Candle é uma estrutura de ML minimalista para Rust com foco no desempenho (incluindo suporte a GPU) e facilidade de uso. Experimente nossas demonstrações online: sussurro, LLaMA2, T5, yolo, Segment Anything.
Certifique-se de ter candle-core instalado corretamente conforme descrito em Instalação .
Vamos ver como executar uma multiplicação de matrizes simples. Escreva o seguinte em seu arquivo myapp/src/main.rs :
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run deve exibir um tensor de forma Tensor[[2, 4], f32] .
Tendo instalado candle com suporte Cuda, basta definir o device para estar na GPU:
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;Para exemplos mais avançados, dê uma olhada na seção a seguir.
Estas demonstrações online são executadas inteiramente no seu navegador:
Também fornecemos alguns exemplos baseados em linha de comando usando modelos de última geração:
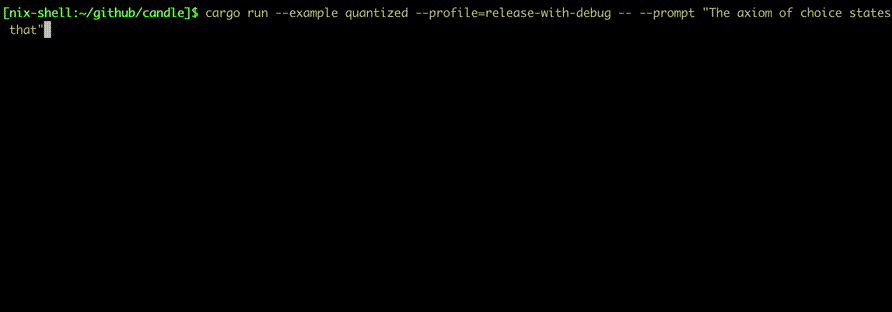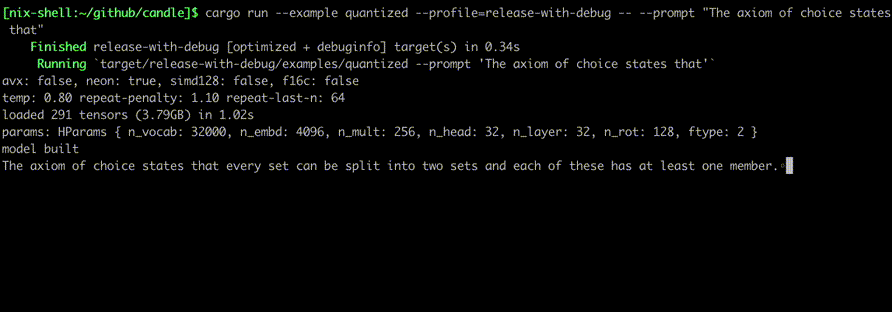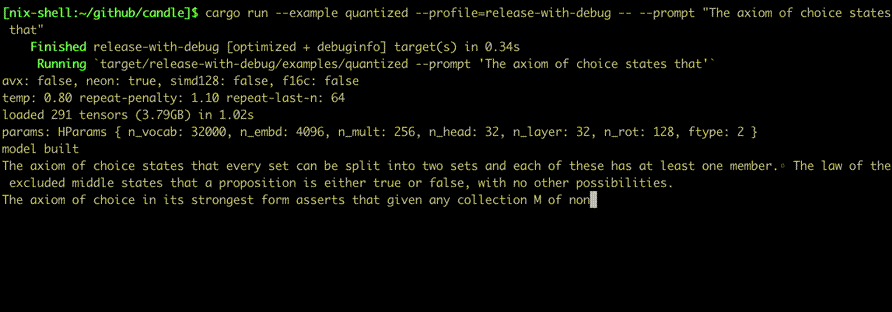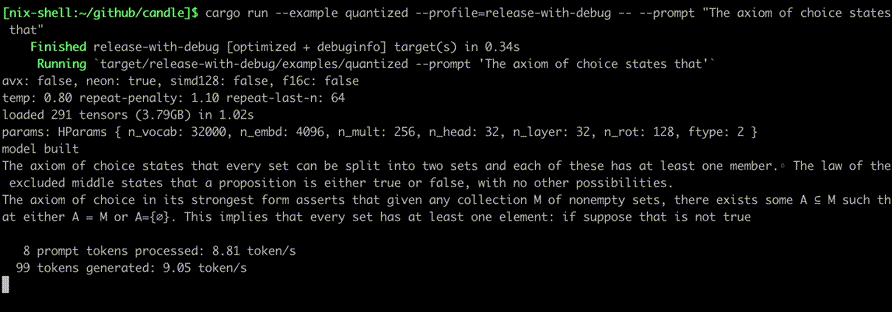





Execute-os usando comandos como:
cargo run --example quantized --release
Para usar CUDA, adicione --features cuda à linha de comando de exemplo. Se você tiver o cuDNN instalado, use --features cudnn para acelerar ainda mais.
Existem também alguns exemplos de wasm para sussurro e llama2.c. Você pode construí-los com trunk ou experimentá-los online: sussurro, llama2, T5, Phi-1.5 e Phi-2, Segment Anything Model.
