hercules
v10.7.2
Análise do histórico Git rápida, perspicaz e altamente personalizável.
Visão geral • Como usar • Instalação • Contribuições • Licença
Hercules é um mecanismo de análise de repositório Git incrivelmente rápido e altamente personalizável escrito em Go. As baterias estão incluídas. Desenvolvido por go-git.
Aviso (novembro de 2020): o autor principal volta do limbo e retoma gradativamente o desenvolvimento. Veja o roteiro.
Existem duas ferramentas de linha de comando: hercules e labours . O primeiro é um programa escrito em Go que pega um repositório Git e executa um gráfico acíclico direcionado (DAG) de tarefas de análise ao longo de todo o histórico de commits. O segundo é um script Python que mostra alguns gráficos predefinidos sobre os dados coletados. Estas duas ferramentas são normalmente usadas juntas através de um tubo. É possível escrever análises personalizadas usando o sistema de plugins. Também é possível mesclar vários resultados de análises - relevantes para as organizações. O histórico de commits analisado inclui ramificações, fusões, etc.
O Hercules foi usado com sucesso em vários projetos internos na fonte{d}. Existem postagens no blog: 1, 2 e uma apresentação. Por favor, contribua testando, corrigindo bugs, adicionando novas análises ou codificando com arrogância!
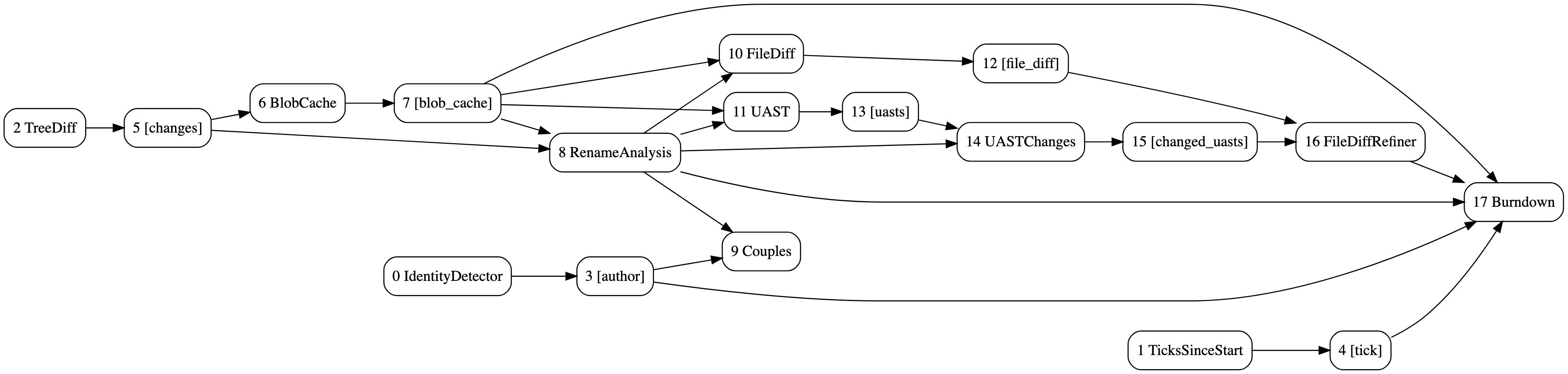
O DAG de análises de burndown e casais com refinamento diferencial UAST. Gerado com hercules --burndown --burndown-people --couples --feature=uast --dry-run --dump-dag doc/dag.dot https://github.com/src-d/hercules
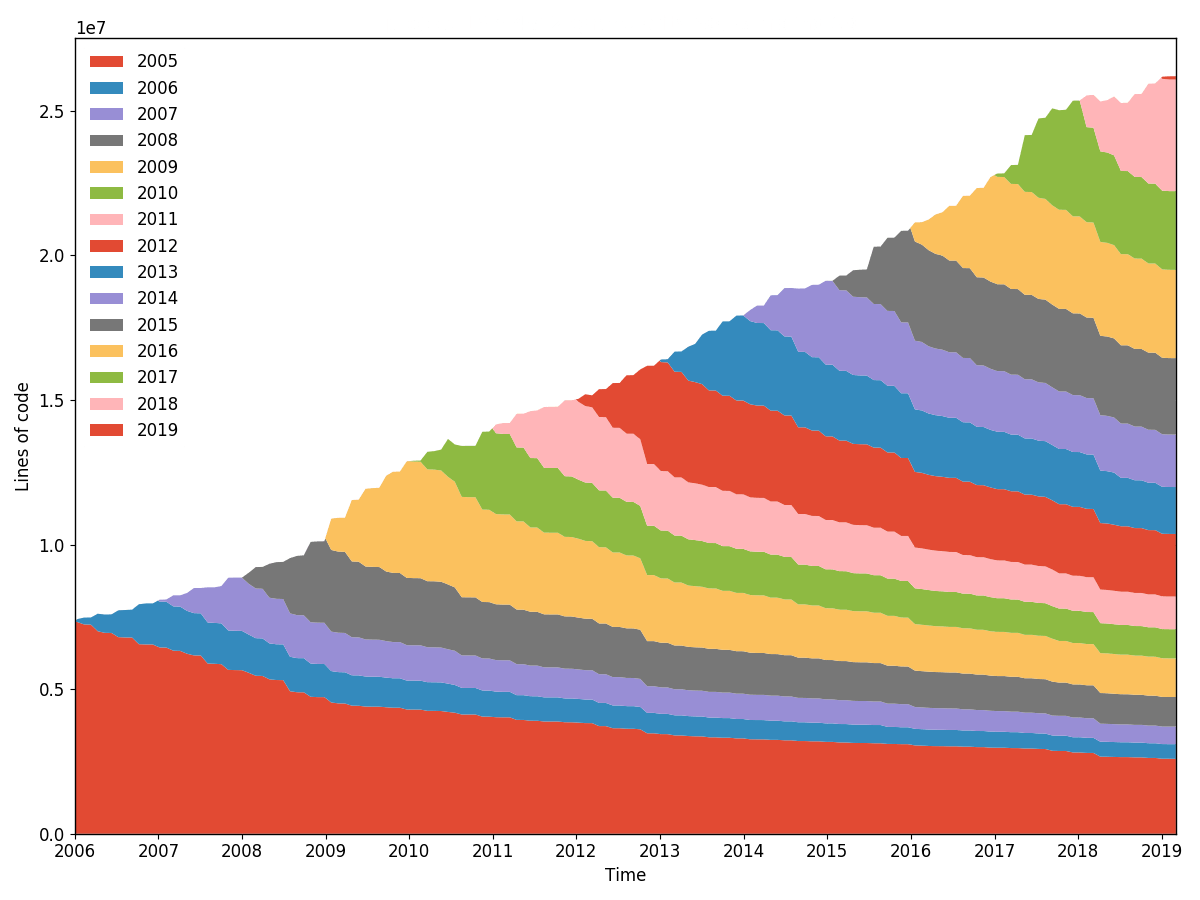
burndown da linha torvalds/linux (granularidade 30, amostragem 30, reamostrada por ano). Gerado com hercules --burndown --first-parent --pb https://github.com/torvalds/linux | labours -f pb -m burndown-project em 1h 40min.
