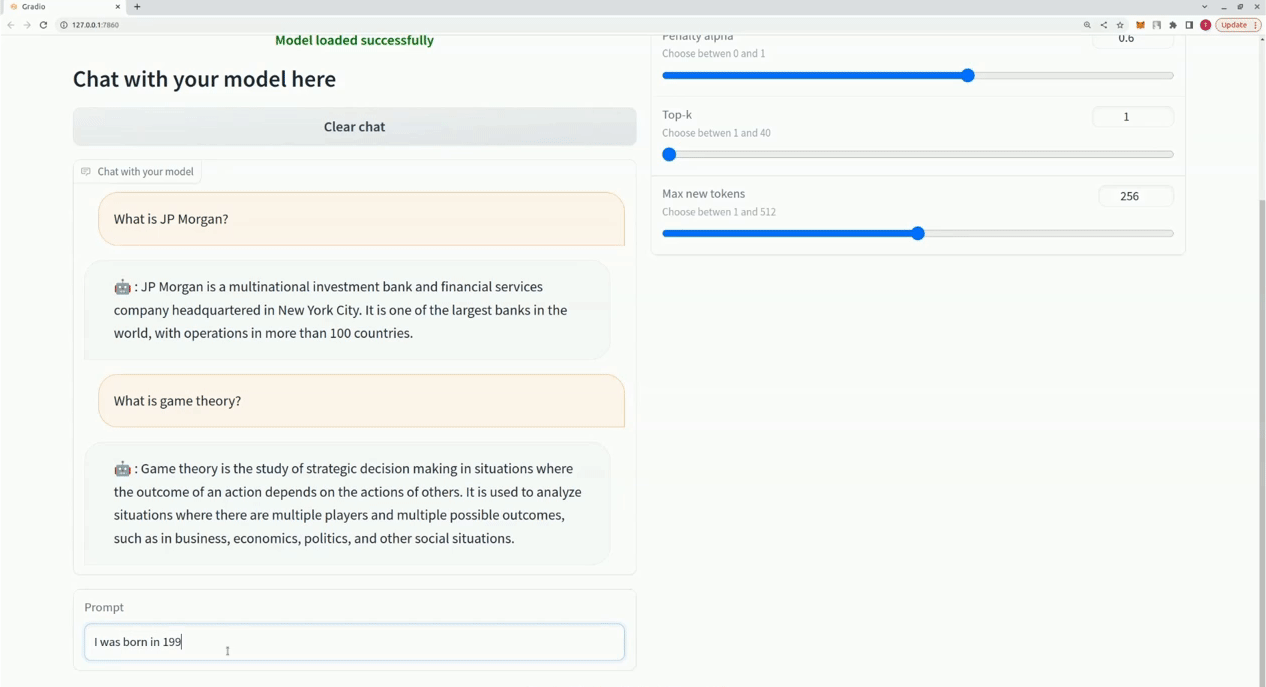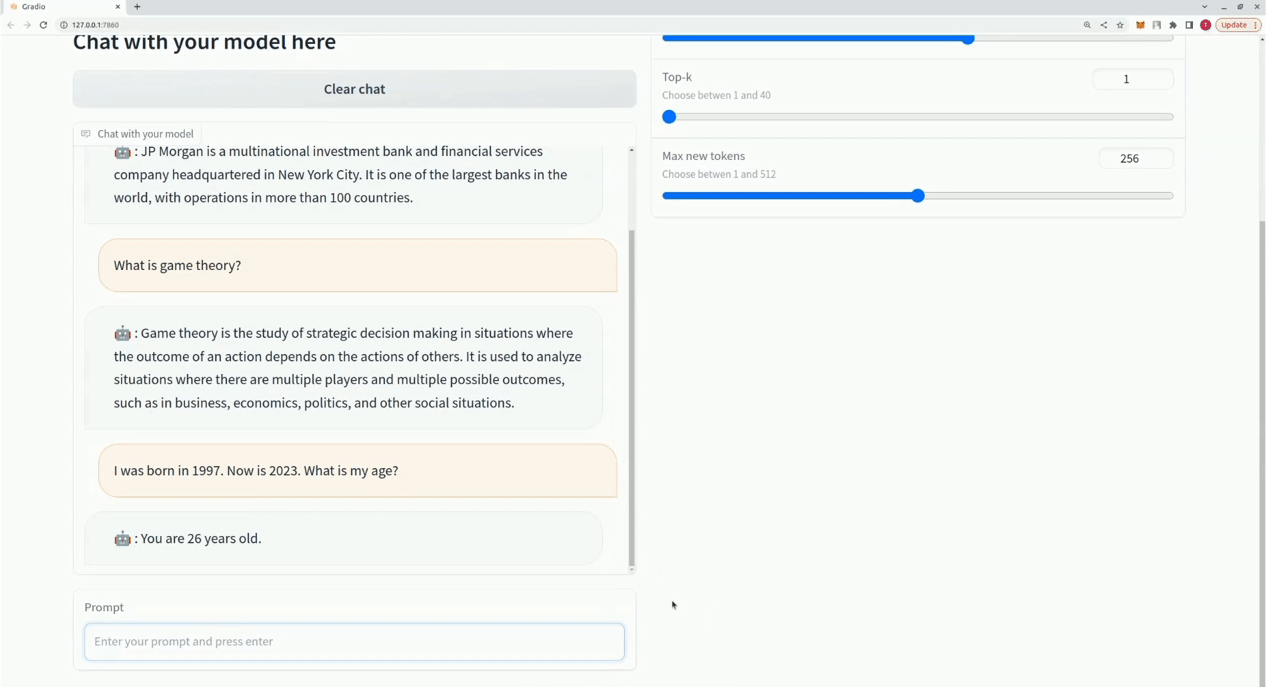
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
from xturing . ui import Playground
dataset = InstructionDataset ( "./alpaca_data" )
model = BaseModel . create ( "<model_name>" )
model . finetune ( dataset = dataset )
model . save ( "llama_lora_finetuned" )
Playground (). launch () ## launches localhost UI Aqui está uma comparação do desempenho de diferentes técnicas de ajuste fino no modelo LLaMA 7B. Usamos o conjunto de dados Alpaca para ajuste fino. O conjunto de dados contém instruções de 52 mil.
Hardware:
GPU 4xA100 de 40 GB, CPU de 335 GB de RAM
Parâmetros de ajuste fino:
{
'maximum sequence length' : 512 ,
'batch size' : 1 ,
}| LLaMA-7B | DeepSpeed + descarregamento de CPU | LoRA + DeepSpeed | LoRA + DeepSpeed + descarregamento de CPU |
|---|---|---|---|
| GPU | 33,5GB | 23,7GB | 21,9GB |
| CPU | 190 GB | 10,2GB | 14,9GB |
| Tempo/época | 21 horas | 20 minutos | 20 minutos |
Contribua para isso enviando seus resultados de desempenho em outras GPUs, criando um problema com suas especificações de hardware, consumo de memória e tempo por época.
Já ajustamos alguns modelos que você pode usar como base ou começar a brincar. Aqui está como você os carregaria:
from xturing . models import BaseModel
model = BaseModel . load ( "x/distilgpt2_lora_finetuned_alpaca" )| modelo | conjunto de dados | Caminho |
|---|---|---|
| DistilGPT-2 LoRA | alpaca | x/distilgpt2_lora_finetuned_alpaca |
| LLaMA LoRA | alpaca | x/llama_lora_finetuned_alpaca |
