Uma ferramenta para extensão Thesaurus usando métodos de propagação de rótulos. A partir de um corpus de texto e de um tesauro existente, gera sugestões para ampliar os conjuntos de sinônimos existentes. Esta ferramenta foi desenvolvida durante a Dissertação de Mestrado " Propagação de Rótulos para Extensão de Thesaurus de Direito Tributário " na Cátedra "Engenharia de Software para Sistemas de Informação Empresarial (sebis)", Universidade Técnica de Munique (TUM).
Resumo da Tese. Com o aumento da digitalização, a recuperação de informação tem de lidar com quantidades crescentes de conteúdo digitalizado. Os provedores de conteúdo jurídico investem muito dinheiro na construção de ontologias específicas de domínio, como os tesauros, para recuperar um número significativamente maior de documentos relevantes. Desde 2002, muitos métodos de propagação de rótulos foram desenvolvidos, por exemplo, para identificar grupos de nós semelhantes em grafos. A propagação de rótulos é uma família de algoritmos de aprendizado de máquina semissupervisionados baseados em gráficos. Nesta tese, testaremos a adequação de métodos de propagação de rótulos para estender um tesauro do domínio do direito tributário. O gráfico no qual opera a propagação de rótulos é um gráfico de similaridade construído a partir de incorporações de palavras. Cobrimos o processo de ponta a ponta e conduzimos diversos estudos de parâmetros para entender o impacto de certos hiperparâmetros no desempenho geral. Os resultados são então avaliados em estudos manuais e comparados com uma abordagem de base.
A ferramenta foi implementada usando a seguinte arquitetura de pipes e filtros:
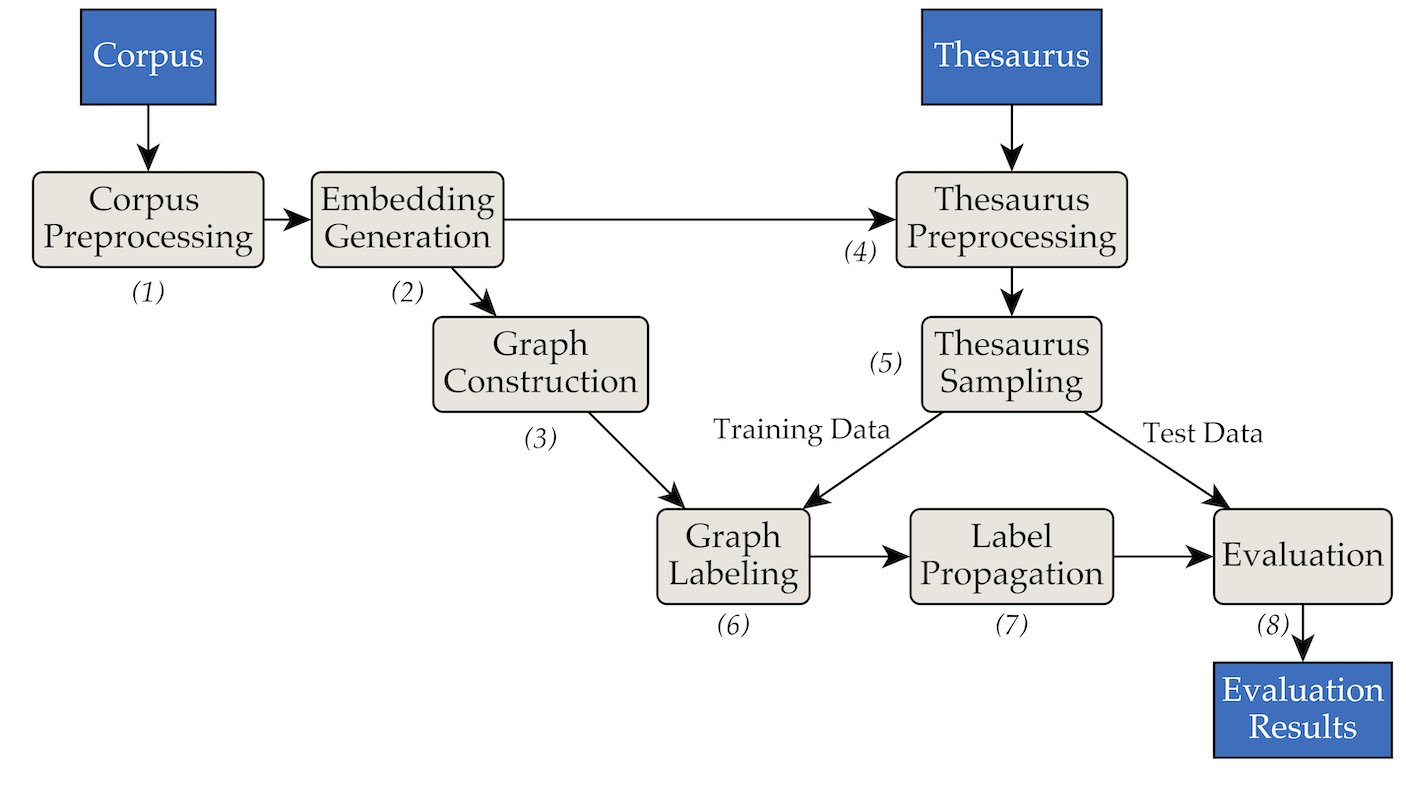
pipenv (Guia de instalação).pipenv install . data/RW40jsons e o dicionário de sinônimos em data/german_relat_pretty-20180605.json . Consulte phase1.py e phase4.py para obter informações sobre os formatos de arquivo esperados.output/<PHASE_FOLDER>/<DATE> . Os mais importantes são 08_propagation_evaluation e XX_runs . Em 08_propagation_evaluation , as estatísticas de avaliação são armazenadas como stats.json junto com uma tabela que contém previsões, treinamento e conjunto de testes ( main.txt , nos outros scripts mais frequentemente referidos como df_evaluation ). Em XX_runs , o log de uma execução é armazenado. Se várias execuções foram acionadas por meio de multi_runs.py (cada uma com um conjunto de treinamento/teste diferente), as estatísticas combinadas de todas as execuções individuais também serão armazenadas como all_stats.json . Via purew2v_parameter_studies.py, a linha de base do vetor synset que introduzimos em nossa tese pode ser executada. Requer um conjunto de incorporações de palavras e uma ou várias divisões de treinamento/teste de dicionário de sinônimos. Consulte sample_commands.md para obter um exemplo.
Em ipynbs , fornecemos alguns notebooks Jupyter exemplares que foram usados para gerar (a) estatísticas, (b) diagramas e (c) arquivos Excel para as avaliações manuais. Você pode explorá-los executando pipenv shell e iniciando o Jupyter com jupyter notebook .
main.py ou multi_run.py .