Pegue o binário hercules na página de lançamentos. labours pode ser instalado a partir do PyPi:
pip3 install labours
pip3 é o gerenciador de pacotes Python.
Numpy e Scipy podem ser instalados no Windows usando http://www.lfd.uci.edu/~gohlke/pythonlibs/
Você vai precisar de Go (>= v1.11) e protoc .
git clone https://github.com/src-d/hercules && cd hercules
make
pip3 install -e ./python
É possível executar o Hercules como uma ação GitHub: Hercules no GitHub Marketplace. Consulte o exemplo de fluxo de trabalho que demonstra como configurar.
...são bem-vindos! Consulte CONTRIBUINDO e código de conduta.
Apache 2.0
A referência de linha de comando mais útil e confiável e atualizada:
hercules --help
Alguns exemplos:
# Use "memory" go-git backend and display the burndown plot. "memory" is the fastest but the repository's git data must fit into RAM.
hercules --burndown https://github.com/go-git/go-git | labours -m burndown-project --resample month
# Use "file system" go-git backend and print some basic information about the repository.
hercules /path/to/cloned/go-git
# Use "file system" go-git backend, cache the cloned repository to /tmp/repo-cache, use Protocol Buffers and display the burndown plot without resampling.
hercules --burndown --pb https://github.com/git/git /tmp/repo-cache | labours -m burndown-project -f pb --resample raw
# Now something fun
# Get the linear history from git rev-list, reverse it
# Pipe to hercules, produce burndown snapshots for every 30 days grouped by 30 days
# Save the raw data to cache.yaml, so that later is possible to labours -i cache.yaml
# Pipe the raw data to labours, set text font size to 16pt, use Agg matplotlib backend and save the plot to output.png
git rev-list HEAD | tac | hercules --commits - --burndown https://github.com/git/git | tee cache.yaml | labours -m burndown-project --font-size 16 --backend Agg --output git.png
labours -i /path/to/yaml permite ler a saída do hercules que foi salva no disco.
É possível armazenar o repositório clonado em disco. A análise subsequente pode ser executada no diretório correspondente em vez de clonar do zero:
# First time - cache
hercules https://github.com/git/git /tmp/repo-cache
# Second time - use the cache
hercules --some-analysis /tmp/repo-cache
A ação produz o artefato denominado hercules_charts . Como atualmente é impossível compactar vários arquivos em um artefato, todos os gráficos e arquivos do Tensorflow Projector são compactados no arquivo tar interno. Para visualizar os embeddings, acesse projetor.tensorflow.org, clique em “Carregar” e escolha os dois TSVs. Em seguida, use UMAP ou T-SNE.
docker run --rm srcd/hercules hercules --burndown --pb https://github.com/git/git | docker run --rm -i -v $(pwd):/io srcd/hercules labours -f pb -m burndown-project -o /io/git_git.png
hercules --burndown
labours -m burndown-project
Estatísticas de burndown de linha para todo o repositório. Exatamente o mesmo que o git-of-theseus faz, mas muito mais rápido. A culpa é realizada de forma eficiente e incremental usando um algoritmo de rastreamento de árvore RB personalizado, e apenas a data da última modificação é registrada durante a execução da análise.
Todas as análises de burndown dependem dos valores de granularidade e amostragem . Granularidade é o número de dias em que cada banda da pilha consiste. A amostragem é a frequência com que o estado de burnout é capturado. Quanto menor o valor, mais suave é o gráfico, mas mais trabalho é realizado.
Existe a opção de reamostrar as bandas dentro labours , para que você possa definir uma distribuição bem precisa e visualizá-la de diferentes maneiras. Além disso, a reamostragem alinha as bandas através dos limites periódicos, por exemplo, meses ou anos. As bandas não amostradas aparentemente não estão alinhadas e começam na data de nascimento do projeto.
hercules --burndown --burndown-files
labours -m burndown-file
Estatísticas de burndown para cada arquivo no repositório que está ativo na revisão mais recente.
Nota: irá gerar um gráfico separado para cada arquivo. Você não deseja executá-lo em um repositório com muitos arquivos.
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m burndown-person
Estatísticas de burndown para os contribuidores do repositório. Se --people-dict não for especificado, as identidades serão descobertas pelo seguinte algoritmo:
Se --people-dict for especificado, ele deverá apontar para um arquivo de texto com as identidades personalizadas. O formato é: cada linha é de um único desenvolvedor, contém todos os e-mails e nomes correspondentes separados por | . O caso é ignorado.
