O design de tabela cumulativa é uma ferramenta de engenharia de dados extremamente poderosa que todos os engenheiros de dados devem conhecer.
Este design produz tabelas que podem fornecer análises eficientes em intervalos de tempo arbitrariamente grandes (até milhares de dias).
Aqui está um diagrama do design do pipeline de alto nível para este padrão:
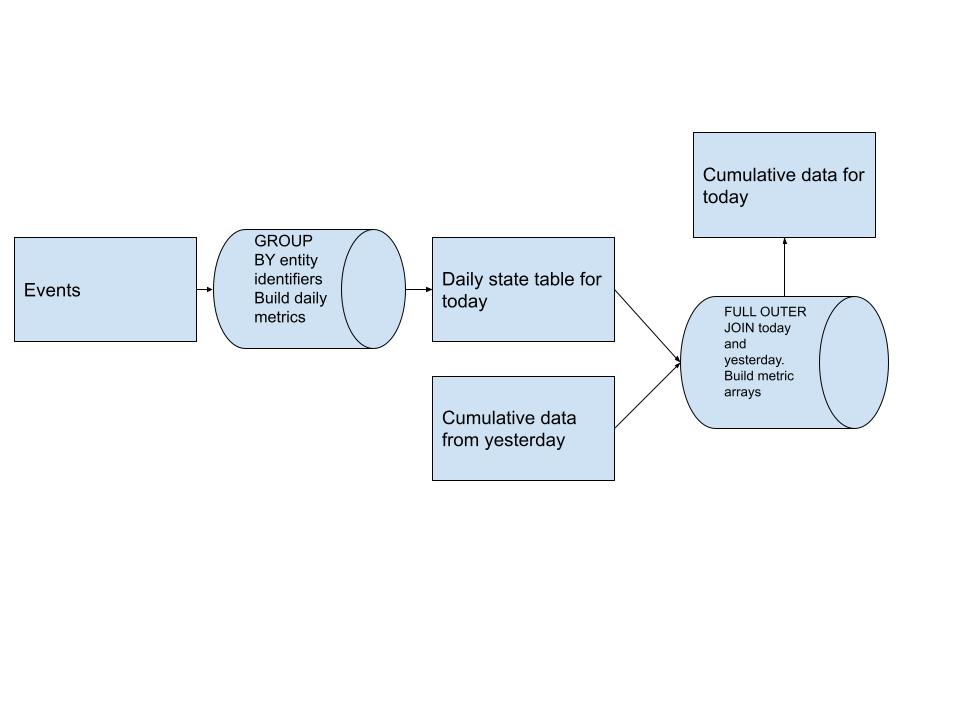
Inicialmente construímos nossa tabela de métricas diárias que é a base de qualquer que seja nossa entidade. Esses dados são derivados de quaisquer fontes de eventos que temos no upstream.
Depois de termos nossas métricas diárias, FULL OUTER JOIN a tabela cumulativa de ontem com os dados diários de hoje e construímos nossas matrizes de métricas para cada usuário. Isso nos permite trazer o novo histórico sem ter que digitalizá-lo completamente. (um grande aumento de desempenho)
Essas matrizes de métricas nos permitem responder facilmente a consultas sobre o histórico de todos os usuários usando coisas como ARRAY_SUM para calcular qualquer métrica que desejarmos em qualquer período de tempo que a matriz permitir.
Quanto maior o período de sua análise, mais crítico esse padrão se torna!!
Toda a sintaxe de consulta usa sintaxe e funções Presto/Trino. Este exemplo precisaria ser modificado para outras variantes SQL!
Usaremos as datas:
- 01/01/2022, como hoje em termos de Airflow, é
{{ ds }}- 31/12/2021 como ontem em termos de modelos do Airflow, é
{{ yesterday_ds}}
Neste exemplo, veremos como construir esse design para calcular usuários ativos diários, semanais e mensais, bem como curtidas, comentários e compartilhamentos dos usuários.
Nossa tabela de origem neste caso é events .
event_type que é like , comment , share ou viewÉ tentador pensar que a solução para isso é executar um pipeline como
SELECT
COUNT(DISTINCT user_id) as num_monthly_active_users,
COUNT(CASE WHEN event_type = 'like' THEN 1 END) as num_likes_30d,
COUNT(CASE WHEN event_type = 'comment' THEN 1 END) as num_comments_30d,
COUNT(CASE WHEN event_type = 'share' THEN 1 END) as num_shares_30d,
...
FROM events
WHERE event_date BETWEEN DATE_SUB('2022-01-01', 30), AND '2022-01-01'
O problema é que verificamos 30 dias de dados de eventos todos os dias para produzir esses números. Um pipeline bastante inútil, mas simples. Deveria haver uma maneira de verificar os dados do evento apenas uma vez e combiná-los com os resultados dos 29 dias anteriores, certo? Podemos criar uma estrutura de dados onde um cientista de dados possa consultar nossos dados e saber facilmente o número de ações que um usuário realizou nos últimos N dias?
Este design é bastante simples com apenas 3 etapas:
GROUP BY user_id e conte-os como ativos diários se houver algum eventoCOUNT(CASE WHEN event_type = 'like' THEN 1 END) para descobrir o número de curtidas, comentários e compartilhamentos diários tambémFULL OUTER JOIN esses dois conjuntos de dados em today.user_id = yesterday.user_idCOALESCE(today.user_id, yesterday.user_id) as user_id para acompanhar todos os usuáriosactivity_array . Queremos apenas que activity_array armazene os dados dos últimos 30 diasCARDINALITY(activity_array) < 30 para entender se podemos apenas adicionar o valor de hoje à frente do array ou precisamos cortar um elemento do final do array antes de adicionar o valor de hoje à frenteCOALESCE(t.is_active_today, 0) para colocar valores zero no array quando um usuário não estiver ativoactivity_array mas também para curtidas, comentários e compartilhamentos!CASE WHEN ARRAY_SUM(activity_array) > 0 THEN 1 ELSE 0 END nos fornece ativos mensais, pois limitamos o tamanho do array a 30CASE WHEN ARRAY_SUM(SLICE(activity_array, 1, 7)) > 0 THEN 1 ELSE 0 END nos dá atividade semanal, pois verificamos apenas os primeiros 7 elementos do array (ou seja, os últimos 7 dias)ARRAY_SUM(SLICE(like_array, 1, 7)) as num_likes_7d nos dá o número de curtidas que este usuário fez nos últimos 7 diasARRAY_SUM(like_array) as num_likes_30d nos dá o número de curtidas que este usuário fez nos últimos 30 dias desde que o array foi fixado nesse tamanhodepends_on_past: True