Para LLaMA2, execute o seguinte comando para recuperar os arquivos de peso e iniciar um servidor de teste:
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081E então vá para http://localhost:8081/.
candle-tutorial : Um tutorial muito detalhado mostrando como converter um modelo PyTorch em Candle.candle-lora : Implementação LoRA eficiente e ergonômica para Candle. candle-lora temoptimisers : uma coleção de otimizadores, incluindo SGD com momentum, AdaGrad, AdaDelta, AdaMax, NAdam, RAdam e RMSprop.candle-vllm : Plataforma eficiente para inferência e atendimento de LLMs locais, incluindo um servidor API compatível com OpenAI.candle-ext : Uma biblioteca de extensão para Candle que fornece funções PyTorch não disponíveis atualmente no Candle.candle-coursera-ml : Implementação de algoritmos de ML do curso de especialização em aprendizado de máquina do Coursera.kalosm : Uma metaestrutura multimodal em Rust para interface com modelos locais pré-treinados com suporte para geração controlada, samplers personalizados, bancos de dados de vetores na memória, transcrição de áudio e muito mais.candle-sampling : Técnicas de amostragem para velas.gpt-from-scratch-rs : Uma versão do tutorial Vamos construir GPT de Andrej Karpathy no YouTube apresentando a API Candle em um problema de brinquedo.candle-einops : Uma implementação de ferrugem pura da biblioteca python einops.atoma-infer : uma biblioteca Rust para inferência rápida em escala, aproveitando FlashAttention2 para computação de atenção eficiente, PagedAttention para gerenciamento eficiente de memória de cache KV e suporte multi-GPU. É compatível com a API OpenAI.Se você tiver uma adição a esta lista, envie uma solicitação pull.
Folha de dicas:
| Usando PyTorch | Usando Vela | |
|---|---|---|
| Criação | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| Criação | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| Indexação | tensor[:, :4] | tensor.i((.., ..4))? |
| Operações | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| Operações | a.matmul(b) | a.matmul(&b)? |
| Aritmética | a + b | &a + &b |
| Dispositivo | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| Tipo D | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| Salvando | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| Carregando | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
TensorO principal objetivo do Candle é tornar possível a inferência sem servidor . Estruturas completas de aprendizado de máquina como PyTorch são muito grandes, o que torna lenta a criação de instâncias em um cluster. Candle permite a implantação de binários leves.
Em segundo lugar, o Candle permite remover o Python das cargas de trabalho de produção. A sobrecarga do Python pode prejudicar seriamente o desempenho, e o GIL é uma fonte notória de dores de cabeça.
Finalmente, Rust é legal! Grande parte do ecossistema HF já possui caixas de ferrugem, como safetensors e tokenizers.
dfdx é uma caixa formidável, com formas incluídas em tipos. Isso evita muitas dores de cabeça, fazendo com que o compilador reclame imediatamente sobre incompatibilidades de forma. No entanto, descobrimos que alguns recursos ainda exigem o uso noturno, e escrever código pode ser um pouco assustador para quem não é especialista em ferrugem.
Estamos aproveitando e contribuindo com outras caixas principais para o tempo de execução, então esperamos que ambas as caixas possam se beneficiar uma da outra.
burn é uma caixa geral que pode aproveitar vários back-ends para que você possa escolher o melhor mecanismo para sua carga de trabalho.
tch-rs Vinculações à biblioteca de tochas no Rust. Extremamente versáteis, mas trazem toda a biblioteca de tochas para o tempo de execução. O principal contribuidor do tch-rs também está envolvido no desenvolvimento do candle .
Se você receber alguns símbolos ausentes ao compilar binários/testes usando os recursos mkl ou acelerar, por exemplo, para mkl você obterá:
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
ou para acelerar:
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
Provavelmente, isso se deve à falta de um sinalizador de vinculador necessário para ativar a biblioteca mkl. Você pode tentar adicionar o seguinte para mkl no topo do seu binário:
extern crate intel_mkl_src ;ou para acelerar:
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
Provavelmente, isso ocorre porque você não tem permissão para o modelo LLaMA-v2. Para corrigir isso, você deve se registrar no huggingface-hub, aceitar as condições do modelo LLaMA-v2 e configurar seu token de autenticação. Consulte a edição nº 350 para obter mais detalhes.
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
cutlass é fornecido como um submódulo git, então você pode querer executar o seguinte comando para fazer o check-in corretamente.
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
Este é um bug no gcc-11 acionado pelo compilador Cuda. Para corrigir isso, instale uma versão diferente e compatível do gcc - por exemplo, gcc-10, e especifique o caminho para o compilador na variável de ambiente NVCC_CCBIN.
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
Certifique-se de vincular todas as bibliotecas nativas que possam estar localizadas fora do destino do projeto, por exemplo, para executar testes de mdbook, você deve executar:
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
Isso pode ser causado pelo carregamento dos modelos de /mnt/c , mais detalhes no stackoverflow.
Você pode definir RUST_BACKTRACE=1 para receber backtraces quando um erro de vela for gerado.
Se você encontrar um erro como este called Result::unwrap() on an value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } no Windows. Para corrigir, copie e renomeie esses 3 arquivos (certifique-se de que estejam no caminho). Os caminhos dependem da sua versão cuda. c:WindowsSystem32nvcuda.dll -> cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll -> cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