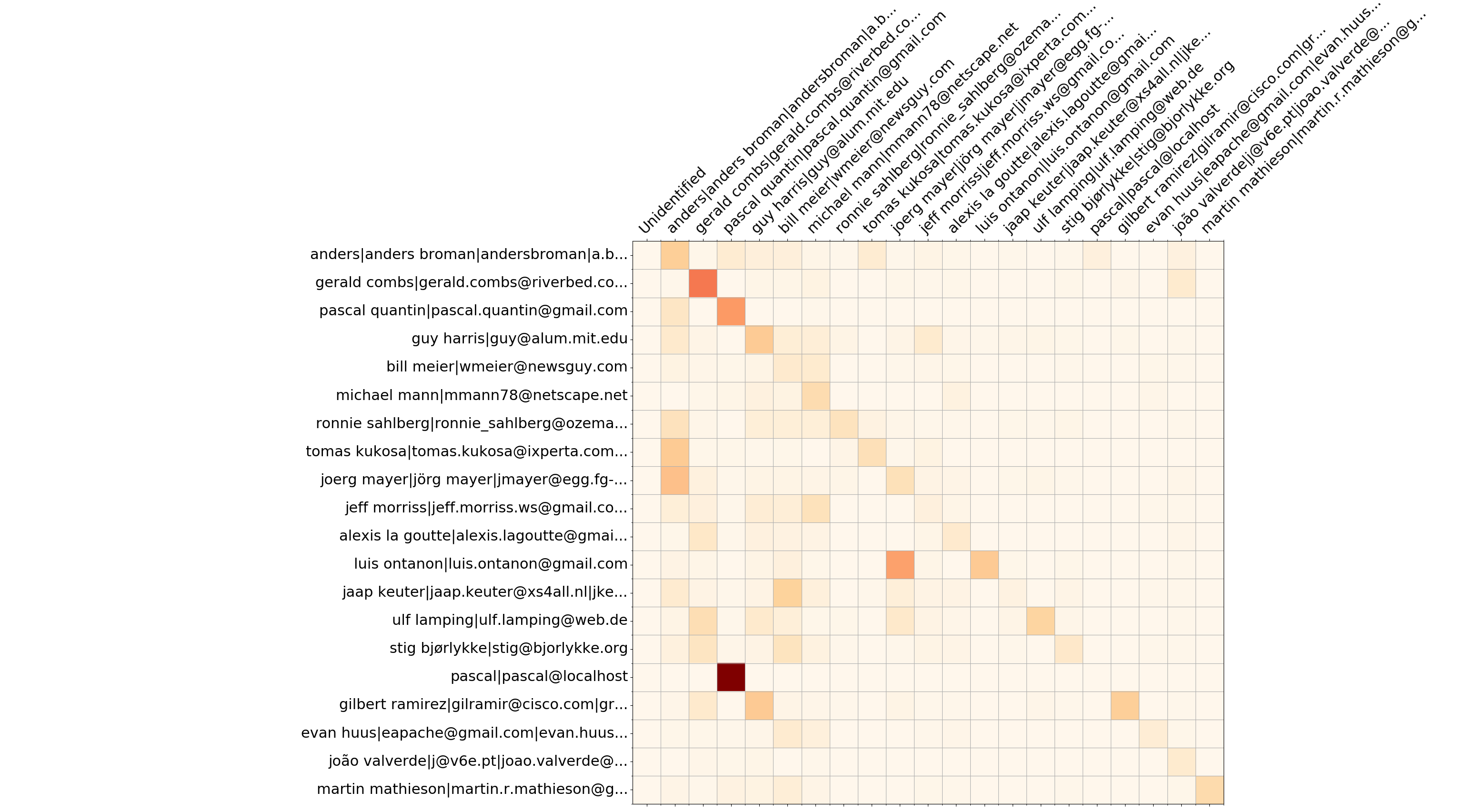
Os 20 principais desenvolvedores do Wireshark - substitui a matriz
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m overwrites-matrix
Além das informações de burndown, --burndown-people coleta as estatísticas de linhas adicionadas e excluídas por desenvolvedor. Assim pode-se visualizar quantas linhas escritas pelo desenvolvedor A são removidas pelo desenvolvedor B. Isso indica colaboração entre pessoas e define equipes de expertise.
O formato é a matriz com N linhas e (N+2) colunas, onde N é o número de desenvolvedores.
--people-dict não for especificado, será sempre 0). A sequência de desenvolvedores é armazenada no nó YAML people_sequence .
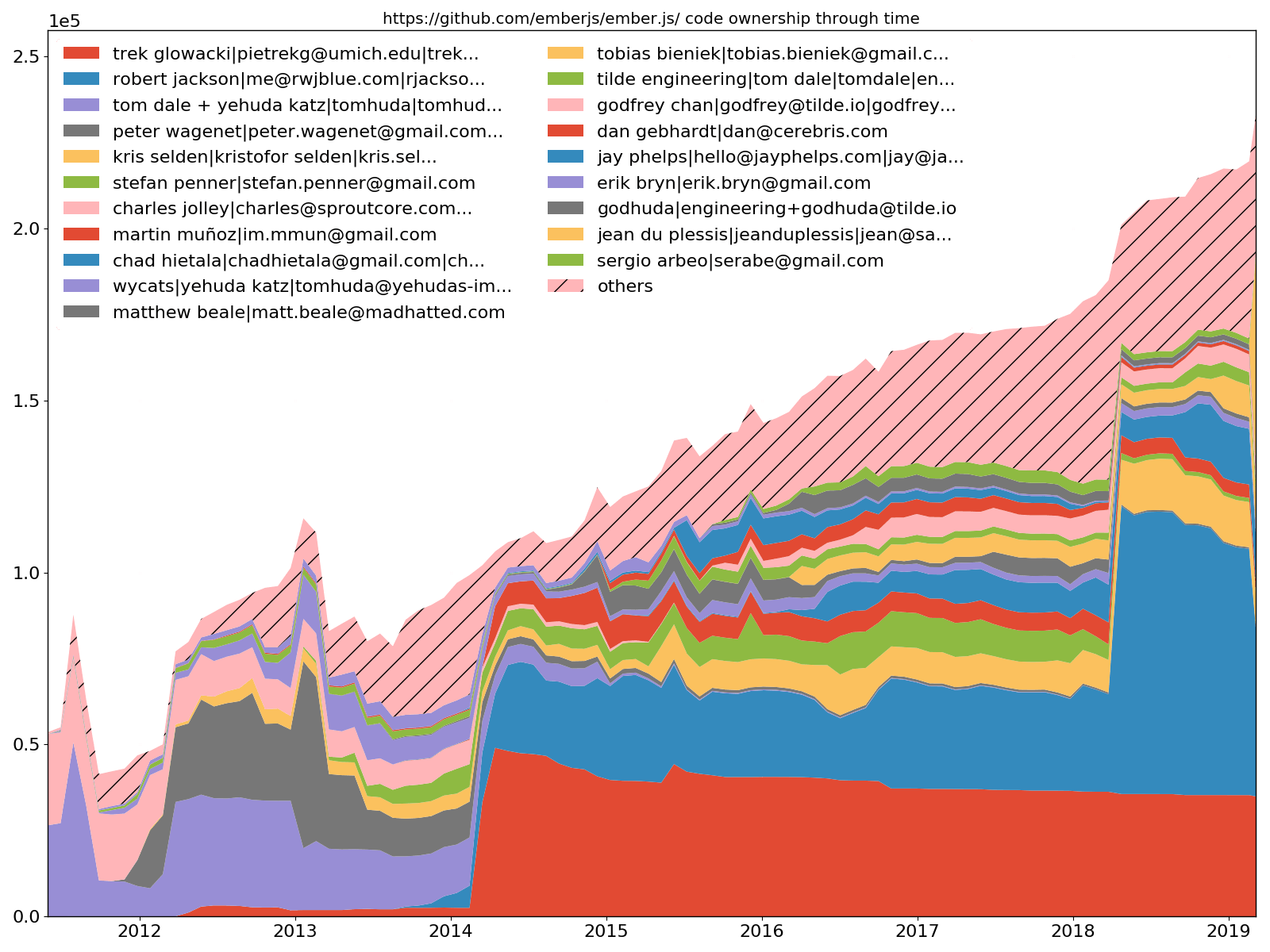
Os 20 principais desenvolvedores do Ember.js - propriedade do código
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m ownership
--burndown-people também permite desenhar o compartilhamento de código através do gráfico de área empilhada no tempo. Ou seja, quantas linhas estão ativas nos momentos amostrados para cada desenvolvedor identificado.
