Combinando algoritmos de classificação para prever o vencedor de cada jogo profissional de beisebol
Kyle Johnson
Postagem do blog: https://kylejohnson363.github.io/sourcing_mlb_data
A capacidade de prever o futuro, mesmo que apenas um pouco melhor do que jogar uma moeda ao ar, pode ser extremamente lucrativa. Sem ter uma bola de cristal, a próxima melhor coisa que podemos fazer é aproveitar o poder de grandes conjuntos de dados para encontrar padrões ocultos que podem ser usados para dar uma ligeira vantagem na realização de grandes quantidades de previsões. O beisebol é perfeitamente adequado para isso porque praticamente tudo o que acontece é quantificável e se repete centenas de vezes por jogo e cada jogo é repetido milhares de vezes por ano. O objetivo deste projeto é usar técnicas de aprendizado de máquina para fazer previsões sobre os jogos da Major League Baseball de uma forma que seja melhor do que as casas de apostas de Vegas. Ser capaz de prever 70% dos jogos corretamente não adianta se Vegas também previu esses mesmos jogos corretamente; para ter um modelo útil, devo criar um que ganhe dinheiro de forma consistente ao apostar contra casas de apostas de Vegas.
Consulte o caderno intitulado "Summary_Start_Here" para obter um roteiro detalhado deste projeto para compreender totalmente o processo.
Os dados para este projeto foram obtidos da API da MLB Advanced Media, baseball-reference.com e sportsbookreviewonline.com e depois pré-processados em um formato útil. Foram então criados e otimizados quatro modelos de classificação, que utilizaram um procedimento de votação para fazer uma previsão final. 
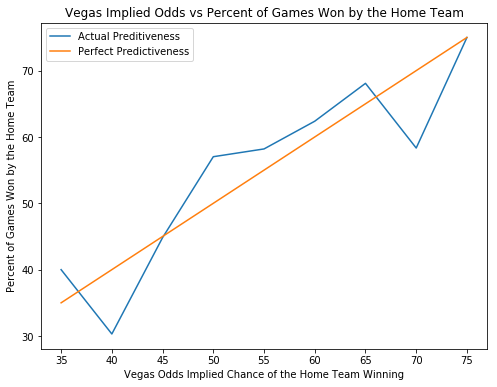
A referência de desempenho para este projeto são as previsões criadas pelos criadores de probabilidades de Vegas. Se o modelo criado consegue ganhar dinheiro apostando contra Vegas, então sabemos que o modelo agrega valor. Abaixo está um gráfico que mostra a relação entre a confiança que Vegas tem em uma previsão e a porcentagem de tempo em que a previsão está correta. As linhas laranja e azul estão bastante correlacionadas, o que significa que Vegas é muito bom em prever jogos, o que faz sentido porque, caso contrário, eles estariam fora do mercado muito rapidamente.
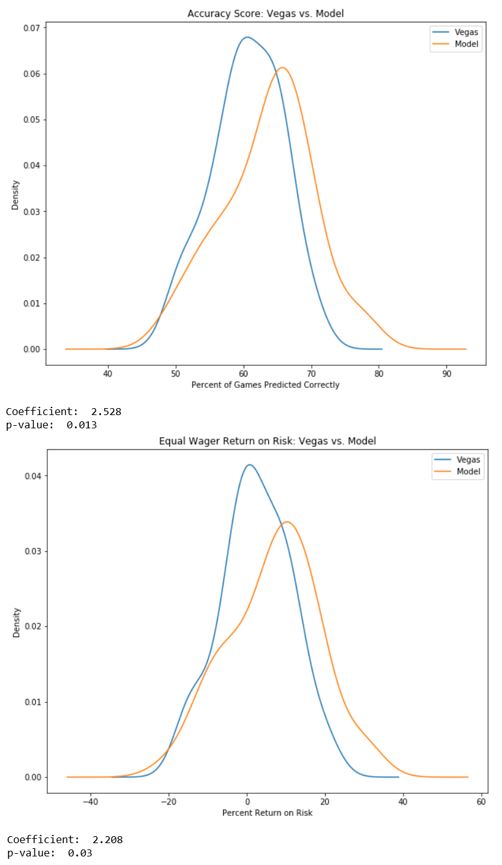
O modelo final foi capaz de superar os criadores de probabilidades de Vegas com significância estatística tanto na precisão das escolhas quanto no retorno do risco gerado pela realização de apostas nos jogos previstos.
