nmt
1.0.0
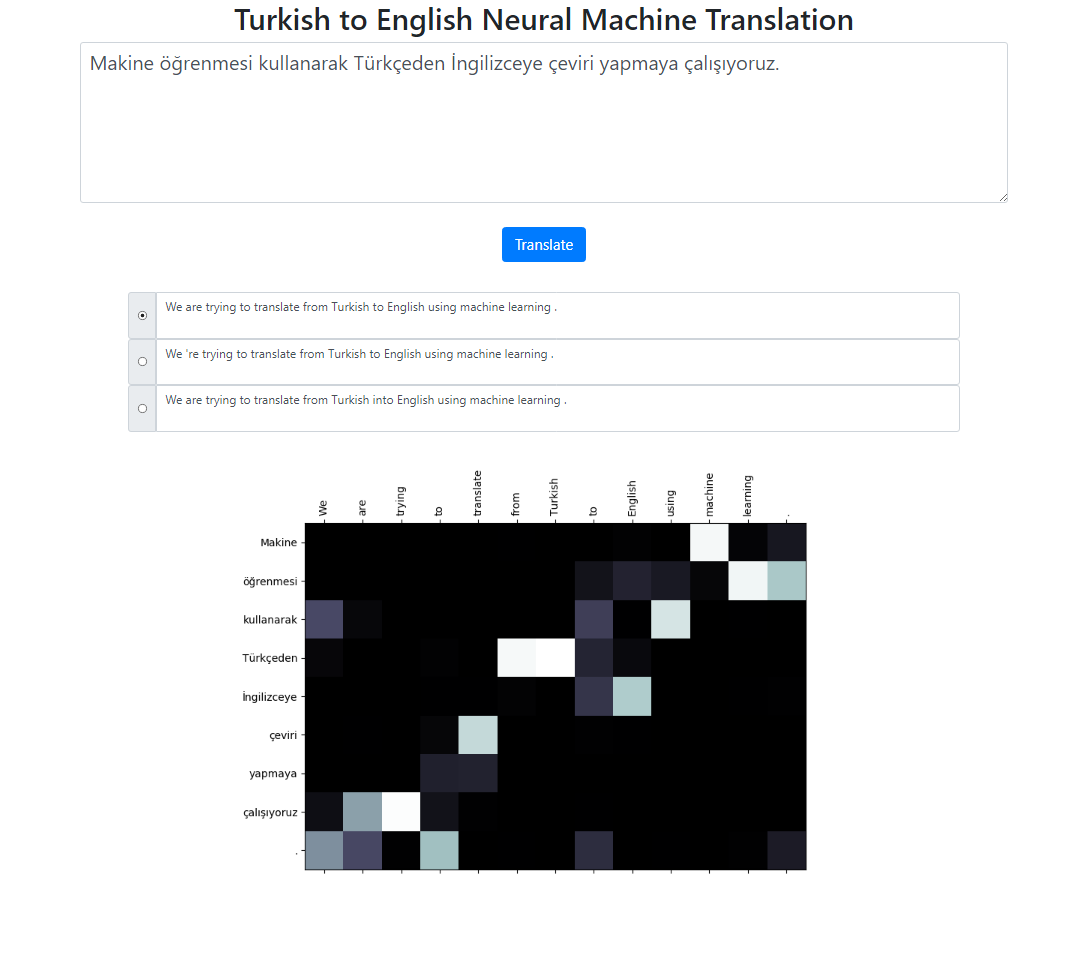
Este repositório implementa um sistema de tradução automática neural de turco para inglês usando o modelo Seq2Seq + Global Attention. Há também um aplicativo Flask que você pode executar localmente. Você pode inserir o texto, traduzir e inspecionar os resultados, bem como a visualização da atenção. Executamos a pesquisa de feixe com tamanho de feixe 3 em segundo plano e retornamos as sequências mais prováveis classificadas por sua pontuação relativa.
O conjunto de dados para este projeto foi retirado daqui. Usei o corpus Tatoeba. Excluí algumas das duplicatas encontradas nos dados. Também pretokenizei o conjunto de dados. A versão finalizada pode ser encontrada na pasta de dados.
Para tokenizar as sentenças em turco, usei o RegexpTokenizer do nltk.
puncts_except_apostrophe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_except_apostrophe}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "Titanic 15 Nisan pazartesi saat 02:20'de battı."tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# Saída: Titanic 15 Nisan pazartesi saat 02 : 20 'de battı .# Esta propriedade de divisão em "02 : 20" é diferente do tokenizer inglês.# Poderíamos lidar com essas situações. Mas eu queria mantê-lo simples e veja se # a distribuição de atenção nessas palavras está alinhada com os tokens em inglês.# Existem casos semelhantes principalmente em datas, como neste exemplo: 02/09/2019Para tokenizar as frases em inglês, usei o modelo inglês do spacy.
en_nlp = spacy.load('en_core_web_sm')text = "O Titanic afundou às 02h20 de segunda-feira, 15 de abril."tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text ]))# Resultado: O Titanic afundou às 02h20 de segunda-feira, 15 de abril.Espera-se que as frases em turco e inglês estejam em dois arquivos diferentes.
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
Execute python train.py -h para obter a lista completa de argumentos.
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
Para calcular a pontuação azul do nível do corpus.
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
Para executar o aplicativo localmente, execute:
python app.py
Certifique-se de que os caminhos do seu modelo no arquivo config.py estejam definidos corretamente.
Arquivo de modelo
Arquivo de vocabulário
Usando unidades de subpalavras (para turco e inglês)
Diferentes mecanismos de atenção (aprender diferentes parâmetros para a atenção)
O código do esqueleto para este projeto foi retirado do curso de PNL de Stanford: CS224n