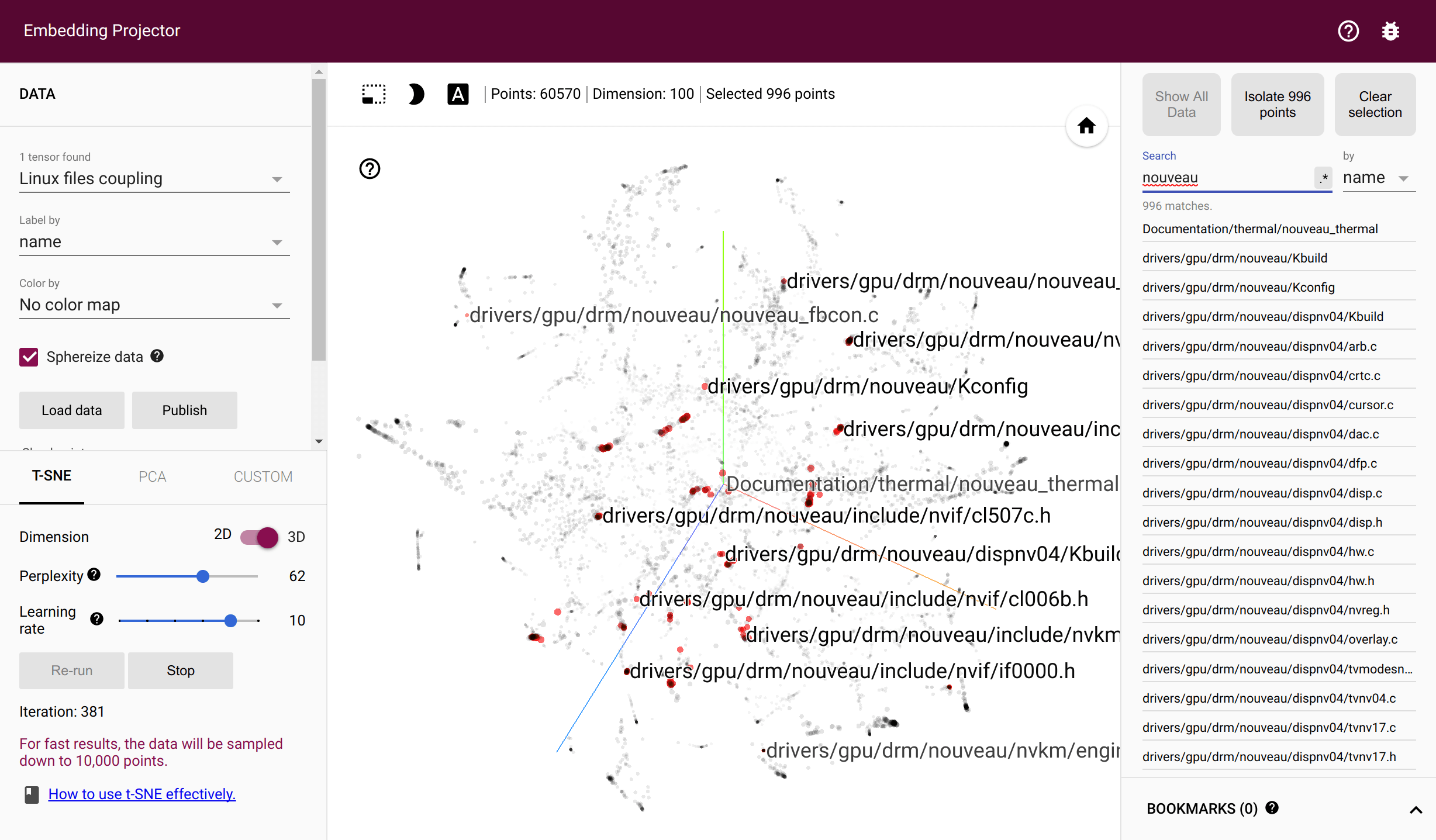
Acoplamento de arquivos torvalds/linux no Tensorflow Projector
hercules --couples [--people-dict=/path/to/identities]
labours -m couples -o <name> [--couples-tmp-dir=/tmp]
Importante : requer a instalação do Tensorflow, siga as instruções oficiais.
Os arquivos são acoplados se forem alterados no mesmo commit. Os desenvolvedores são acoplados se alterarem o mesmo arquivo. hercules registra o número de casais ao longo de todo o histórico de commits e gera as duas matrizes de co-ocorrência correspondentes. labours então treina embeddings giratórios - vetores densos que refletem a probabilidade de co-ocorrência através da distância euclidiana. O treinamento requer uma instalação funcional do Tensorflow. Os arquivos intermediários são armazenados no diretório temporário do sistema ou --couples-tmp-dir se for especificado. Os embeddings treinados são gravados no diretório de trabalho atual com o nome dependendo de -o . O formato de saída é TSV e corresponde ao Tensorflow Projector para que os arquivos e pessoas possam ser visualizados com t-SNE implementado no TF Projector.