Abaixo está uma visualização do desempenho de uma conta de apostas simulada sobre os dados fora da amostra começando com US$ 1.000.
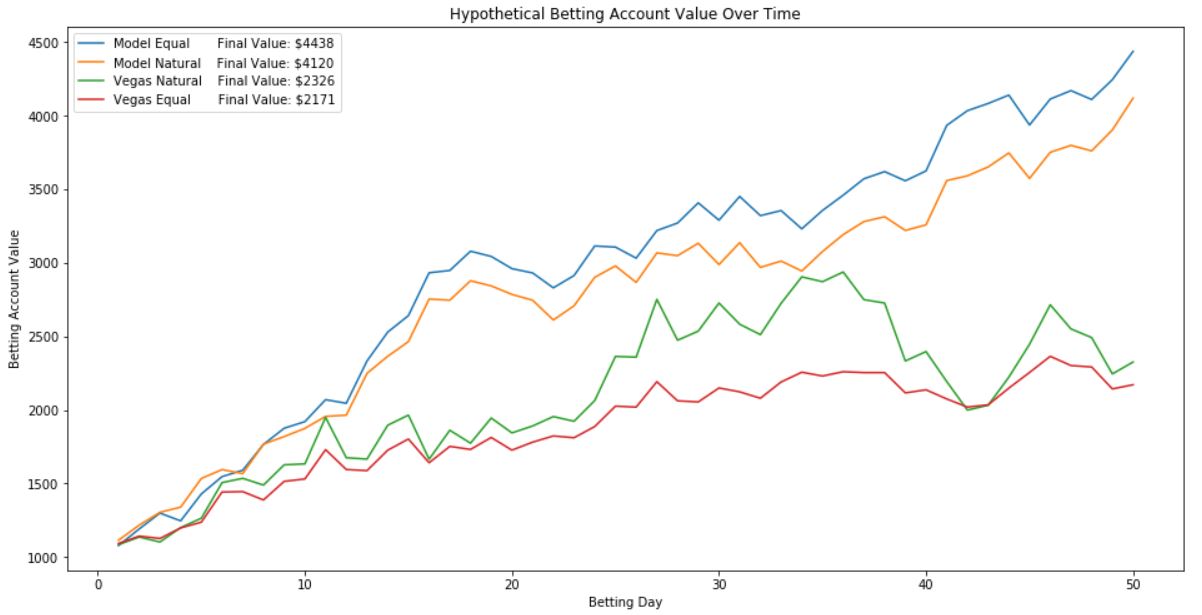
-Consegui criar um modelo que prevê jogos da MLB com mais precisão e lucratividade do que as probabilidades de Vegas de uma forma estatisticamente significativa. Fiz isso consultando dados de vários bancos de dados de beisebol on-line e, em seguida, otimizando vários modelos de classificação diferentes, antes de combiná-los para votar no resultado de cada jogo.
-Curiosamente, parece que apostar sempre com as probabilidades de Vegas é uma estratégia lucrativa, mas usar o modelo criado neste projeto é potencialmente quase duas vezes mais lucrativo. Isto nos diz que Vegas é bom em prever jogos da MLB, mas ainda existem ineficiências que podem ser exploradas.
Use mais tipos de dados (estatísticas novas e altamente avançadas) e mais jogos de temporadas anteriores.
Otimize o número de dias na categoria “recente” de estatísticas.
Automatize o processo de coleta dos dados necessários para os jogos atuais e publique um relatório sobre quais jogos apostar.
Crie "previsões menores", como corridas a serem pontuadas ou permitidas, e alimente essas previsões no modelo de classificação.