Abaixo está uma lista de todos os modelos suportados através da classe BaseModel do xTuring e suas chaves correspondentes para carregá-los.
| Modelo | Chave |
|---|---|
| Florescer | florescer |
| Cérebros | cérebros |
| DestilGPT-2 | destilgpt2 |
| Falcão-7B | falcão |
| Galáctica | galáctica |
| GPT-J | gptj |
| GPT-2 | gpt2 |
| Lhama | lhama |
| LhamA2 | lhama2 |
| OPT-1.3B | optar |
Os mencionados acima são as variantes básicas dos LLMs. Abaixo estão os modelos para obter suas versões LoRA , INT8 , INT8 + LoRA e INT4 + LoRA .
| Versão | Modelo |
|---|---|
| LoRA | <model_key>_lora |
| INT8 | <model_key>_int8 |
| INT8 + LoRA | <model_key>_lora_int8 |
** Para carregar a versão INT4+LoRA de qualquer modelo, você precisará fazer uso da classe GenericLoraKbitModel de xturing.models . Abaixo está como usá-lo:
model = GenericLoraKbitModel ( '<model_path>' ) O model_path pode ser substituído por seu diretório local ou qualquer modelo de biblioteca HuggingFace como facebook/opt-1.3b .
LLaMA , GPT-J , GPT-2 , OPT , Cerebras-GPT , Galactica e Bloom Generic model Falcon-7B Se você tiver alguma dúvida, você pode criar um problema neste repositório.
Você também pode ingressar em nosso servidor Discord e iniciar uma discussão no canal #xturing .
Este projeto está licenciado sob a Licença Apache 2.0 - consulte o arquivo LICENSE para obter detalhes.
Como um projeto de código aberto em um campo em rápida evolução, aceitamos contribuições de todos os tipos, incluindo novos recursos e melhor documentação. Leia nosso guia de contribuição para saber como você pode se envolver.