46 jinja2/compiler.py:visit_Template [FunctionDef]
42 jinja2/compiler.py:visit_For [FunctionDef]
34 jinja2/compiler.py:visit_Output [FunctionDef]
29 jinja2/environment.py:compile [FunctionDef]
27 jinja2/compiler.py:visit_Include [FunctionDef]
22 jinja2/compiler.py:visit_Macro [FunctionDef]
22 jinja2/compiler.py:visit_FromImport [FunctionDef]
21 jinja2/compiler.py:visit_Filter [FunctionDef]
21 jinja2/runtime.py:__call__ [FunctionDef]
20 jinja2/compiler.py:visit_Block [FunctionDef]
Graças ao Babelfish, o Hercules é capaz de medir quantas vezes cada unidade estrutural foi modificada. Por padrão, ele analisa funções; consulte o manual Semantic UAST XPath para mudar para outra coisa.
hercules --shotness [--shotness-xpath-*]
labours -m shotness
A análise de casais carrega automaticamente dados de "shotness", se disponíveis.
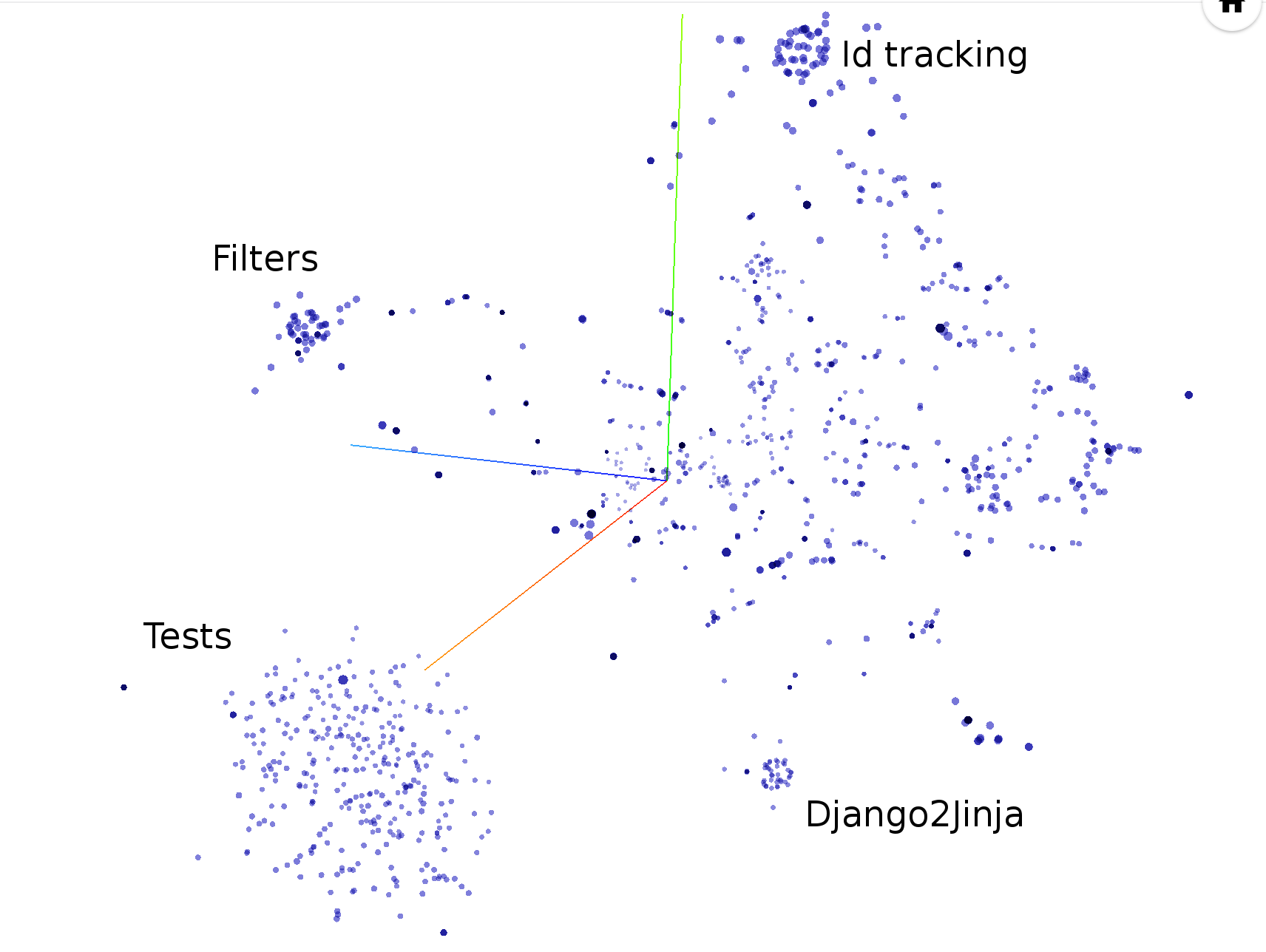
hercules --shotness --pb https://github.com/pallets/jinja | labours -m couples -f pb
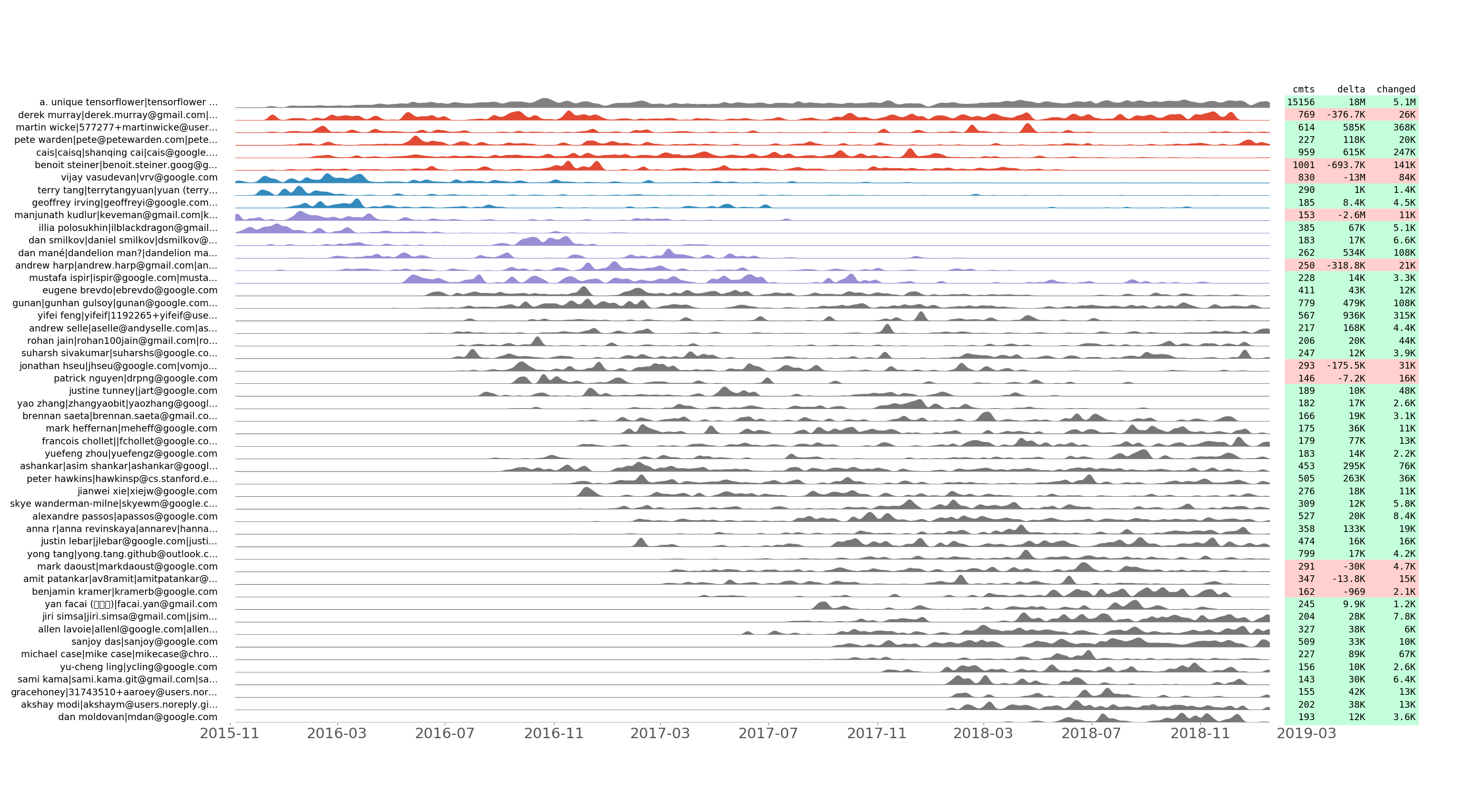
Série de commits alinhados por tensorflow/tensorflow dos 50 principais desenvolvedores por número de commit.
hercules --devs [--people-dict=/path/to/identities]
labours -m devs -o <name>
Registramos quantos commits foram feitos, bem como linhas adicionadas, removidas e alteradas por dia para cada desenvolvedor. Plotamos a série temporal de commit resultante usando alguns truques para mostrar o agrupamento temporal. Em outras palavras, duas séries de commits adjacentes devem parecer semelhantes após a normalização.
Este enredo permite descobrir como a equipe de desenvolvimento evoluiu ao longo do tempo. Também mostra "flashmobs de commit", como o Hacktoberfest. Por exemplo, aqui estão os insights revelados do gráfico tensorflow/tensorflow acima:
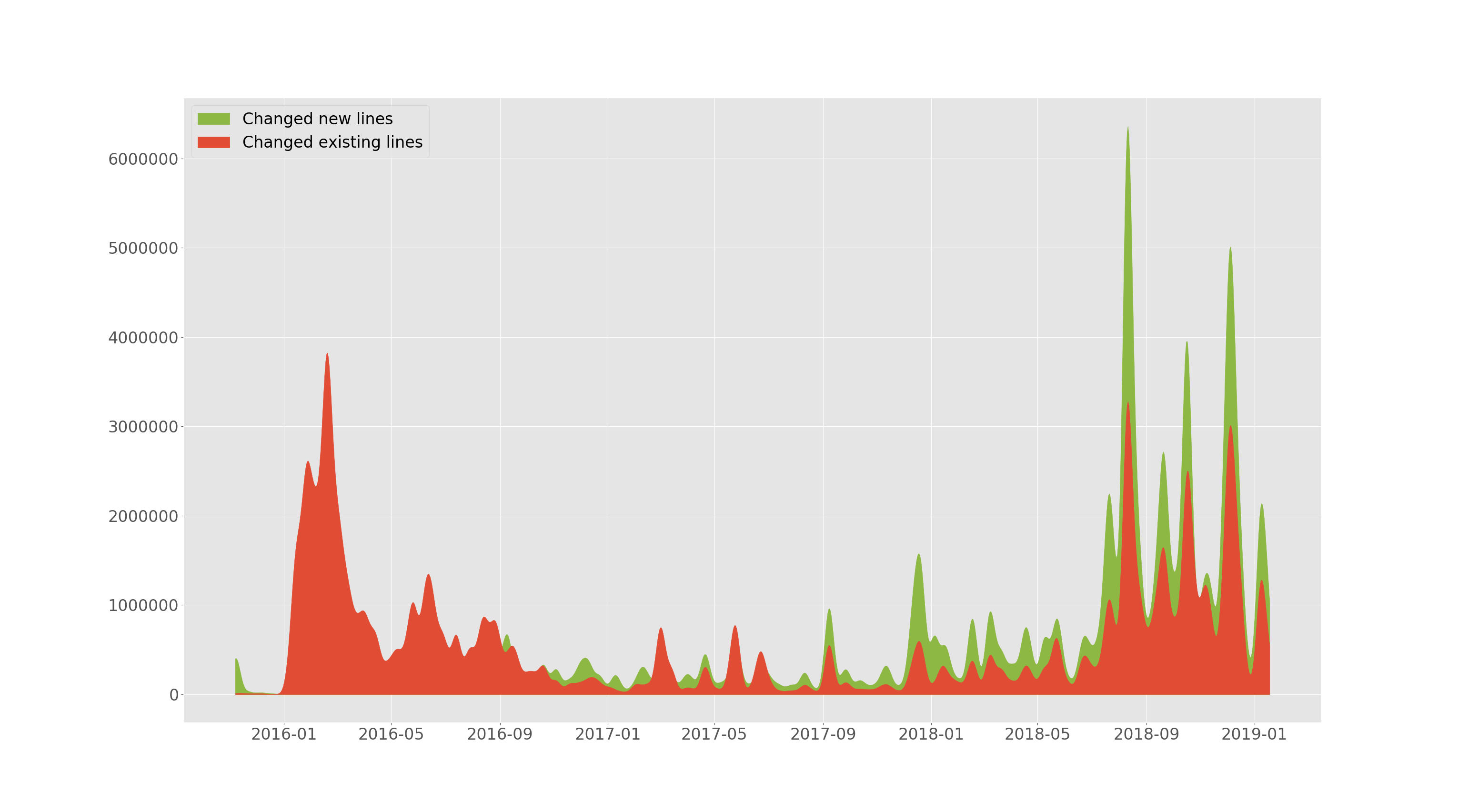
tensorflow/tensorflow adicionou e alterou linhas ao longo do tempo.
hercules --devs [--people-dict=/path/to/identities]
labours -m old-vs-new -o <name>
--devs da seção anterior permite traçar quantas linhas foram adicionadas e quantas existentes foram alteradas (excluídas ou substituídas) ao longo do tempo. Este gráfico é suavizado.
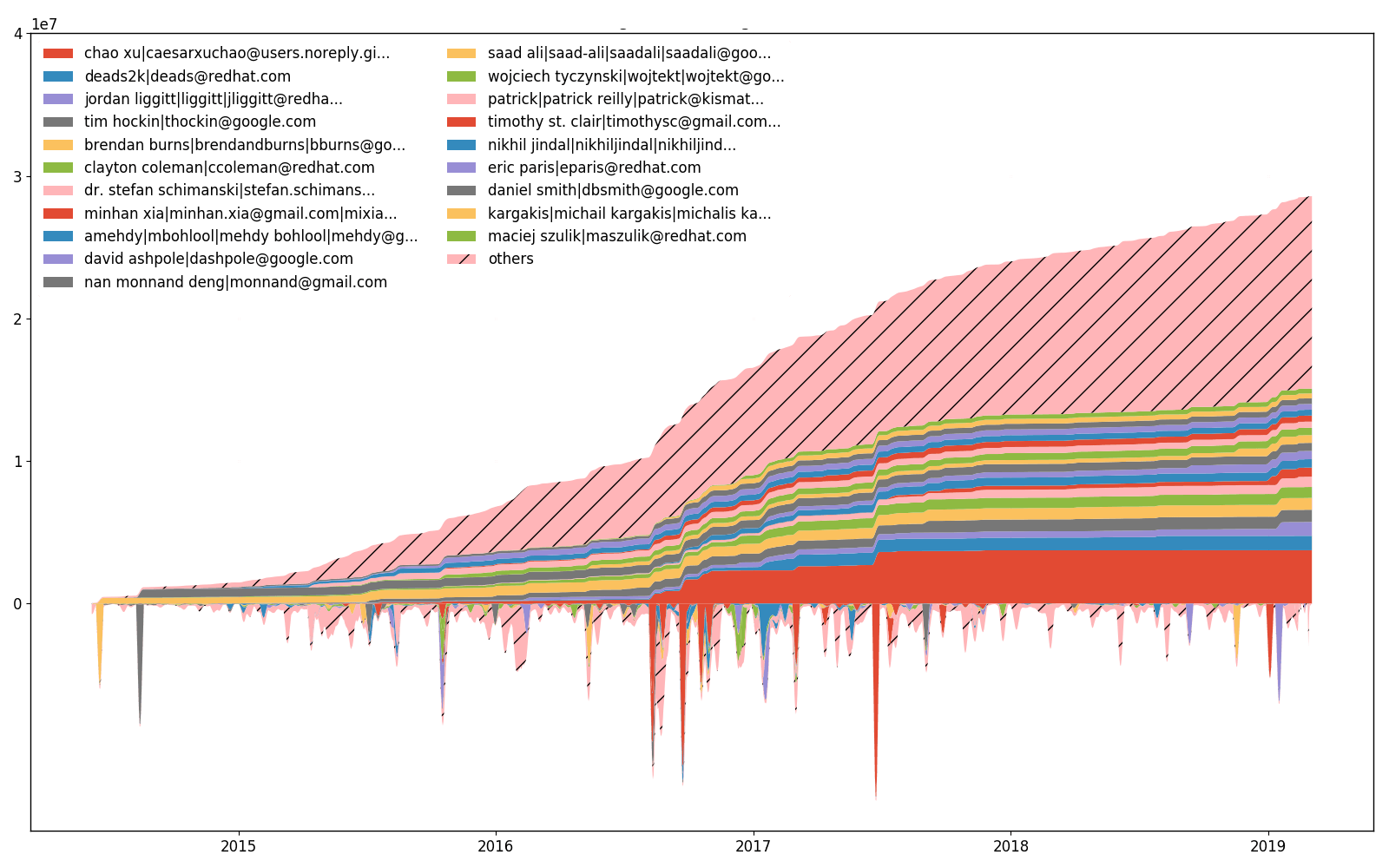
esforços do kubernetes/kubernetes ao longo do tempo.
hercules --devs [--people-dict=/path/to/identities]
labours -m devs-efforts -o <name>
Além disso, --devs permite traçar quantas linhas foram alteradas (adicionadas ou removidas) por cada desenvolvedor. A parte superior da parcela é uma parte inferior acumulada (integrada). É impossível ter a mesma escala para ambas as partes, portanto os valores mais baixos são escalonados e, portanto, não há marcas inferiores no eixo Y. Há uma diferença entre o gráfico de esforços e o gráfico de propriedade, embora a mudança nas linhas esteja correlacionada com as linhas de propriedade.
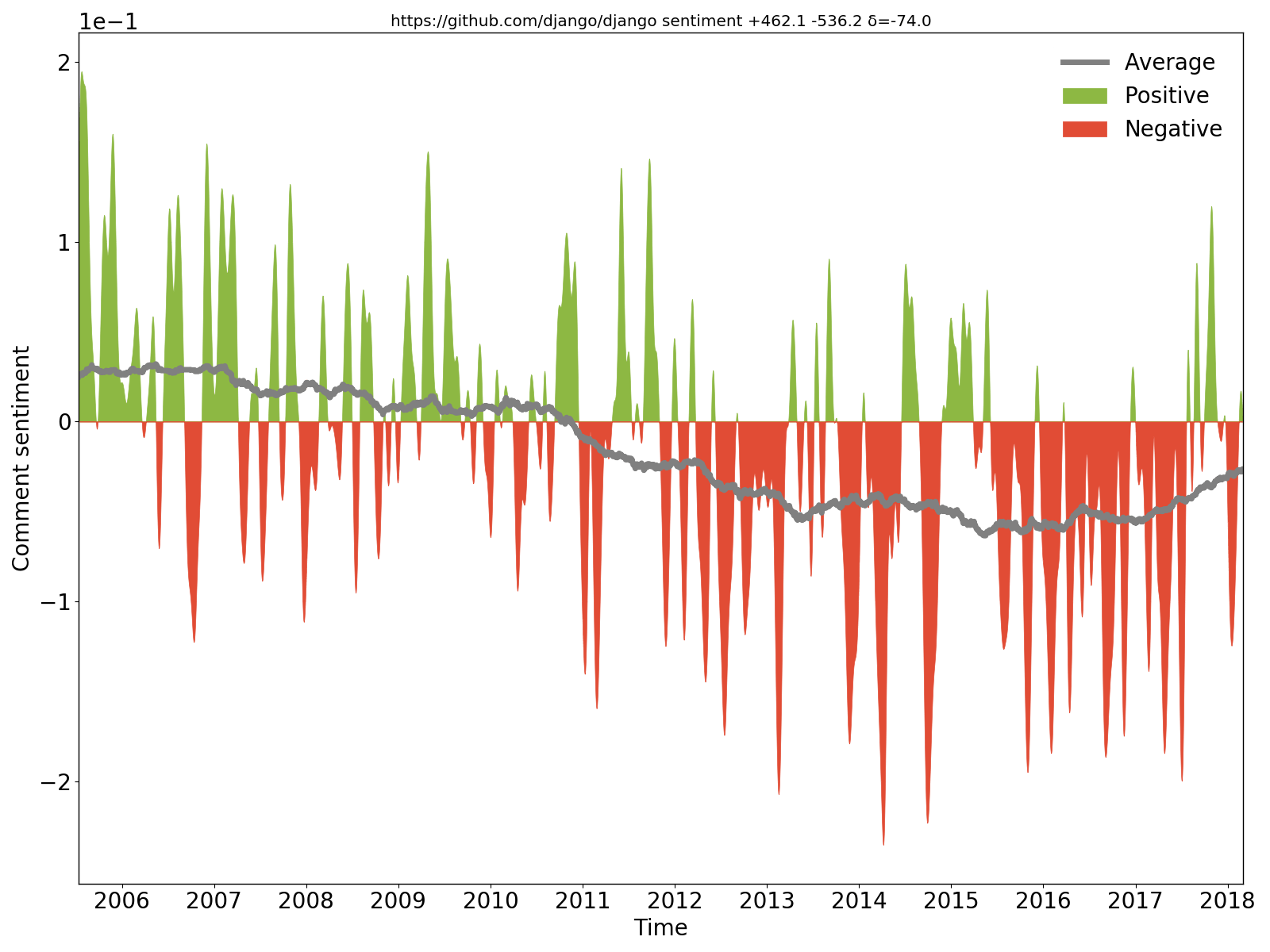
Pode-se ver claramente que os comentários do Django foram positivos/otimistas no início, mas depois tornaram-se negativos/pessimistas.
hercules --sentiment --pb https://github.com/django/django | labours -m sentiment -f pb
Extraímos comentários novos e alterados do código-fonte em cada commit, aplicamos a rede neural recorrente de sentimento de uso geral BiDiSentiment e traçamos os resultados. Requer libtensorflow. Por exemplo sadly, we need to hide the rect from the documentation finder for now é negativo e Theano has a built-in optimization for logsumexp (...) so we can just write the expression directly como positiva. Não espere muito - como foi escrito, o modelo de sentimento é de propósito geral e os comentários do código têm natureza diferente, então não há mágica (por enquanto).
O Hercules deve ser construído com a tag "tensorflow" - não é por padrão:
make TAGS=tensorflow
Tal construção requer libtensorflow .
hercules --burndown --burndown-files --burndown-people --couples --shotness --devs [--people-dict=/path/to/identities]
labours -m all
Hercules possui um sistema de plugins e permite executar análises personalizadas. Consulte PLUGINS.md.
hercules combine é o comando que reúne vários resultados de análises no formato Protocol Buffers.
hercules --burndown --pb https://github.com/go-git/go-git > go-git.pb
hercules --burndown --pb https://github.com/src-d/hercules > hercules.pb
hercules combine go-git.pb hercules.pb | labours -f pb -m burndown-project --resample M
YAML não suporta toda a gama de caracteres Unicode e o analisador do lado labours pode gerar exceções. Filtre a saída do hercules por meio de fix_yaml_unicode.py para descartar esses caracteres ofensivos.
hercules --burndown --burndown-people https://github.com/... | python3 fix_yaml_unicode.py | labours -m people
Estas opções afetam todos os gráficos:
labours [--style=white|black] [--backend=] [--size=Y,X]
--style define o estilo geral do enredo (veja labours --help ). --background altera o fundo do gráfico para branco ou preto. --backend escolhe o back-end do Matplotlib. --size define o tamanho da figura em polegadas. O padrão é 12,9 .
(obrigatório no macOS), você pode fixar o back-end padrão do Matplotlib com
echo "backend: TkAgg" > ~/.matplotlib/matplotlibrc
Estas opções são eficazes apenas em gráficos burndown:
labours [--text-size] [--relative]
--text-size altera o tamanho da fonte, --relative ativa o layout de burndown esticado.
É possível gerar todas as informações necessárias para desenhar os gráficos no formato JSON. Basta anexar .json à saída ( -o ) e pronto. O formato dos dados não está totalmente especificado e depende do código Python que os gera. Cada arquivo JSON deve conter "type" que reflete o tipo de plotagem.
--first-parent como solução alternativa.hercules para o kernel Linux no modo "casais" é de 1,5 GB e leva mais de uma hora/180 GB de RAM para ser analisada. No entanto, a maioria dos repositórios é analisada em um minuto. Tente usar buffers de protocolo ( hercules --pb e labours -f pb ). # Debian, Ubuntu
apt install libyaml-dev
# macOS
brew install yaml-cpp libyaml
# you might need to re-install pyyaml for changes to make effect
pip uninstall pyyaml
pip --no-cache-dir install pyyaml
Se o repositório analisado for grande e usar ramificações extensivamente, a coleta de estatísticas de burndown poderá falhar com um OOM. Você deve tentar o seguinte:
--skip-blacklist para evitar a análise de arquivos indesejados. Também é possível restringir o --language .--hibernation-distance 10 --burndown-hibernation-threshold=1000 . Brinque com esses dois números para começar a hibernar logo antes do OOM.--burndown-hibernation-disk --burndown-hibernation-dir /path .--first-parent , você vence. src-d/go-git para go-git/go-git . Atualize a base de código para ser compatível com a versão mais recente do Go. 

